
Torch7學習(四)——學習神經網路包的用法(2)
總說
上篇部落格已經初步介紹了Module類。這裡將更加仔細的介紹。並且還將介紹Container, Transfer Functions Layers和 Simple Layers模組。
Module
主要有4個函式。
1. [output]forward(input)
2. [gradInput] backward (input.gradOutput)
以及在後面自動擋訓練方式中過載的兩個函式
3. [output] updateOutput (input)
4. [gradInput] updateGradInput (input, gradOutput)
注意點:
1. forward函式的input必須和backward的函式的input一致!否則梯度更新會有問題。
2. Module的forward會呼叫updateOutput(input), 而backward會呼叫[gradInput] updateGradInput (input, gradOutput)和accGradParameters(input, gradOutput)
3. 高階訓練方式只要過載updateOutput和updateGradInput這兩個函式,內部引數會自動改變。
4. 對於第3點,需要更加深入的探討
Container
複雜的神經網路可以用container類進行構建。
container的子類主要有三個:Sequential, Parallel, Concat 。他重新實現了Module類的方法。此外還增加了很多方法。
主要函式:
1. add(module)
2. get(index)
3. size() return the number of contained modules.
4. remove(index)
5. insert (module, [index] ) 注意這裡的index是插入後,其排到的index
用法就是,一般是用一個Sequential,然後不斷add(module),而module有simple layers和卷積層。在後面進行說明。
Transfer Functions Layers
就是啟用函式,在第上一篇部落格已經說明了,torch中講神經網路看成是module(或是container)的組合。你可以加入層模組,或是啟用函式的層模組,最後還可以加上criterion層模組。如此一來,整個網路就構建好了。
這個沒啥好說的。
裡面有挺多啟用函式的. SoftMax, SoftMin, SoftPlus, LogSigmoid, LogSoftMax, Sigmoid, Tanh, ReLU, PReLU, ELU, LeakyReLU等等。
這裡就拿Tanh舉例吧。
ii=torch.linspace(-3 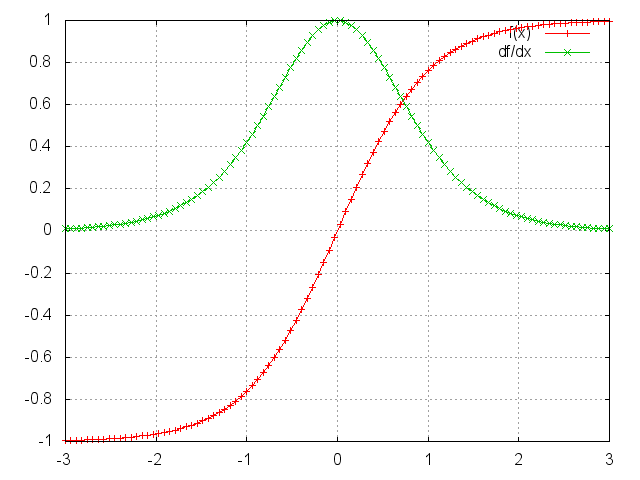
Simple Layers
簡單層有很多,一些是提供仿射變換的,一些是進行Tensor method的。
- 具有引數的modules有:
Linear
Add : 對輸入增加一個偏置項
Mul
CMul
等等 - 進行基本Tensor運算的
View
Transpose
等等 - 進行數學運算的
Max, Min, Exp, Mean, Log, Abs, MM:matrix-matrix multiplication.
Normalize: normalize the input to have unit L-p norm - 其他
Identity
Dropout
下面調重要常見的幾個
Linear
module = nn.Linear(inputDim, outputDim, [bias = true])Linear就是全連線唄。
module = nn.Linear(10,5)
mlp = nn.Sequential()
mlp:add(module)
print(module.weight)
print(module.bias)
print(module.gradWeight)
print(module.gradBias)
x = torch.Tensor(10) -- 10 inputs
y = module:forward(x)執行後發現,只要初始化後網路,裡面就有初始權值和偏置。但是gradBias和gradGradient不是很大就是很小,顯然這是垃圾資料。現在有個問題,網路權值的初始化對整個網路的訓練非常重要,torch是怎樣自定義初始化權值的呢?我現在還沒發現!先做個標記!
Dropout
module = nn.Dropout(p)module = nn.Dropout()
> x = torch.Tensor{{1, 2, 3, 4}, {5, 6, 7, 8}}
> module:forward(x)
2 0 0 8
10 0 14 0
[torch.DoubleTensor of dimension 2x4]
> module:forward(x)
0 0 6 0
10 0 0 0
[torch.DoubleTensor of dimension 2x4]可以看出,上面一些值被丟棄。
View
這個主要是改變網路輸出的tensor的sizes,就是reshape一下。
module = nn.View(sizes)如果是用view(-1)則可特別地用作minibatch的輸入。
x = torch.Tensor(4, 4)
for i = 1, 4 do
for j = 1, 4 do
x[i][j] = (i-1)*4+j
end
end
print(nn.View(2, 8):forward(x))
--[[
1 2 3 4 5 6 7 8
9 10 11 12 13 14 15 16
]]作為minibatch的輸入!
> input = torch.Tensor(2, 3)
> minibatch = torch.Tensor(5, 2, 3)
> m = nn.View(-1):setNumInputDims(2)
> print(#m:forward(minibatch))
5
6
[torch.LongStorage of size 2] --每一行就是一個example的結果。Normalize
module = nn.Normalize(p, [eps])L-p正規化進行歸一化,eps預設是1e-10,防止輸入全為0時除0的情況。
MM
module = nn.MM(transA,transB)transA/transB 為true時,則對應的矩陣進行轉置。
如果是3維矩陣,則第一維被理解成batches的num,轉置只會對後面的兩維進行。
module = nn.MM(true, false)
A = torch.randn(b,n,m)
B = torch.randn(b,n,p)
c = module:forward({A, B})
--[[
c是 b * m * p的
]]簡單層一個常見的Module是Add,放在下篇部落格講。因為會用簡單層的Add模組講手動擋訓練演示。