利用無引數的K近鄰分類器KNeighborsClassifier進行三類分類(複習4)
阿新 • • 發佈:2018-12-31
本文是個人學習筆記,內容主要涉及KNN(KNeighborsClassifier)對sklearn內建的Iris資料集進行三類分類。
K近鄰模型的大致決策方式如下圖:
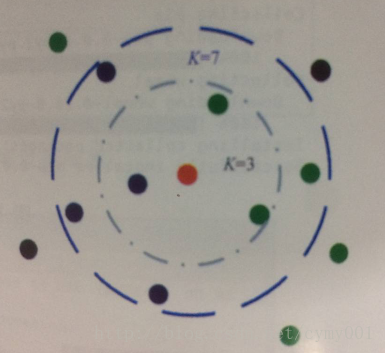
尋找與某個待分類樣本在特徵空間中距離最近的K個已標記樣本作為參考,進而幫助做出分類決策。K取不同的值,會得到不同效果的分類器(比如上如K=3時紅色點被分為綠色類,K=7時紅色點被分為藍色類)。
K近鄰演算法沒有引數訓練過程,即沒有通過任何學習演算法分析訓練資料,只是根據測試樣本在訓練資料的分佈直接做出分類決策,因此K近鄰屬於無引數模型,該模型的計算複雜度(平方級)和記憶體消耗非常高。該模型每處理一個測試樣本,都需要對所有預先載入在內村的訓練樣本進行遍歷,逐一計算相似度、排序並且選取K個最近鄰訓練樣本的標記 ,進而做出分類決策。
from sklearn.datasets import load_iris
iris=load_iris()
iris.data.shape
#Output:(150,4)print(iris.DESCR) #檢視資料說明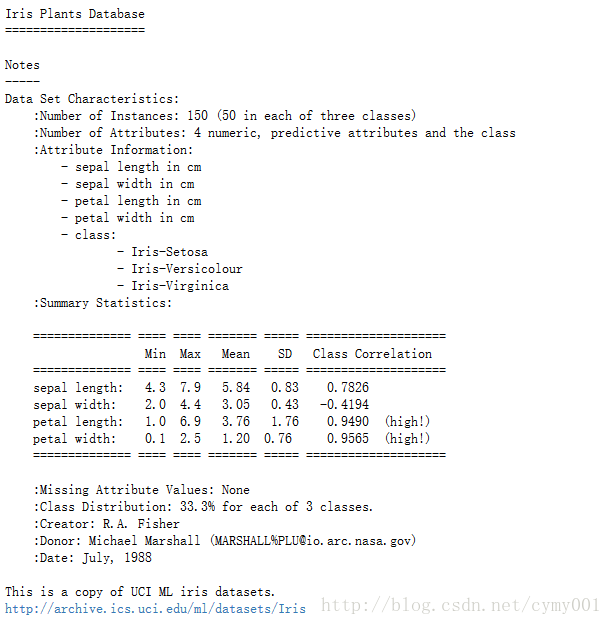

from distutils.version import LooseVersion as Version
from sklearn import __version__ as sklearn_version
from sklearn import datasets
if Version(sklearn_version) < '0.18' from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import from sklearn.metrics import classification_report
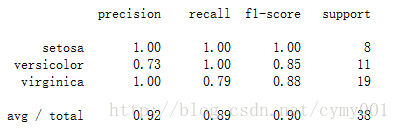
print(classification_report(y_test,y_predict,target_names=iris.target_names))