
K近鄰分類器(KNN)手寫數字(MNIST)識別
阿新 • • 發佈:2019-01-04
KNN(K-Nearest-Neighbor) 是分類演算法中比較簡單的一個演算法。演算法思想非常簡單:對於一個未知類別的樣例,我們在很多已知類別的樣本中找出跟它最相近的K個樣本,賦予該樣例這K個樣本中佔多數的類別。
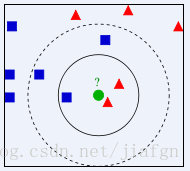
如圖中所示,如果我們選取K值為3,則將樣本分類為三角形的類別。而如果K為5,則將樣本分類為正方形的類別。這裡也可以看出K值的選取很關鍵。
這裡呢,我將用KNN做手寫體數字的識別。另人驚異的是,用如此簡單的演算法也可以獲得超過94%的識別準確率。
首先我先介紹一下我用的資料集MNIST,我有的是10500條已經標好類別的樣本,我用其中500條做測試樣例,用剩下10000條做訓練集。其中每一個樣本784 位0、1 加上一位類別組成,784位0/1 可以組成28*28的二值圖。


下面是計算兩個樣例之間距離的公式,這也是最基本的歐式距離。

public static double calDistance(int[] a, int[] b) {
double temp = 0;
for (int x = 0; x < a.length; x++) {
temp += (a[x] - b[x]) * (a[x] - b[x]);
}
return temp = Math.sqrt(temp);
}下面給出分類程式碼,這裡我的程式是讀入測試樣例,然後逐條計算它與訓練樣本的距離,找出K個最接近的樣本,統計K箇中出現最多的類標賦予給測試樣例。如果要用這個程式碼的話需要稍微改一改,用的程式語言都是Java
public static int classify(String filename, int[] a) throws IOException {
FileReader fr = new FileReader(filename);
BufferedReader bufr = new BufferedReader(fr);
double[] d = new double[K];//存放K近鄰的距離
for (int x = 0; x < K; x++) {//先將所有K近鄰的距離初始化為最大距離28
d[x] = 28 進一步的改進
關於KNN的改進有以下幾個方面:
- 加權重,這裡的原理是距離測試樣本最近的訓練樣本有比較高的權重。一般權重公式可以為距離的倒數。
- 換距離公式,可以換成cos距離
- 去除不重要的特徵減少計算量;採用特殊的資料結構排序訓練樣本如kd-tree,減少計算距離次數。
資料集與整個專案的原始碼我都已經上傳,點選下載。值得注意的是,在我的專案裡面已經實現了漢明距離與cos距離兩種不同距離衡量方法。有任何問題歡迎討教