
決策樹--資訊增益,資訊增益比,Geni指數的理解
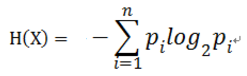
對於樣本集合D來說,隨機變數X是樣本的類別,即,假設樣本有k個類別,每個類別的概率是![]() ,其中|Ck|表示類別k的樣本個數,|D|表示樣本總數
,其中|Ck|表示類別k的樣本個數,|D|表示樣本總數
則對於樣本集合D來說熵(經驗熵)
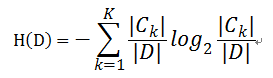
- 資訊增益( ID3演算法 )
定義: 以某特徵劃分資料集前後的熵的差值
在熵的理解那部分提到了,熵可以表示樣本集合的不確定性,熵越大,樣本的不確定性就越大。因此可以使用劃分前後集合熵的差值來衡量使用當前特徵對於樣本集合D劃分效果的好壞。
劃分前樣本集合D的熵是一定的 ,entroy(前), 使用某個特徵A劃分資料集D,計算劃分後的資料子集的熵 entroy(後) 資訊增益 = entroy(前) - entroy(後) 書中公式:- 解決方法 : 資訊增益比( C4.5演算法 )
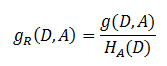 注意:其中的HA(D),對於樣本集合D,將當前特徵A作為隨機變數(取值是特徵A的各個特徵值),求得的經驗熵。
(之前是把集合類別作為隨機變數,現在把某個特徵作為隨機變數,按照此特徵的特徵取值對集合D進行劃分,計算熵HA(D))
注意:其中的HA(D),對於樣本集合D,將當前特徵A作為隨機變數(取值是特徵A的各個特徵值),求得的經驗熵。
(之前是把集合類別作為隨機變數,現在把某個特徵作為隨機變數,按照此特徵的特徵取值對集合D進行劃分,計算熵HA(D))
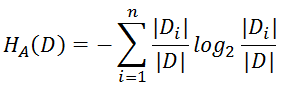 資訊增益比本質: 是在資訊增益的基礎之上乘上一個懲罰引數。特徵個數較多時,懲罰引數較小;特徵個數較少時,懲罰引數較大。
懲罰引數:資料集D以特徵A作為隨機變數的熵的倒數,即:將特徵A取值相同的樣本劃分到同一個子集中(之前所說資料集的熵是依據類別進行劃分的)
資訊增益比本質: 是在資訊增益的基礎之上乘上一個懲罰引數。特徵個數較多時,懲罰引數較小;特徵個數較少時,懲罰引數較大。
懲罰引數:資料集D以特徵A作為隨機變數的熵的倒數,即:將特徵A取值相同的樣本劃分到同一個子集中(之前所說資料集的熵是依據類別進行劃分的)
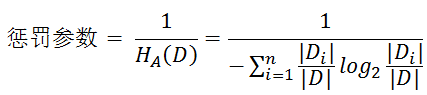 缺點:資訊增益比偏向取值較少的特徵
原因: 當特徵取值較少時HA(D)的值較小,因此其倒數較大,因而資訊增益比較大。因而偏向取值較少的特徵。
使用資訊增益比:基於以上缺點,並不是直接選擇資訊增益率最大的特徵,而是現在候選特徵中找出資訊增益高於平均水平的特徵,然後在這些特徵中再選擇資訊增益率最高的特徵。
缺點:資訊增益比偏向取值較少的特徵
原因: 當特徵取值較少時HA(D)的值較小,因此其倒數較大,因而資訊增益比較大。因而偏向取值較少的特徵。
使用資訊增益比:基於以上缺點,並不是直接選擇資訊增益率最大的特徵,而是現在候選特徵中找出資訊增益高於平均水平的特徵,然後在這些特徵中再選擇資訊增益率最高的特徵。
- 基尼指數( CART演算法 ---分類樹)
定義:基尼指數(基尼不純度):表示在樣本集合中一個隨機選中的樣本被分錯的概率。
注意: Gini指數越小表示集合中被選中的樣本被分錯的概率越小,也就是說集合的純度越高,反之,集合越不純。
即 基尼指數(基尼不純度)= 樣本被選中的概率 * 樣本被分錯的概率
書中公式:
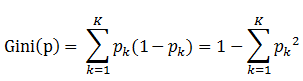
說明:
1. pk表示選中的樣本屬於k類別的概率,則這個樣本被分錯的概率是(1-pk)
2. 樣本集合中有K個類別,一個隨機選中的樣本可以屬於這k個類別中的任意一個,因而對類別就加和
3. 當為二分類是,Gini(P) = 2p(1-p)
樣本集合D的Gini指數 : 假設集合中有K個類別,則:
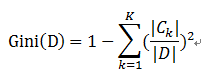
基於特徵A劃分樣本集合D之後的基尼指數:
需要說明的是CART是個二叉樹,也就是當使用某個特徵劃分樣本集合只有兩個集合:1. 等於給定的特徵值 的樣本集合D1 , 2 不等於給定的特徵值 的樣本集合D2
實際上是對擁有多個取值的特徵的二值處理。
舉個例子:
假設現在有特徵 “學歷”,此特徵有三個特徵取值: “本科”,“碩士”, “博士”,
當使用“學歷”這個特徵對樣本集合D進行劃分時,劃分值分別有三個,因而有三種劃分的可能集合,劃分後的子集如下:
- 劃分點: “本科”,劃分後的子集合 : {本科},{碩士,博士}
- 劃分點: “碩士”,劃分後的子集合 : {碩士},{本科,博士}
- 劃分點: “碩士”,劃分後的子集合 : {博士},{本科,碩士}
對於上述的每一種劃分,都可以計算出基於 劃分特徵= 某個特徵值 將樣本集合D劃分為兩個子集的純度:
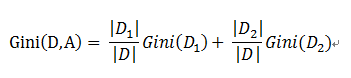
因而對於一個具有多個取值(超過2個)的特徵,需要計算以每一個取值作為劃分點,對樣本D劃分之後子集的純度Gini(D,Ai),(其中Ai 表示特徵A的可能取值)
然後從所有的可能劃分的Gini(D,Ai)中找出Gini指數最小的劃分,這個劃分的劃分點,便是使用特徵A對樣本集合D進行劃分的最佳劃分點。