
流式實時分散式計算的設計
https://blog.csdn.net/anzhsoft/article/details/38168025
1. 流式計算的背景和特點
現在很多公司每天都會產生數以TB級的大資料,如何對這些資料進行挖掘,分析成了很重要的課題。比如:
電子商務:需要處理並且挖掘使用者行為產生的資料,產生推薦,從而帶來更多的流量和收益。最理想的推薦就是根據興趣推薦給使用者本來不需要的東西!而每天處理海量的使用者資料,需要一個低延時高可靠的實時流式分散式計算系統。
新聞聚合:新聞時效性非常重要,如果在一個重大事情發生後能夠實時的推薦給使用者,那麼肯定能增大使用者粘性,帶來可觀的流量。
社交網站:大家每天都會去社交網站是為了看看現在發生了什麼,周圍人在做什麼。流式計算可以把使用者關注的熱點聚合,實時反饋給使用者,從而達到一個圈子的聚合效果。
交通監管部門:每個城市的交通監管部門每天都要產生海量的視訊資料,這些視訊資料也是以流的形式源源不斷的輸系統中。實時流式計算系統需要以最快的速度來處理這些資料。
資料探勘和機器學習:它們實際上是網際網路公司內部使用的系統,主要為線上服務提供資料支撐。它們可以說是網際網路公司的最核心的平臺之一。系統的效率是挖掘的關鍵,理想條件下就是每天產生的海量資料都能得到有效處理,對於原來的資料進行全量更新。
大型叢集的監控:自動化運維很重要,叢集監控的實時預警機制也非常重要,而流式系統對於日誌的實時處理,往往是監控系統的關鍵。
等等。
流式實時分散式計算系統就是要解決上述問題的。這些系統的共同特徵是什麼?
非常方便的執行使用者編寫的計算邏輯:就如Hadoop定義了Map和Reduce的原語一樣,這些系統也需要讓使用者關注與資料處理的具體邏輯上,他們不應該也不需要去了解這些usder defined codes是如何在分散式系統上運轉起來的。因為他們僅僅關注與資料處理的邏輯,因此可以極大的提高效率。而且應該儘量不要限制程式語言,畢竟不同的公司甚至同一公司的不同部門使用的語言可能是千差萬別的。支援多語言無疑可以搶佔更多的使用者。
Scale-out的設計:分散式系統天生就是scale-out的。
無資料丟失:系統需要保證無資料丟失,這也是系統高可用性的保證。系統為了無資料丟失,需要在資料處理失敗的時候選擇另外的執行路徑進行replay(系統不是簡單的重新提交運算,而是重新執行排程,否則按照來源的call stack有可能使得系統永遠都在相同的地方出同樣的錯誤)。
容錯透明:使用者不會也不需要關心容錯。系統會自動處理容錯,排程並且管理資源,而這些行為對於運行於其上的應用來說都是透明的。
資料持久化:為了保證高可用性和無資料丟失,資料持久化是無法躲避的問題。的確,資料持久化可能在低延時的系統中比較影響效能,但是這無法避免。當然了,如果考慮到出錯情況比較少,在出錯的時候我們能夠忍受資料可以從頭replay,那麼中間的運算可以不進行持久化。注意,這隻有在持久化的成本要比計算的replay高的情況下有效。一般來說,計算的結果需要replica,當然了,可以使用將資料replica到其他的節點的記憶體中去(這又會佔用叢集的網路頻寬)。
超時設定:超時之所以在在這裡被提出來,因為超時時間的大小設定需要重視,如果太短可以會誤殺正常執行的計算,如果太長則不能快速的檢測錯誤。還有就是對於錯誤的快速發現可以這類系統的一個設計要點,畢竟,超時了才發現錯誤很多時候在時效性上是不可接受的。
2. 原語設計
Hadoop定義了Map和Reduce,使得應用者只需要實現MR就可以實現資料處理。而流式系統的特點,允許它們可以進行更加具體一些的原語設計。流式的資料的特點就是資料時源源不斷進入系統的,而這些資料的處理一般都需要幾個階段。拿普通的日誌處理來說,我們可能僅僅關注Error的日誌,那麼系統的第一個計算邏輯就是進行filer。接下來可能需要對這個日誌進行分段,分段後可能交給不同的規則處理器進行處理。因此,資料處理一般是分階段的,可以說是一個有向無環圖,或者說是一個拓撲。實際上,Spark抽象出的運算邏輯就是由RDD(Resilient Distributed Dataset)構成DAG(Directed Acyclic Graph),而Storm則有Spout和Blot構成Topology(拓撲)。
2.1 Spark的設計
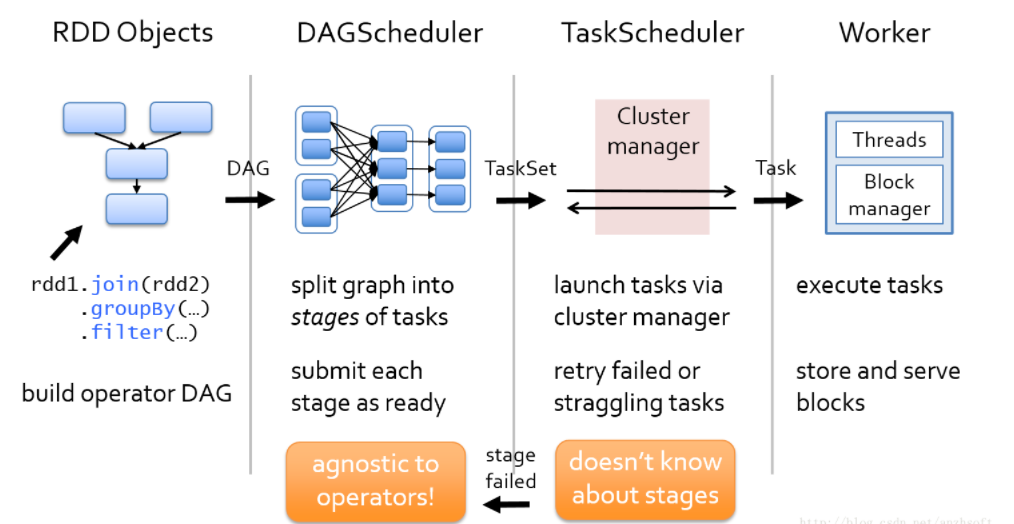
Spark Streaming是將流式計算分解成一系列短小的批處理作業。這裡的批處理引擎是Spark,也就是把Spark Streaming的輸入資料按照batch size(如1秒)分成一段一段的資料,每一段資料都轉換成Spark中的RDD,然後將Spark Streaming中對DStream的Transformation操作變為針對Spark中對RDD的Transformation操作,將RDD經過操作變成中間結果儲存在記憶體中。整個流式計算根據業務的需求可以對中間的結果進行疊加,或者儲存到外部裝置。下圖顯示了Spark Streaming的整個流程。
WordCount的例子:
// Create the context and set up a network input stream to receive from a host:port
val ssc = new StreamingContext(args(0), "NetworkWordCount", Seconds(1))
val lines = ssc.socketTextStream(args(1), args(2).toInt)
// Split the lines into words, count them, and print some of the counts on the master
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
// Start the computation
ssc.start()
這個例子使用Scala寫的,一個簡單優雅的函數語言程式設計語言,同時也是基於JVM的後Java類語言。
2.2 Storm的設計
Storm將計算邏輯成為Topology,其中Spout是Topology的資料來源,這個資料來源可能是檔案系統的某個日誌,也可能是MessageQueue的某個訊息佇列,也有可能是資料庫的某個表等等;Bolt負責資料的護理。Bolt有可能由另外兩個Bolt的join而來。
而Storm最核心的抽象Streaming就是連線Spout,Bolt以及Bolt與Bolt之間的資料流。而資料流的組成單位就是Tuple(元組),這個Tuple可能由多個Fields構成,每個Field的含義都在Bolt的定義的時候制定。也就是說,對於一個Bolt來說,Tuple的格式是定義好的。
2.3 原語設計的要點
流式系統的原語設計,要關注一下幾點:
如何定義計算拓撲:要方便演算法開發者開發演算法與策略。最好的實現是定義一個演算法與框架的互動方式,定義好演算法的輸入結構和演算法的輸出結構。然後拓撲能夠組合不同的演算法來為使用者提供一個統一的服務。計算平臺最大的意義在於演算法開發者不需要了解程式的執行,併發的處理,高可用性的實現,只需要提供演算法與計算邏輯即可以快速可靠的處理海量的資料。
拓撲的載入與啟動:對於每個節點來說,啟動時需要載入拓撲,節點需要其他的資訊,比如上游的資料來源與下游的資料輸出。當然了下游的資料輸出的拓撲資訊可以儲存到Tuple中,對於資料需要放到那裡去拓撲本身是無狀態的。這就取決於具體的設計了。
拓撲的線上更新:對於每個演算法邏輯來說,更新是不可避免的,如何在不停止服務的情況下進行更新是必要的。由於實現了架構與演算法的剝離,因此演算法可以以一個單獨的個體進行更新。可以操作如下:Master將演算法實體儲存到一個Worker可見的地方,比如HDFS或者是NFS或者ZK,然後通過心跳傳送命令到拓撲,拓撲會暫時停止處理資料而載入新的演算法實體,載入之後重新開始處理資料。資料一般都會放到buffer中,這個buffer可能是一個queue。但是從外界看來,拓撲實際上是一直處於服務狀態的。
資料如何流動:流式系統最重要的抽象就是Streaming了。那麼Steaming如何流動?實際上涉及到訊息的傳遞和分發,資料如何從一個節點傳遞到另外一個節點,這是拓撲定義的,具體實現可以參照第三小節。
計算的終點及結果處理:流式計算的特點就是計算一直在進行,流是源源不斷的流入到系統中的。但是對於每個資料單位來說它的處理結果是確定的,這個結果一般是需要返回呼叫者或者需要持久化的。比如處理一個時間段的交通違章,那麼輸入的資料是一段時間的視訊監控,輸出這是違章的資訊,比如車牌,還有違章時刻的抓拍的圖片。這個資料要麼返回呼叫者,由呼叫者負責資料的處理,包括持久化等。或者是拓撲最後的節點將這些資訊進行持久化。系統需要對這些常見的case進行指導性的說明,需要在Programmer Guide的sample中給出使用例子。
3. 訊息傳遞和分發
對於實現的邏輯來說,它們都是有向無環圖的一個節點,那麼如何設計它們之間的訊息傳遞呢?或者說資料如何流動的?因為對於分散式系統來說,我們不能假定整個運算都是在同一個節點上(事實上,對於閉源軟體來說,這是可以的,比如就是滿足一個特定運算下的計算,計算平臺也不需要做的那麼通用,那麼對於一個運算邏輯讓他在一個節點完成也是可以了,畢竟節省了排程和網路傳輸的開銷)。或者說,對於一個通用的計算平臺來說,我們不能假定任何事情。
訊息傳遞和分發是取決於系統的具體實現的。通過對比Storm和Spark,你就明白我為什麼這麼說了。
3.1 Spark的訊息傳遞
對於Spark來說,資料流是在通過將使用者定義的一系列的RDD轉化成DAG圖,然後DAG Scheduler把這個DAG轉化成一個TaskSet,而這個TaskSet就可以向叢集申請計算資源,叢集把這個TaskSet部署到Worker中去運算了。當然了,對於開發者來說,他的任務是定義一些RDD,在RDD上做相應的轉化動作,最後系統會將這一系列的RDD投放到Spark的叢集中去執行。
3.2 Storm的訊息傳遞
對於Storm來說,他的訊息分發機制是在定義Topology的時候就顯式定義好的。也就是說,應用程式的開發者需要清楚的定義各個Bolts之間的關係,下游的Bolt是以什麼樣的方式獲取上游的Bolt發出的Tuple。Storm有六種訊息分發模式:
Shuffle Grouping: 隨機分組,Storm會盡量把資料平均分發到下游Bolt中。
Fields Grouping:按欄位分組, 比如按userid來分組, 具有同樣userid的tuple會被分到相同的Bolt。這個對於類似於WordCount這種應用非常有幫助。
All Grouping: 廣播, 對於每一個Tuple, 所有的Bolts都會收到。這種分發模式要慎用,會造成資源的極大浪費。
Global Grouping: 全域性分組, 這個Tuple被分配到storm中的一個bolt的其中一個task。這個對於實現事務性的Topology非常有用。
Non Grouping: 不分組, 這個分組的意思是說stream不關心到底誰會收到它的tuple。目前這種分組和Shuffle grouping是一樣的效果, 有一點不同的是storm會把這個bolt放到這個bolt的訂閱者同一個執行緒裡面去執行。
Direct Grouping: 直接分組, 這是一種比較特別的分組方法,用這種分組意味著訊息的傳送者指定由訊息接收者的哪個task處理這個訊息。
3.3 訊息傳遞要點
訊息佇列現在是模組之間通訊的非常通用的解決方案了。訊息佇列使得程序間的通訊可以跨越物理機,這對於分散式系統尤為重要,畢竟我們不能假定程序究竟是部署在同一臺物理機上還是部署到不同的物理機上。RabbitMQ是應用比較廣泛的MQ,關於RabbitMQ可以看我的一個專欄:RabbitMQ
提到MQ,不得不提的是ZeroMQ。ZeroMQ封裝了Socket,引用官方的說法: “ZMQ (以下 ZeroMQ 簡稱 ZMQ)是一個簡單好用的傳輸層,像框架一樣的一個 socket library,他使得 Socket 程式設計更加簡單、簡潔和效能更高。是一個訊息處理佇列庫,可在多個執行緒、核心和主機盒之間彈性伸縮。ZMQ 的明確目標是“成為標準網路協議棧的一部分,之後進入 Linux 核心”。現在還未看到它們的成功。但是,它無疑是極具前景的、並且是人們更加需要的“傳統”BSD 套接字之上的一層封裝。ZMQ 讓編寫高效能網路應用程式極為簡單和有趣。”
因此, ZeroMQ不是傳統意義上的MQ。它比較適用於節點之間和節點與Master之間的通訊。Storm在0.8之前的Worker之間的通訊就是通過ZeroMQ。但是為什麼0.9就是用Netty替代了ZeroMQ呢?說替代不大合適,只是0.9的預設的Worker之間的通訊是使用了Netty,ZeroMQ還是支援的。Storm官方認為ZeroMQ有以下缺點:
不容易部署,尤其是在雲環境下:以為ZMQ是以C寫的,因此它還是緊依賴於作業系統環境的。
無法限制其記憶體。通過JVM可以很容易的限制java所佔用的記憶體。但是ZMQ對於Storm來說是個黑盒似得存在。
Storm無法從ZMQ獲取資訊。比如Storm無法知道當前buffer中有多少資料為傳送。
當然了還有所謂的效能問題,具體可以訪問Netty作者的blog。結論就是Netty的效能比ZMQ(在預設配置下)好兩倍。不知道所謂的ZMQ的預設配置是什麼。反正我對這個結果挺驚訝。當然了,Netty使用Java實現的確方便了在Worker之間的通訊加上授權和認證機制。這個使用ZMQ的確是不太好做。
4. 高可用性
HA是分散式系統的必要屬性。如果沒有HA,其實系統是不可用的。那麼如果實現HA?對於Storm來說,它認為Master節點Nimbus是無狀態的,無狀態意味著可以快速恢復,因此Nimbus並沒有實現HA(不知道以後的Nimbus是否會實現HA,實際上使用ZooKeeper實現節點的HA是開源領域的通用做法)。為什麼說Nimbus是無狀態的呢?因為叢集所有的元資料都儲存到了ZooKeeper(ZK)中。Nimbus定時從ZK獲取資訊,並且通過向ZK寫資訊來控制Worker。Worker也是通過從ZK中獲取資訊,通過這種方式,Worker執行從Nimbus傳遞過來的命令。
Storm的這種使用ZK的方式還是很值得借鑑的。
Spark是如何實現HA的?我的另外一篇文章分析過Spark的Master是怎麼實現HA的:Spark技術內幕:Master基於ZooKeeper的High Availability(HA)原始碼實現 。
也是通過ZK的leader 選舉實現的。Spark使用了百行程式碼的級別實現了Master的HA,由此可見ZK的功力。
除了這些Master的HA,還有每個Worker的HA。或者說Worker的HA說法不太準確,因此對於叢集裡的工作節點來說,它可以非常容易失敗的。這裡的HA可以說是如何讓Worker失敗後快速重啟,重新提供服務。實現方式也可以由很多種。一個簡單的方法就是使用一個容器(Container)啟動Worker並且監控Worker的狀態,如果Worker異常退出,那麼就重新啟動它。這個方法很簡單也很有效。
如果是節點宕機呢?上述方法肯定是不能用的。這種情況下Master會檢測到Worker的心跳超時,那麼就會從資源池中把這個節點刪除。回到正題,宕機後的節點重啟涉及到了運維方面的知識。對於一個叢集來說,硬體宕機這種情況應該需要統一的管理,也就是叢集也可以由一個Master,維持每個節點的心跳來確定硬體的狀態。如果節點宕機,那麼叢集首先是重啟它。如果啟動失敗可能會通過電話或者簡訊或者郵件通知運維人員。因此運維人員為了保證叢集的高可用性付出了很多的努力,尤其是大型網際網路公司的運維人員,非常值得點贊。當然了這個已經不是Storm或者Spark所能涵蓋的了。
5. 儲存模型與資料不丟失
其實,資料不丟失有時候和處理速度是矛盾的。為了資料不丟失就要進行資料持久化,資料持久化意味著要寫硬碟,在固態硬碟還沒有成為標配的今天,硬碟的IO速度永遠是系統的痛點。當然了可以在另外節點的記憶體上進行備份,但是這涉及到了叢集的兩個稀缺資源:記憶體和網路。如果因為備份而佔用了大量的網路頻寬的話,那必將影響系統的效能,吞吐量。
當然了,可以使用日誌的方式。但是日誌的話對於錯誤恢復的時間又是不太能接受的。流式計算系統的特點就是要快,如果錯誤恢復時間太長,那麼可能不如直接replay來的快,而且系統設計還更為簡單。
其實如果不是為了追求100%的資料丟失,可以使用checkpoint的機制,允許一個時間視窗內的資料丟失。
回到系統設計本身,實際上流式計算系統主要是為了離線和近線的機器學習和資料探勘,因此肯定要保證資料的處理速度:至少系統可以處理一天的新增資料,否則資料堆積越來越大。因此即使有的資料處理丟失了資料,可以讓源頭重新發送資料。
還有另外一個話題,就是系統的元資料信心如何儲存,因為系統的路由資訊等需要是全域性可見的,需要儲存類似的這些資料以供叢集查詢。當然了Master節點保持了和所有節點的心跳,它完全可以儲存這些資料,並且在心跳中可以返回這些資料。實際上HDFS的NameNode就是這麼做的。HDFS的NN這種設計非常合理,為什麼這麼說?HDFS的元資料包含了非常多的資料:
目錄檔案樹結構和檔案與資料塊的對應關係:會持久化到物理儲存中,檔名叫做fsimage。
DN與資料塊的對應關係,即資料塊儲存在哪些DN中:在DN啟動時會上報到NN它所維護的資料塊。這個是動態建立的,不會持久化。因此,叢集的啟動可能需要比較長的時間。
那麼對於流式計算系統這種算得上輕量級的元資料來說,Master處理這些元資料實際上要簡單的多,當然了,Master需要實現服務的HA和資料的HA。這些不是一個輕鬆的事情。實際上,可以採用ZooKeeper來儲存系統的元資料。ZooKeeper使用一個目錄樹的結構來儲存叢集的元資料。節點可以監控感興趣的資料,如果資料有變化,那麼節點會收到通知,然後就保證了系統級別的資料一致性。這點對於系統比較重要,因為節點都是不穩定的,因此係統的其他服務可能都會因為節點失效而發生變化,這些都需要通知相關的節點更新器服務列表,保證了部分節點的失效並不會影響系統的整體的服務,從而也就實現了故障對於使用者的透明性。
---------------------
作者:anzhsoft
來源:CSDN
原文:https://blog.csdn.net/anzhsoft/article/details/38168025
版權宣告:本文為博主原創文章,轉載請附上博文連結!