
機器學習之旅:支援向量機通俗導論(理解SVM的三層境界)
作者:July、pluskid ;致謝:白石、JerryLead支援向量機通俗導論(理解SVM的三層境界)
出處:結構之法演算法之道blog。
前言
動筆寫這個支援向量機(support vector machine)是費了不少勁和困難的,原因很簡單,一者這個東西本身就並不好懂,要深入學習和研究下去需花費不少時間和精力,二者這個東西也不好講清楚,儘管網上已經有朋友寫得不錯了(見文末參考連結),但在描述數學公式的時候還是顯得不夠。得益於同學白石的數學證明,我還是想嘗試寫一下,希望本文在兼顧通俗易懂的基礎上,真真正正能足以成為一篇完整概括和介紹支援向量機的導論性的文章。
本文在寫的過程中,參考了不少資料,包括
同時,閱讀本文時建議大家儘量使用chrome等瀏覽器,如此公式才能更好的顯示,再者,閱讀時可拿張紙和筆出來,把本文所有定理.公式都親自推導一遍或者直接列印下來(可直接列印網頁版或本文文末附的PDF,享受隨時隨地思考、演算的極致快感),在文稿上演算。
Ok,還是那句原話,有任何問題,歡迎任何人隨時不吝指正 & 賜教,感謝。
第一層、瞭解SVM
1.0、什麼是支援向量機SVM
要明白什麼是SVM,便得從分類說起。
分類作為資料探勘領域中一項非常重要的任務,它的目的是學會一個分類函式或分類模型(或者叫做分類器),而支援向量機本身便是一種監督式學習的方法(),它廣泛的應用於統計分類以及迴歸分析中。
支援向量機(SVM)是90年代中期發展起來的基於統計學習理論的一種機器學習方法,通過尋求結構化風險最小來提高學習機泛化能力,實現經驗風險和置信範圍的最小化,從而達到在統計樣本量較少的情況下,亦能獲得良好統計規律的目的。
通俗來講,它是一種二類分類模型,其基本模型定義為特徵空間上的間隔最大的線性分類器,即支援向量機的學習策略便是間隔最大化,最終可轉化為一個凸二次規劃問題的求解。
對於不想深究SVM原理的同學或比如就只想看看SVM是幹嘛的,那麼,瞭解到這裡便足夠了,不需上層。而對於那些喜歡深入研究一個東西的同學,甚至究其本質的,咱們則還有很長的一段路要走,萬里長征,咱們開始邁第一步吧,相信你能走完。
1.1、線性分類
OK,在講SVM之前,咱們必須先弄清楚一個概念:線性分類器(也可以叫做感知機,這裡的機表示的是一種演算法,本文第三部分、證明SVM中會詳細闡述)。
1.1.1、分類標準
這裡我們考慮的是一個兩類的分類問題,資料點用 來表示,這是一個 維向量,w^T中的T代表轉置,而類別用 來表示,可以取 1 或者 -1 ,分別代表兩個不同的類。一個線性分類器的學習目標就是要在 維的資料空間中找到一個分類超平面,其方程可以表示為:
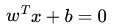
上面給出了線性分類的定義描述,但或許讀者沒有想過:為何用y取1 或者 -1來表示兩個不同的類別呢?其實,這個1或-1的分類標準起源於logistic迴歸,為了完整和過渡的自然性,咱們就再來看看這個logistic迴歸。
1.1.2、1或-1分類標準的起源:logistic迴歸
Logistic迴歸目的是從特徵學習出一個0/1分類模型,而這個模型是將特性的線性組合作為自變數,由於自變數的取值範圍是負無窮到正無窮。因此,使用logistic函式(或稱作sigmoid函式)將自變數對映到(0,1)上,對映後的值被認為是屬於y=1的概率。 形式化表示就是 假設函式其中x是n維特徵向量,函式g就是logistic函式。 而

 的影象是
的影象是可以看到,將無窮對映到了(0,1)。 而假設函式就是特徵屬於y=1的概率。

當我們要判別一個新來的特徵屬於哪個類時,只需求,若大於0.5就是y=1的類,反之屬於y=0類。 再審視一下

 ,發現
,發現 只和
只和 有關,
有關, >0,那麼
>0,那麼 ,g(z)只不過是用來對映,真實的類別決定權還在
,g(z)只不過是用來對映,真實的類別決定權還在 。還有當時
。還有當時 ,
, =1,反之
=1,反之 =0。如果我們只從
=0。如果我們只從 出發,希望模型達到的目標無非就是讓訓練資料中y=1的特徵
出發,希望模型達到的目標無非就是讓訓練資料中y=1的特徵 ,而是y=0的特徵
,而是y=0的特徵 。Logistic迴歸就是要學習得到
。Logistic迴歸就是要學習得到 ,使得正例的特徵遠大於0,負例的特徵遠小於0,強調在全部訓練例項上達到這個目標。
,使得正例的特徵遠大於0,負例的特徵遠小於0,強調在全部訓練例項上達到這個目標。1.1.3、形式化標示
我們這次使用的結果標籤是y=-1,y=1,替換在logistic迴歸中使用的y=0和y=1。同時將 替換成w和b。以前的
替換成w和b。以前的 ,其中認為
,其中認為 。現在我們替換為b,後面替換
。現在我們替換為b,後面替換 為
為 (即
(即 )。這樣,我們讓
)。這樣,我們讓 ,進一步
,進一步 。也就是說除了y由y=0變為y=-1,只是標記不同外,與logistic迴歸的形式化表示沒區別。 再明確下假設函式
。也就是說除了y由y=0變為y=-1,只是標記不同外,與logistic迴歸的形式化表示沒區別。 再明確下假設函式上面提到過我們只需考慮

 的正負問題,而不用關心g(z),因此我們這裡將g(z)做一個簡化,將其簡單對映到y=-1和y=1上。對映關係如下:
的正負問題,而不用關心g(z),因此我們這裡將g(z)做一個簡化,將其簡單對映到y=-1和y=1上。對映關係如下:
於此,想必已經解釋明白了為何線性分類的標準一般用1 或者-1 來標示。 注:上小節來自jerrylead所作的斯坦福機器學習課程的筆記。
1.2、線性分類的一個例子
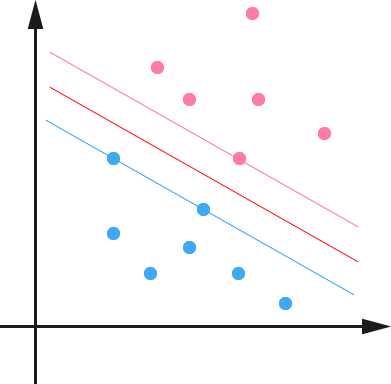
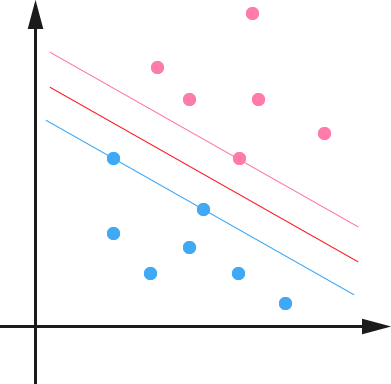
下面舉個簡單的例子,一個二維平面(一個超平面,在二維空間中的例子就是一條直線),如下圖所示,平面上有兩種不同的點,分別用兩種不同的顏色表示,一種為紅顏色的點,另一種則為藍顏色的點,紅顏色的線表示一個可行的超平面。
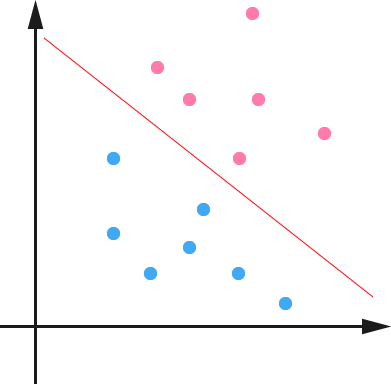
從上圖中我們可以看出,這條紅顏色的線把紅顏色的點和藍顏色的點分開來了。而這條紅顏色的線就是我們上面所說的超平面,也就是說,這個所謂的超平面的的確確便把這兩種不同顏色的資料點分隔開來,在超平面一邊的資料點所對應的 全是 -1 ,而在另一邊全是 1 。
接著,我們可以令分類函式(提醒:下文很大篇幅都在討論著這個分類函式):
顯然,如果 ,那麼 是位於超平面上的點。我們不妨要求對於所有滿足 的點,其對應的 等於 -1 ,而 則對應 的資料點。
注:上圖中,定義特徵到結果的輸出函式
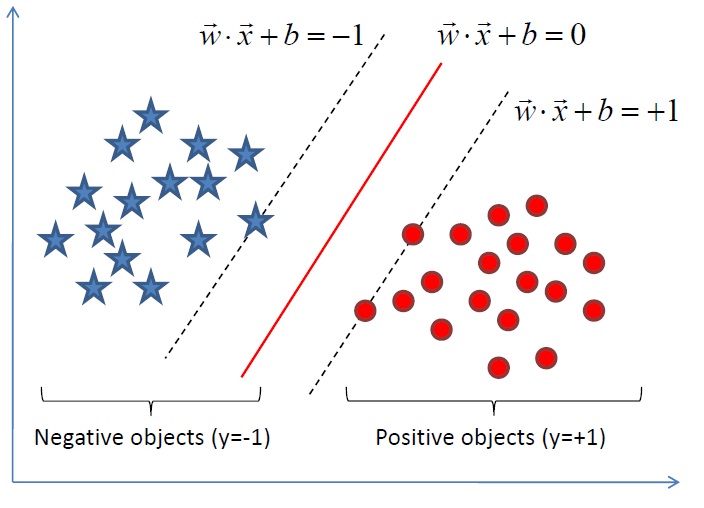
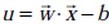 ,與我們之前定義的
,與我們之前定義的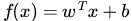 實質是一樣的。為什麼?因為無論是,還是,不影響最終優化結果。下文你將看到,當我們轉化到優化
實質是一樣的。為什麼?因為無論是,還是,不影響最終優化結果。下文你將看到,當我們轉化到優化 (有一朋友飛狗來自Mare_Desiderii,看了上面的定義之後,問道:請教一下SVM functional margin 為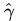
更進一步,我們在進行分類的時候,將資料點 代入 中,如果得到的結果小於 0 ,則賦予其類別 -1 ,如果大於 0 則賦予類別 1 。如果 ,則很難辦了,分到哪一類都不是。
請讀者注意,下面的篇幅將按下述3點走:
- 咱們就要確定上述分類函式f(x) = w.x + b(w.x表示w與x的內積)中的兩個引數w和b,通俗理解的話w是法向量,b是截距(再次說明:定義特徵到結果的輸出函式
- 那如何確定w和b呢?答案是尋找兩條邊界端或極端劃分直線中間的最大間隔(之所以要尋最大間隔是為了能更好的劃分不同類的點,下文你將看到:為尋最大間隔,匯出1/2||w||^2,繼而引入拉格朗日函式和對偶變數a,化為對單一因數對偶變數a的求解,當然,這是後話),從而確定最終的最大間隔分類超平面hyper plane和分類函式;
- 進而把尋求分類函式f(x) = w.x + b的問題轉化為對w,b的最優化問題,最終化為對偶因子的求解。
總結成一句話即是:從最大間隔出發(目的本就是為了確定法向量w),轉化為求對變數w和b的凸二次規劃問題。亦或如下圖所示(有點需要注意,如讀者@醬爆小八爪所說:從最大分類間隔開始,就一直是凸優化問題):

1.3、函式間隔Functional margin與幾何間隔Geometrical margin
一般而言,一個點距離超平面的遠近可以表示為分類預測的確信或準確程度。
- 在超平面w*x+b=0確定的情況下,|w*x+b|能夠相對的表示點x到距離超平面的遠近,而w*x+b的符號與類標記y的符號是否一致表示分類是否正確,所以,可以用量y*(w*x+b)的正負性來判定或表示分類的正確性和確信度。
1.3.1、函式間隔Functional margin
我們定義函式間隔functional margin 為:
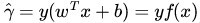
接著,我們定義超平面(w,b)關於訓練資料集T的函式間隔為超平面(w,b)關於T中所有樣本點(xi,yi)的函式間隔最小值,其中,x是特徵,y是結果標籤,i表示第i個樣本,有:
然與此同時,問題就出來了。上述定義的函式間隔雖然可以表示分類預測的正確性和確信度,但在選擇分類超平面時,只有函式間隔還遠遠不夠,因為如果成比例的改變w和b,如將他們改變為2w和2b,雖然此時超平面沒有改變,但函式間隔的值f(x)卻變成了原來的2倍。
其實,我們可以對法向量w加些約束條件,使其表面上看起來規範化,如此,我們很快又將引出真正定義點到超平面的距離--幾何間隔geometrical margin的概念(很快你將看到,幾何間隔就是函式間隔除以個||w||,即yf(x) / ||w||)。
1.3.2、點到超平面的距離定義:幾何間隔Geometrical margin

在給出幾何間隔的定義之前,咱們首先來看下,如上圖所示,對於一個點 ,令其垂直投影到超平面上的對應的為 ,由於 是垂直於超平面的一個向量,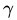
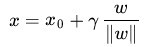
(||w||表示的是範數,關於範數的概念參見這裡)
又由於 是超平面上的點,滿足 ,代入超平面的方程即可算出:
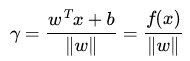
(有的書上會寫成把||w|| 分開相除的形式,如本文參考文獻及推薦閱讀條目11,其中,||w||為w的二階泛數)
不過這裡的
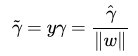
(代人相關式子可以得出:yi*(w/||w|| + b/||w||))
正如本文評論下讀者popol1991留言:函式間隔y*(wx+b)=y*f(x)實際上就是|f(x)|,只是人為定義的一個間隔度量;而幾何間隔|f(x)|/||w||才是直觀上的點到超平面距離。
想想二維空間裡的點到直線公式:假設一條直線的方程為ax+by+c=0,點P的座標是(x0,y0),則點到直線距離為|ax0+by0+c|/sqrt(a^2+b^2)。如下圖所示:

那麼如果用向量表示,設w=(a,b),f(x)=wx+c,那麼這個距離正是|f(p)|/||w||。
1.4、最大間隔分類器Maximum Margin Classifier的定義
於此,我們已經很明顯的看出,函式間隔functional margin 和 幾何間隔geometrical margin 相差一個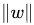
通過上節,我們已經知道:
1、functional margin 明顯是不太適合用來最大化的一個量,因為在 hyper plane 固定以後,我們可以等比例地縮放 的長度和 的值,這樣可以使得
2、而 geometrical margin 則沒有這個問題,因為除上了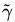
這樣一來,我們的 maximum margin classifier 的目標函式可以定義為:
當然,還需要滿足一些條件,根據 margin 的定義,我們有

其中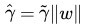

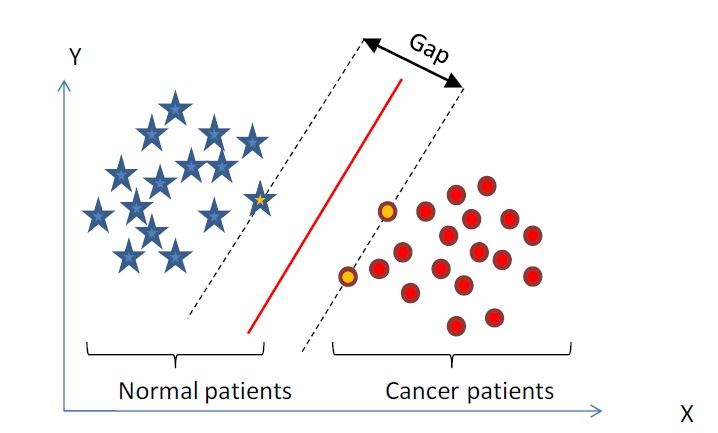
通過求解這個問題,我們就可以找到一個 margin 最大的 classifier ,如下圖所示,中間的紅色線條是 Optimal Hyper Plane ,另外兩條線到紅線的距離都是等於
通過最大化 margin ,我們使得該分類器對資料進行分類時具有了最大的 confidence,從而設計決策最優分類超平面。
1.5、到底什麼是Support Vector
上節,我們介紹了Maximum Margin Classifier,但並沒有具體闡述到底什麼是Support Vector,本節,咱們來重點闡述這個概念。咱們不妨先來回憶一下上節1.4節最後一張圖:
可以看到兩個支撐著中間的 gap 的超平面,它們到中間的純紅線separating hyper plane 的距離相等,即我們所能得到的最大的 geometrical margin
或亦可看下來自此PPT中的一張圖,Support Vector便是那藍色虛線和粉紅色虛線上的點:
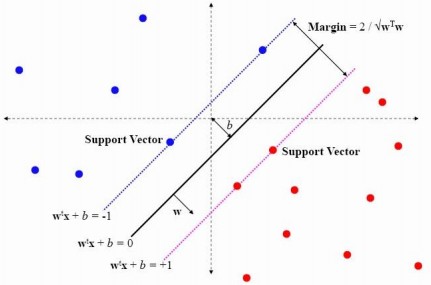
很顯然,由於這些 supporting vector 剛好在邊界上,所以它們滿足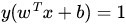
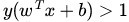
OK,到此為止,算是瞭解到了SVM的第一層,對於那些只關心怎麼用SVM的朋友便已足夠,不必再更進一層深究其更深的原理。
第二層、深入SVM
2.1、從線性可分到線性不可分
2.1.1、從原始問題到對偶問題的求解
雖然上文1.4節給出了目標函式,卻沒有講怎麼來求解。現在就讓我們來處理這個問題。回憶一下之前得到的目標函式(subject to匯出的則是約束條件):
由於求

 的最大值相當於求
的最大值相當於求 的最小值,所以上述問題等價於(w由分母變成分子,從而也有原來的max問題變為min問題,很明顯,兩者問題等價):
的最小值,所以上述問題等價於(w由分母變成分子,從而也有原來的max問題變為min問題,很明顯,兩者問題等價):
- 轉化到這個形式後,我們的問題成為了一個凸優化問題,或者更具體的說,因為現在的目標函式是二次的,約束條件是線性的,所以它是一個凸二次規劃問題。這個問題可以用任何現成的 QP (Quadratic Programming) 的優化包進行求解,歸結為一句話即是:在一定的約束條件下,目標最優,損失最小;
- 但雖然這個問題確實是一個標準的 QP 問題,但是它也有它的特殊結構,通過 Lagrange Duality 變換到對偶變數 (dual variable) 的優化問題之後,可以找到一種更加有效的方法來進行求解,而且通常情況下這種方法比直接使用通用的 QP 優化包進行優化要高效得多。
也就說,除了用解決QP問題的常規方法之外,還可以通過求解對偶問題得到最優解,這就是線性可分條件下支援向量機的對偶演算法,這樣做的優點在於:一者對偶問題往往更容易求解;二者可以自然的引入核函式,進而推廣到非線性分類問題。
至於上述提到,關於什麼是Lagrange duality?簡單地來說,通過給每一個約束條件加上一個 Lagrange multiplier(拉格朗日乘值),即引入拉格朗日乘子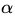

然後我們令

容易驗證,當某個約束條件不滿足時,例如
支援向量機通俗導論(理解SVM的三層境界)作者:July、pluskid ;致謝:白石、JerryLead出處:結構之法演算法之道blog。前言 動筆寫這個支援向量機(support vector machine)是費了不少勁和困難的,原因很簡單,一者這個東西本身就並
支援向量機通俗導論(理解SVM的三層境界)
作者:July 。致謝:pluskid、白石、JerryLead。
說明:本文最初寫於2012年6月,而後不斷反反覆覆修改&優化,修改次數達上百次,最後修改於2016年11月。
前言
作者:July 。致謝:pluskid、白石、JerryLead。
說明:本文最初寫於2012年6月,而後不斷反反覆覆修改&優化,修改次數達上百次,最後修改於2016年11月。
宣告:本文於2012年便早已附上所有參考連結,並註明是篇“學習筆記”, 前言第一層、瞭解SVM 1.0、什麼是支援向量機SVM 1.1、線性分類 1.2、線性分類的一個例子 1.3、函式間隔Functional margin與幾何間隔Geometrical margin 1.3.1、函式間隔Functional margin 1.3.2、點到超平面的距離定
第二層、深入SVM
2.1、從線性可分到線性不可分
2.1.1、從原始問題到對偶問題的求解
接著考慮之前得到的目標函式:
由於求的最大值相當於求的最小值,所以上述目標函式等價於(w由分母變成分子,從而也有原來的max問題變為min問題,很明顯,兩者問
構建支援向量機
1.替換邏輯迴歸函式
2.去除多餘的常數項 1/m
3.正則化項係數的處理
大間距分類器
SVM決
對於支援向量機,我看了好久也沒能看的很明白,裡面的理論有點多。所以呢,只能用sklearn來跑跑svm模型了。。
下面是程式碼:(svm支援多類別分類,所以這次還使用iris的資料)
from sklearn import svm
from skle
核函式是 SVM 的最重要的部分,我們可以通過設定不同的核函式來創造出非常複雜的、非線性的支援向量機。
1.核(Kernel)
首先來看看什麼是核函式。如圖所示,假設有一個樣本 x 有兩個特徵 x1,x2,我們可以根據與地標(landmarks) l(1),
第一層、瞭解SVM
支援向量機,因其英文名為support vector machine,故一般簡稱SVM,通俗來講,它是一種二類分類模型,其基本模型定義為特徵空間上的間隔最大的線性分類器,其學習策略
C−SVM基本公式推導過程
下面摘抄一小部分內容(不考慮推導細節的話,基本上能理解C-SVM方法推導的整個流程).
我們用一個超平面劃分圖中對圖中的兩類資料進行分類,超平面寫成f(x)=wTx+b=0,線上性可分的情況下,我們能找到一
注:此係列文章裡的部分演算法和深度學習筆記系列裡的內容有重合的地方,深度學習筆記裡是看教學視訊做的筆記,此處文章是看《機器學習實戰》這本書所做的筆記,雖然演算法相同,但示例程式碼有所不同,多敲一遍沒有壞處,哈哈。(裡面用到的資料集、程式碼可以到網上搜索,很容易找到。)。Python版本3.6
【參考資料】
【1】《統計學習方法》
基本概念
當訓練資料線性可分時,通過硬間隔最大化,學習一個線性的分類器,即線性可分支援向量機,又稱硬間隔支援向量機;
當訓練資料近似線性可分時,通過軟間隔(增加一個鬆弛因子)後學習一個線性的分類器,即軟間隔支援向量機;
set type of SVM (default 0) 0 -- C-SVC 1 -- nu-SVC 2 -- one-class SVM 3 -- epsilon-SVR 4 -- nu-SVR-t kernel_type : set type of kernel functi
線性可分
在二維平面中,正樣本和負樣本可以由一條直線完全隔開。假設存在直線
y
=
工具:PythonCharm 書中的程式碼是python2的,而我用的python3,結合實踐過程,這裡會標註實踐時遇到的問題和針對python3的修改。
實踐程式碼和訓練測試資料可以參考這裡
https://github.com/stonycat/ML
本欄目(Machine learning)包括單引數的線性迴歸、多引數的線性迴歸、Octave Tutorial、Logistic Regression、Regularization、神經網路、機器學習系統設計、SVM(Support Vector Machines 支援向量
6.1 間隔與支援向量
在樣本空間中,劃分超平面可通過如下線性方程來描述:
6.2 對偶問題
我們希望求解式(6.6)來得到大間隔劃分超平面所對應的模型:
對式(6.6)使用拉格朗日乘子法可得到其“對偶問 ### 一.簡介
支援向量機(svm)的想法與前面介紹的感知機模型類似,找一個超平面將正負樣本分開,但svm的想法要更深入了一步,它要求正負樣本中離超平面最近的點的距離要儘可能的大,所以svm模型建模可以分為兩個子問題:
(1)分的對:怎麼能讓超平面將正負樣本分的開;
(2)分的好:怎麼能讓距離超平 ### 一.簡介
上一節介紹了硬間隔支援向量機,它可以在嚴格線性可分的資料集上工作的很好,但對於非嚴格線性可分的情況往往就表現很差了,比如:
```python
import numpy as np
import matplotlib.pyplot as plt
import copy
import ra 支援向量機通俗導論(理解SVM的三層境界)作者:July 。致謝:pluskid、白石、JerryLead。說明:本文最初寫於2012年6月,而後不斷反反覆覆修改&優化,修改次數達上百次,最後修改於2016年11月。宣告:本文於2012年便早已附 
相關推薦
機器學習之旅:支援向量機通俗導論(理解SVM的三層境界)
機器學習--支援向量機通俗導論(理解SVM的三層境界)
支援向量機通俗導論(理解SVM的三層境界)
【轉載】支援向量機通俗導論(理解SVM的三層境界)
支援向量機通俗導論(理解SVM的三層境界)(2)
Andrew Ng 機器學習筆記 11 :支援向量機(Support Vector Machine)
自學機器學習之sklearn實現支援向量機
機器學習筆記09:支援向量機(二)-核函式(Kernels)
支援向量機通俗導論(一)
Spark機器學習系列之13: 支援向量機SVM
機器學習實戰筆記5—支援向量機
【機器學習筆記17】支援向量機
Stanford機器學習 第八講 支援向量機SVM
【機器學習演算法推導】支援向量機
【機器學習實戰-python3】支援向量機(Support Vecrtor Machines SVM)
Stanford機器學習---第八講. 支援向量機SVM
機器學習 第六章 支援向量機
《機器學習_07_01_svm_硬間隔支援向量機與SMO》
《機器學習_07_02_svm_軟間隔支援向量機》
支援向量機通俗導論 理解SVM的三層境界