
Keras + LSTM + 詞向量 情感分類/情感分析實驗
背景簡介
本人是深度學習入門的菜菜菜鳥一枚…
利用LSTM + word2vec詞向量進行文字情感分類/情感分析實驗,吸收了網上的資源和程式碼並嘗試轉化為自己的東西~
實驗環境
- win7 64位系統
- Anaconda 4.3.0 , Python 2.7 version
- Pycharm開發環境
- python包:keras,gensim,numpy等
實驗資料
本文的實驗資料是來自網上的中文標註語料,涉及書籍、酒店、計算機、牛奶、手機、熱水器六個方面的購物評論資料,具體介紹參見該文:購物評論情感分析。
資料處理
上面提到的資料在網上見到的次數比較多,原始格式是兩個excel檔案,如圖:
對,就是這兩個…估計來到本文的小夥伴也見過。一些程式碼就是直接從這兩個excel裡讀取資料、分詞、處理…不過我表示自己習慣從txt文本里獲取資料,因此本人將資料合併、去重(原資料裡有不少重複的評論)、分詞(用的是哈工大LTP分詞)之後存為一份txt文字,保留的資料情況如下:
正面評價個數:8680個
負面評價個數:8000個
文字如圖所示:

然後人工生成一份【語料類別】文字,用1表示正面評價,用0表示負面評價,與評論資料一一對應。
生成詞語的索引字典、詞向量字典
利用上述文字語料生成詞語的索引字典和詞向量字典。
注意:當Word2vec詞頻閾值設定為5時,詞頻小於5的詞語將不會生成索引,也不會生成詞向量資料。
工具:gensim裡的Word2vec,Dictionary
程式碼
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
功能:利用大語料生成詞語的索引字典、詞向量,然後儲存為pkl檔案
時間:2017年3月8日 13:19:40
"""
import pickle
import logging
import tkFileDialog
import numpy as np
np.random.seed(1337) # For Reproducibility
from Functions.TextSta import TextSta
from 其中,
T = TextSta(tkFileDialog.askopenfilename(title=u"選擇檔案"))
sentences = T.sen() # 獲取句子列表,每個句子又是詞彙的列表TextSta是我自己寫的一個類,讀取語料文字後,sentences = T.sen()將文本里的每一行生成一個列表,每個列表又是詞彙的列表。(這個類原來是用作句子分類的,每行是一個句子;這裡每行其實是一個評論若干個句子…我就不改程式碼變數名了…)
TextSta類部分程式碼:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
功能:一個類,執行文字轉換
輸入:分詞文字
輸出:句子列表,全文的詞彙列表,TF,DF
時間:2016年5月17日 19:08:34
"""
import codecs
import re
import tkFileDialog
class TextSta:
# 定義基本屬性,分詞文字的全路徑
filename = ""
# 定義構造方法
def __init__(self, path): # 引數path,賦給filename
self.filename = path
def sen(self): # 獲取句子列表
f1 = codecs.open(self.filename, "r", encoding="utf-8")
print u"已經開啟文字:", self.filename
# 獲得句子列表,其中每個句子又是詞彙的列表
sentences_list = []
for line in f1:
single_sen_list = line.strip().split(" ")
while "" in single_sen_list:
single_sen_list.remove("")
sentences_list.append(single_sen_list)
print u"句子總數:", len(sentences_list)
f1.close()
return sentences_list
if __name__ == "__main__":
pass總之,sentences的格式如下:
[[我, 是, 2月, …], [#, 蒙牛, 百, …], …]
所有的評論文字存為一個列表,每個評論文字又是詞彙的列表。
sentences列表的長度就是文字的行數:len(sentences) = 16680
利用Keras + LSTM進行文字分類
工具:Keras深度學習庫
程式碼:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
功能:利用詞向量+LSTM進行文字分類
時間:2017年3月10日 21:18:34
"""
import numpy as np
np.random.seed(1337) # For Reproducibility
import pickle
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import LSTM
from keras.layers.core import Dense, Dropout, Activation
from sklearn.cross_validation import train_test_split
from Functions import GetLineList
from Functions.TextSta import TextSta
# 引數設定
vocab_dim = 100 # 向量維度
maxlen = 140 # 文字保留的最大長度
batch_size = 32
n_epoch = 5
input_length = 140
def text_to_index_array(p_new_dic, p_sen): # 文字轉為索引數字模式
new_sentences = []
for sen in p_sen:
new_sen = []
for word in sen:
try:
new_sen.append(p_new_dic[word]) # 單詞轉索引數字
except:
new_sen.append(0) # 索引字典裡沒有的詞轉為數字0
new_sentences.append(new_sen)
return np.array(new_sentences)
# 定義網路結構
def train_lstm(p_n_symbols, p_embedding_weights, p_X_train, p_y_train, p_X_test, p_y_test):
print u'建立模型...'
model = Sequential()
model.add(Embedding(output_dim=vocab_dim,
input_dim=p_n_symbols,
mask_zero=True,
weights=[p_embedding_weights],
input_length=input_length))
model.add(LSTM(output_dim=50,
activation='sigmoid',
inner_activation='hard_sigmoid'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
print u'編譯模型...'
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print u"訓練..."
model.fit(p_X_train, p_y_train, batch_size=batch_size, nb_epoch=n_epoch,
validation_data=(p_X_test, p_y_test))
print u"評估..."
score, acc = model.evaluate(p_X_test, p_y_test, batch_size=batch_size)
print 'Test score:', score
print 'Test accuracy:', acc
# 讀取大語料文字
f = open(u"評價語料索引及詞向量.pkl", 'rb') # 預先訓練好的
index_dict = pickle.load(f) # 索引字典,{單詞: 索引數字}
word_vectors = pickle.load(f) # 詞向量, {單詞: 詞向量(100維長的陣列)}
new_dic = index_dict
print u"Setting up Arrays for Keras Embedding Layer..."
n_symbols = len(index_dict) + 1 # 索引數字的個數,因為有的詞語索引為0,所以+1
embedding_weights = np.zeros((n_symbols, 100)) # 建立一個n_symbols * 100的0矩陣
for w, index in index_dict.items(): # 從索引為1的詞語開始,用詞向量填充矩陣
embedding_weights[index, :] = word_vectors[w] # 詞向量矩陣,第一行是0向量(沒有索引為0的詞語,未被填充)
# 讀取語料分詞文字,轉為句子列表(句子為詞彙的列表)
print u"請選擇語料的分詞文字..."
T1 = TextSta(u"評價語料_分詞後.txt")
allsentences = T1.sen()
# 讀取語料類別標籤
print u"請選擇語料的類別文字...(用0,1分別表示消極、積極情感)"
labels = GetLineList.main()
# 劃分訓練集和測試集,此時都是list列表
X_train_l, X_test_l, y_train_l, y_test_l = train_test_split(allsentences, labels, test_size=0.2)
# 轉為數字索引形式
X_train = text_to_index_array(new_dic, X_train_l)
X_test = text_to_index_array(new_dic, X_test_l)
print u"訓練集shape: ", X_train.shape
print u"測試集shape: ", X_test.shape
y_train = np.array(y_train_l) # 轉numpy陣列
y_test = np.array(y_test_l)
# 將句子擷取相同的長度maxlen,不夠的補0
print('Pad sequences (samples x time)')
X_train = sequence.pad_sequences(X_train, maxlen=maxlen)
X_test = sequence.pad_sequences(X_test, maxlen=maxlen)
print('X_train shape:', X_train.shape)
print('X_test shape:', X_test.shape)
train_lstm(n_symbols, embedding_weights, X_train, y_train, X_test, y_test)
if __name__ == "__main__":
pass
其中,
from Functions import GetLineListGetLineList是自定義模組,用於獲取文字的類別(存為列表),程式碼如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
功能:文字轉列表,常用於讀取詞典(停用詞,特徵詞等)
使用:給定一個文字,將文字按行轉換為列表,每行對應列表裡的一個元素
時間:2016年5月15日 22:45:23
"""
import codecs
import tkFileDialog
def main():
# 開啟檔案
file_path = tkFileDialog.askopenfilename(title=u"選擇檔案")
f1 = codecs.open(file_path, "r", encoding="utf-8")
print u"已經開啟文字:", file_path
# 轉為列表
line_list = []
for line in f1:
line_list.append(line.strip())
print u"列表裡的元素個數:", len(line_list)
f1.close()
return line_list
if __name__ == "__main__":
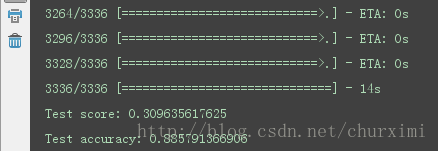
pass實驗結果
參考文獻: