
MapReduce案例二:好友推薦
1.需求
推薦好友的好友
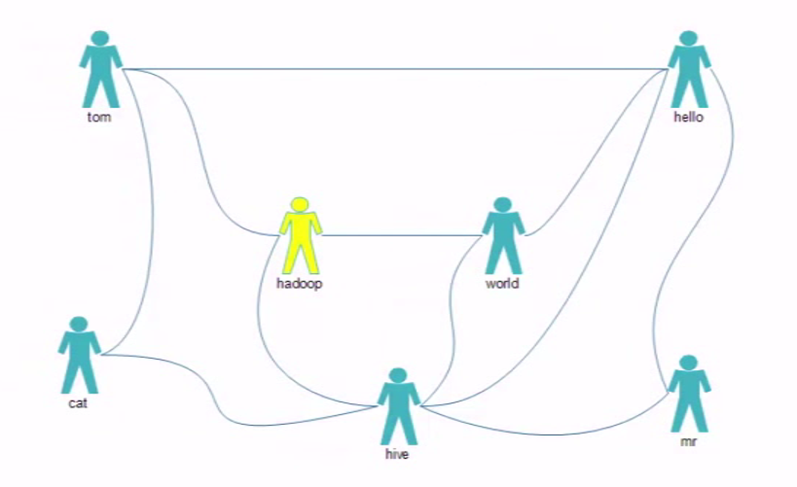
圖1:


2.解決思路

3.程式碼
3.1MyFoF類程式碼
說明:
該類定義了所載入的配置,以及執行的map,reduce程式所需要載入執行的類
package com.hadoop.mr.fof; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MyFoF { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {//conf Configuration conf = new Configuration(true); Job job=Job.getInstance(conf); job.setJarByClass(MyFoF.class); //map job.setMapperClass(FMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //map階段的分割槽排序都使用預設的不用額外設定 job.setReducerClass(FReducer.class); //input ... output Path input=new Path("/data/fof/input"); FileInputFormat.addInputPath(job, input); Path output=new Path("/data/fof/output"); if(output.getFileSystem(conf).exists(output)){ output.getFileSystem(conf).delete(output); } FileOutputFormat.setOutputPath(job, output); //submit job.waitForCompletion(true); } }
3.2FMapper類程式碼
說明:
該類的作用是編寫map階段的程式碼,對文字資料做一個預處理,按照規劃比較每組的kv 做比較,這裡面的k是偏移量longwritable型別,v是文字的字串行 text型別。
程式碼邏輯:
1.雙重for迴圈,外層迴圈比較直接關係,內層迴圈比較間接關係,最終map生成一箇中間資料集,會有直接關係和間接關係。
2.將相同key的內容放在一起,交由reduce處理,如果是0代表為直接關係不作推薦,如果為1代表是間接關係,需要被推薦。
package com.hadoop.mr.fof; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.util.StringUtils; public class FMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ Text mkey=new Text(); IntWritable mval=new IntWritable(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { //tom hello hadoop cat String[] strs = StringUtils.split(value.toString(),' '); //雙重for迴圈,外層迴圈比較直接關係,內層迴圈比較間接關係,最終map生成一箇中間資料集,會有直接關係和間接關係, //將相同key的內容放在一起,交由reduce處理,如果是0代表為直接關係不作推薦,如果為1代表是間接關係,需要被推薦。 for (int i = 0; i < strs.length; i++) { mkey.set(getFoF(strs[0],strs[i])); mval.set(0); context.write(mkey, mval); for (int j = i+1; j < strs.length; j++) { mkey.set(getFoF(strs[i],strs[j])); mval.set(1); context.write(mkey, mval); } } } //定義一個比較方法如果前一個數s1小於後面一個數s2,就拼接為s1+s2,否則s2+s1 public static String getFoF(String s1,String s2){ if(s1.compareTo(s2)<0){ return s1+":"+s2; } return s2+":"+s1; } }
3.3FReducer類程式碼
說明:
該類的作用是對map的輸出做進一步處理,兩兩出現的value不為0的相同key的value累加起來,將累加的結果賦給key
package com.hadoop.mr.fof; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class FReducer extends Reducer<Text, IntWritable, Text, IntWritable> { IntWritable rval=new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int flag=0; int sum=0; //增加for迴圈迭代values // hello:hadoop 0 // hello:hadoop 1 // hello:hadoop 0 for (IntWritable v : values) { //如果獲取到的values是0則將flag置為1,如果不為0則將所有的values疊加 if(v.get()==0){ flag=1; } sum+=v.get(); } //如果獲取到的values不為0,就將相同key且values不為0的values疊加賦值給reduce中key中對應的值 if(flag==0){ rval.set(sum); context.write(key, rval); } } }
4.服務端執行
4.1建立檔案輸入目錄
[[email protected] test]# hdfs dfs -mkdir -p /data/fof/input
4.2上傳檔案到hdfs
[[email protected] test]# cat fof.txt tom hello hadoop cat world hadoop hello hive cat tom hive mr hive hello hive cat hadoop world hello mr hadoop tom hive world hello tom world hive mr [[email protected] test]#hdfs dfs -put ./fof.txt /data/fof/input
4.3執行jar包
[[email protected] test]# hadoop jar ../jar_package/MyFOF.jar com.hadoop.mr.fof.MyFoF
4.4檢視生成的輸出檔案
[[email protected] test]# hdfs dfs -ls /data/fof/output/ Found 2 items -rw-r--r-- 2 root supergroup 0 2019-01-01 06:11 /data/fof/output/_SUCCESS -rw-r--r-- 2 root supergroup 116 2019-01-01 06:11 /data/fof/output/part-r-00000
[[email protected] test]# hdfs dfs -cat /data/fof/output/part-r-00000 cat:hadoop 2 cat:hello 2 cat:mr 1 cat:world 1 hadoop:hello 3 hadoop:mr 1 hive:tom 3 mr:tom 1 mr:world 2 tom:world 2
說明:通過圖1可以發現
cat 和hadoop、hello都有2個共同的朋友tom、hive
cat和mr、world有1個共同的朋友hive
hadoop和hello有3個共同的朋友 tom、world、hive
hadoop和hive有1個共同的朋友world
hive和tom有3個共同的朋友cat、hadoop、hello
mr和tom有1個共同的朋友hello
mr和world有2個共同的朋友hello、hive
tom和world有2個共同的朋友hello、hadoop
5.報錯解決
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot delete /data/fof/output. Name)
這個異常表示hadoop處於安全狀態,而你又對它進行了上傳,修改,刪除檔案的操作。
剛啟動完hadoop的時候,hadoop會進入安全模式,此時不能對hdfs進行上傳,修改,刪除檔案的操作。
命令是用來檢視當前hadoop安全模式的開關狀態
hdfs dfsadmin -safemode get
命令是開啟安全模式
hdfs dfsadmin -safemode enter
命令是離開安全模式
hdfs dfsadmin -safemode leave
離開安全模式再次執行即可。