
KMP演算法之簡單求next陣列
前言
1.next陣列的計算只與模式串有關,與主串無關
2.next可能有不同的表示方法,但意義不變
3.字首:除最後一個字母外,前面字母的從前往後組合情況。串abaaba的字首={a,ab,aba,abaa,abaab}
4.字尾:除第一個字母外,後面字母的從前往後組合情況。串abaaba的字尾={baaba,aaba,aba,ba,a}
next陣列中儲存的數是什麼?
最大 **字首==字尾 ** 是next陣列中的元素值。
意義為:如果在與主串匹配的過程中子串失配,則不會回溯主串,只需子串倒退一定的位數,這個具體的位數就是next陣列中儲存的值有關。
#計算方法
串abaaba的字首={a,ab,aba,abaa,abaab}
字尾={baaba,aaba,aba,ba,a}
字首∩字尾={a,aba}
最大 字首==字尾 為aba,數目為3.
1.next[1]=0
2.串ab的(最大 字首==字尾 數)=0,next[2]=0
a b
3.串aba的(最大 字首==字尾 數)=1,next[3]=1
a b a
4.串abaa的(最大 字首==字尾 數)=1,next[4]=1
a b a a
5.串abaab的(最大 字首==字尾 數)=2,next[5]=2
a b a **a b **
6.串abaabc的(最大 字首==字尾 數)=0,next[6]=0
a b a a b c
7.串abaabca的(最大 字首==字尾 數)=1,next[7]=1
a b a a b c a
8.串abaabcac的(最大 字首==字尾 數)=0,next[8]=0
a b a a b c a c
規則1(最大前後綴):
(上表也成位《最大長度表》)
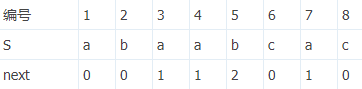
按照網上的某些方法,next陣列就求完了。WTF!明明不一樣好吧!那好,next陣列是為了後面用的,使用的方法不同,next陣列也會稍有差別。
失配時,模式串向右移動的位數為:已匹配字元數 -失配字元的上一位字元所對應的最大長度值
引入規則:
規則2(下標從0開始計):
右移一位,最左邊添-1,最右邊自然溢位
next: -1 0 0 1 1 2 0 1
這是其中一種表示方法,見到-1用這種,失配時,模式串向右移動的位數為:失配字元所在位置 - 失配字元對應的next 值
也就是說,失配時,下一次開始匹配的元素就是next陣列中儲存的元素下標所指向的元素(下標從0開始)
將-1定義為相同長度為0,此時沒有可以後退的了,子串向前移動一位。
0定義為:下一次從下標為0的開始匹配,即第一個元素。
規則3(下標從1開始計):
規則2基礎上全部加1
next :0 1 1 2 2 3 1 2
也就是說,失配時,下一次開始匹配的元素就是next陣列中儲存的元素下標所指向的元素(下標從1開始)
將0定義為相同長度為0,此時沒有可以後退的了,子串向前移動一位。
1定義為:下一次從下標為1的開始匹配,即第一個元素。
熟練掌握的話在考試中只需30秒可以手算出next陣列。
參考連結:
http://www.cskaoyan.com/thread-650235-1-1.html
https://blog.csdn.net/v_july_v/article/details/7041827