
python3抓取到的拉勾資料統計
趁著最近有時間寫了個拉勾爬蟲抓取了後端、前端和移動端技術崗位的資料,總共大約6多萬條記錄,對其取前十名進行統計
按地域劃分:
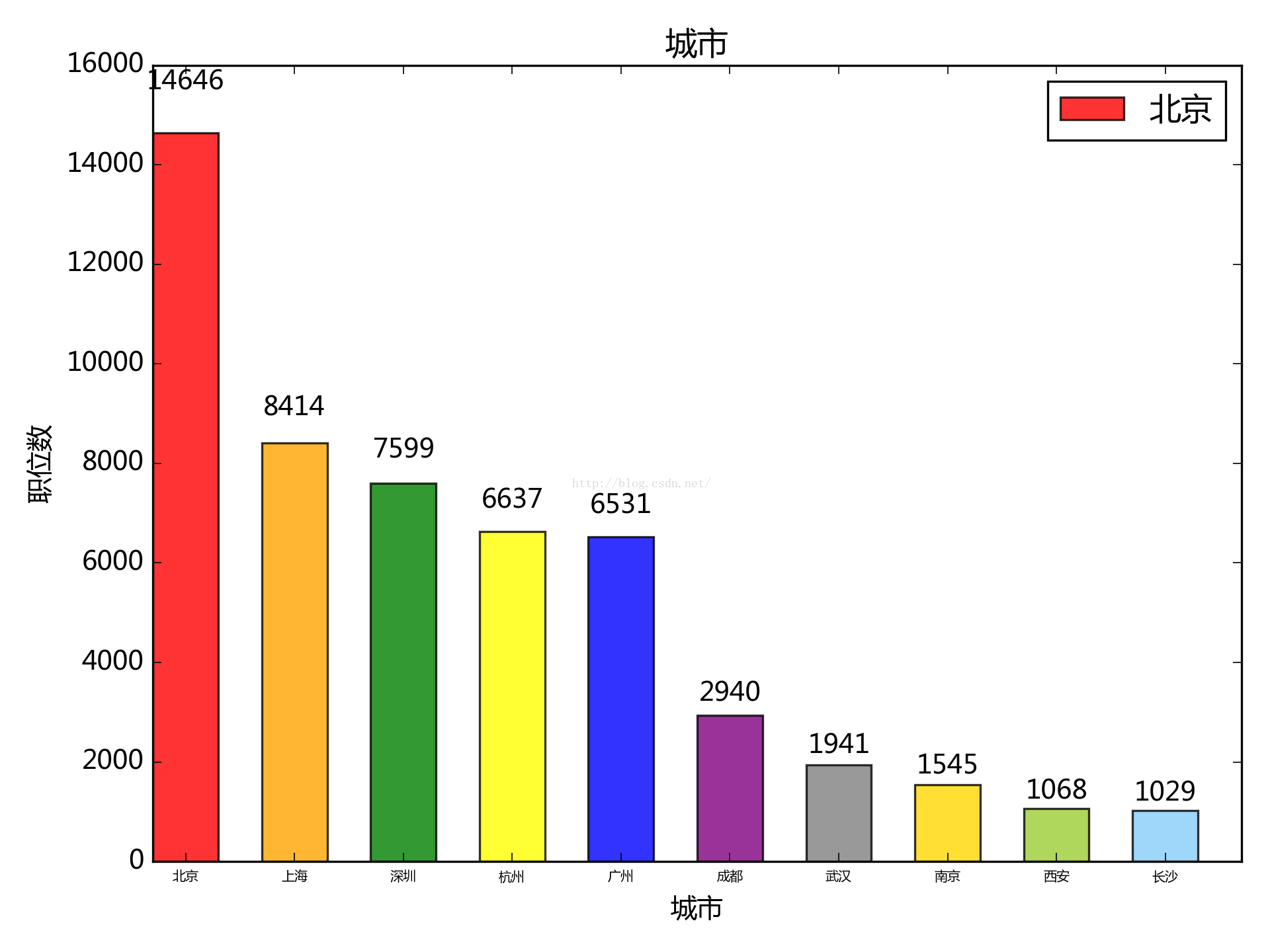
可以看出北上廣深杭的數量遠遠超出其它城市,機會相對較多
2. 按融資階段來看:
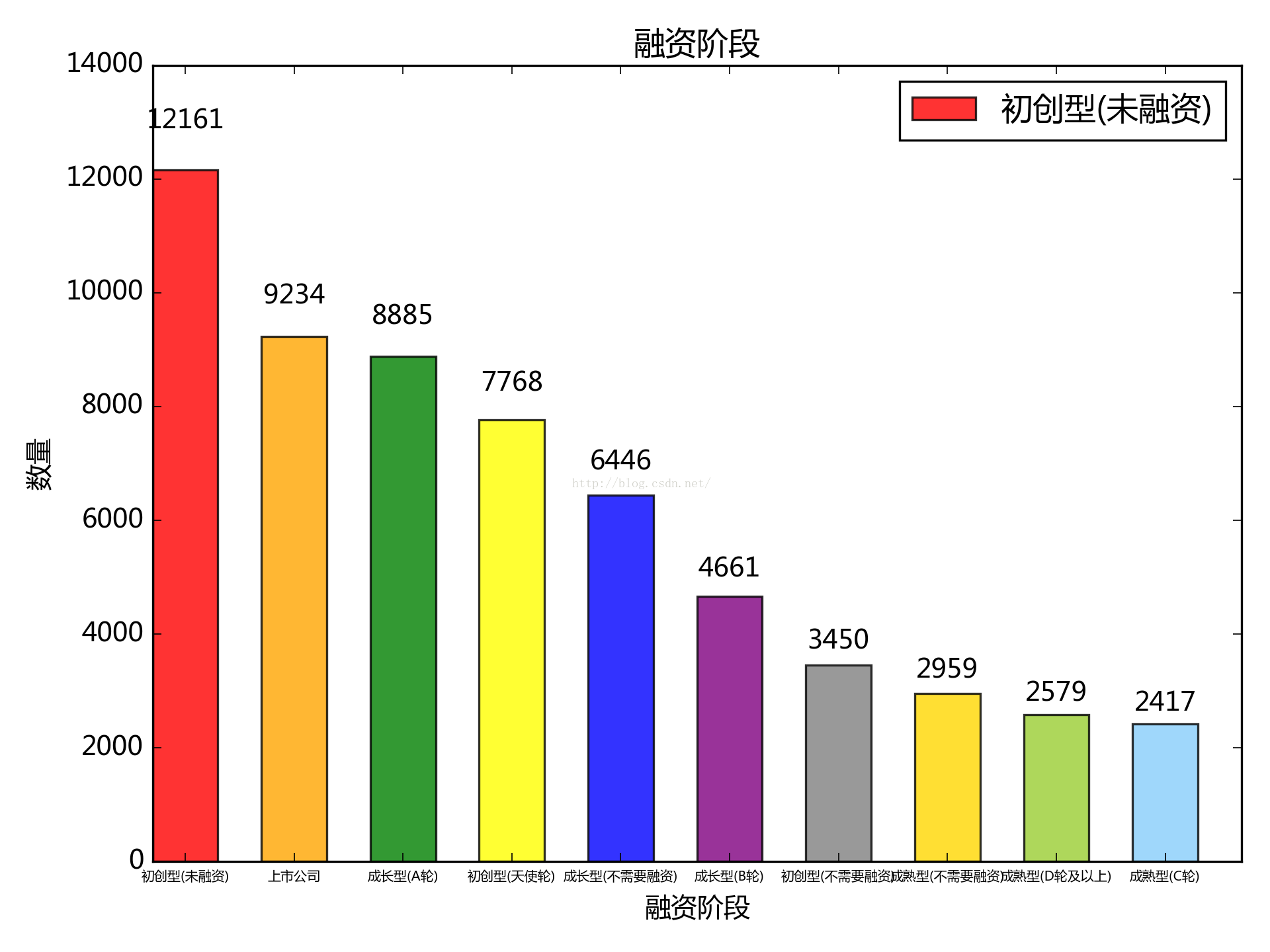
初創型未融資的居多,已上市及A輪的差不多,C輪是最少的,難道就是傳說中的C輪魔咒
3. 按所需最低學歷來看:
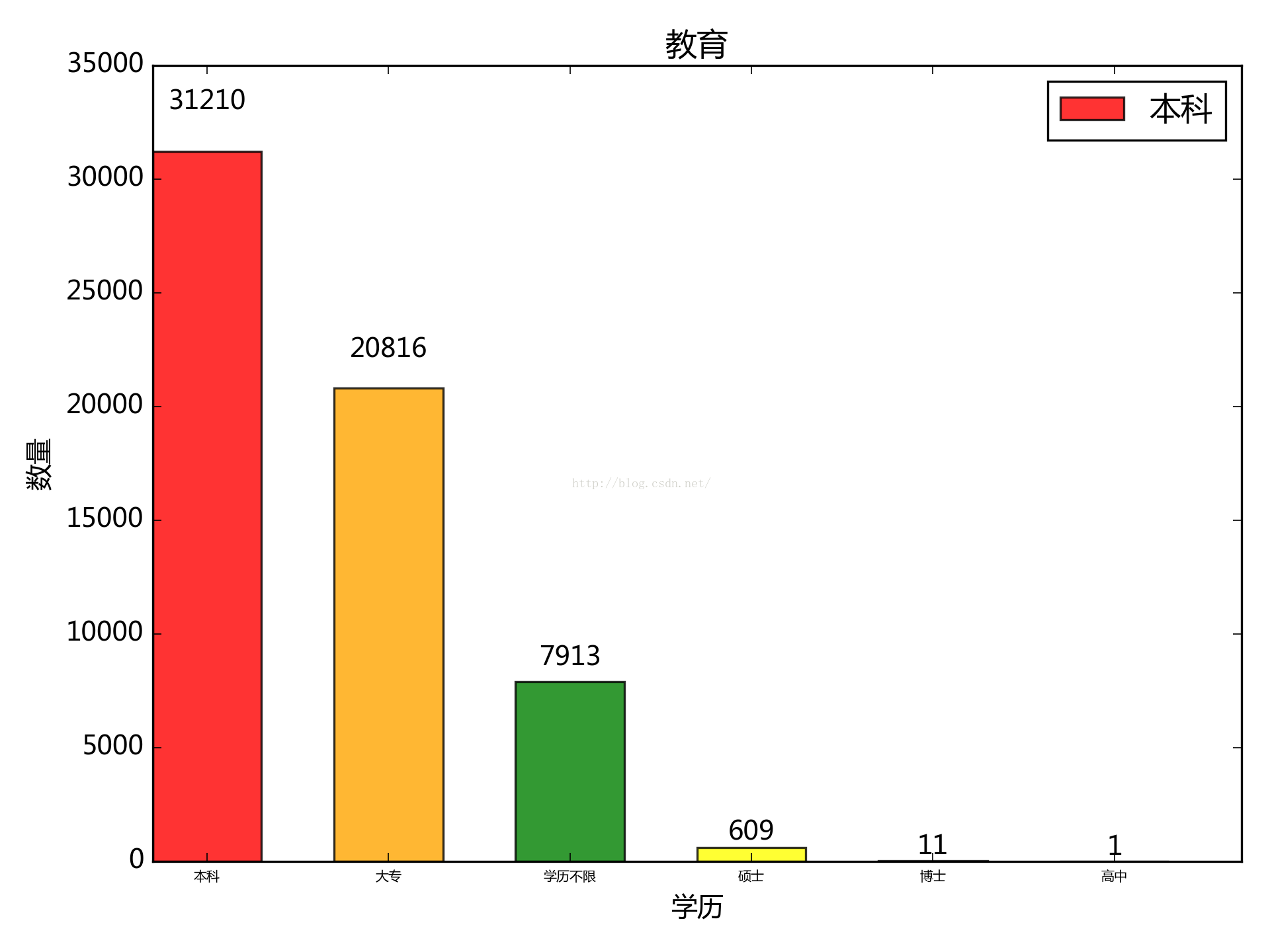
本科佔絕對主力,大專次之,看來這行還是有一定的門檻
4. 按行業領域來看:
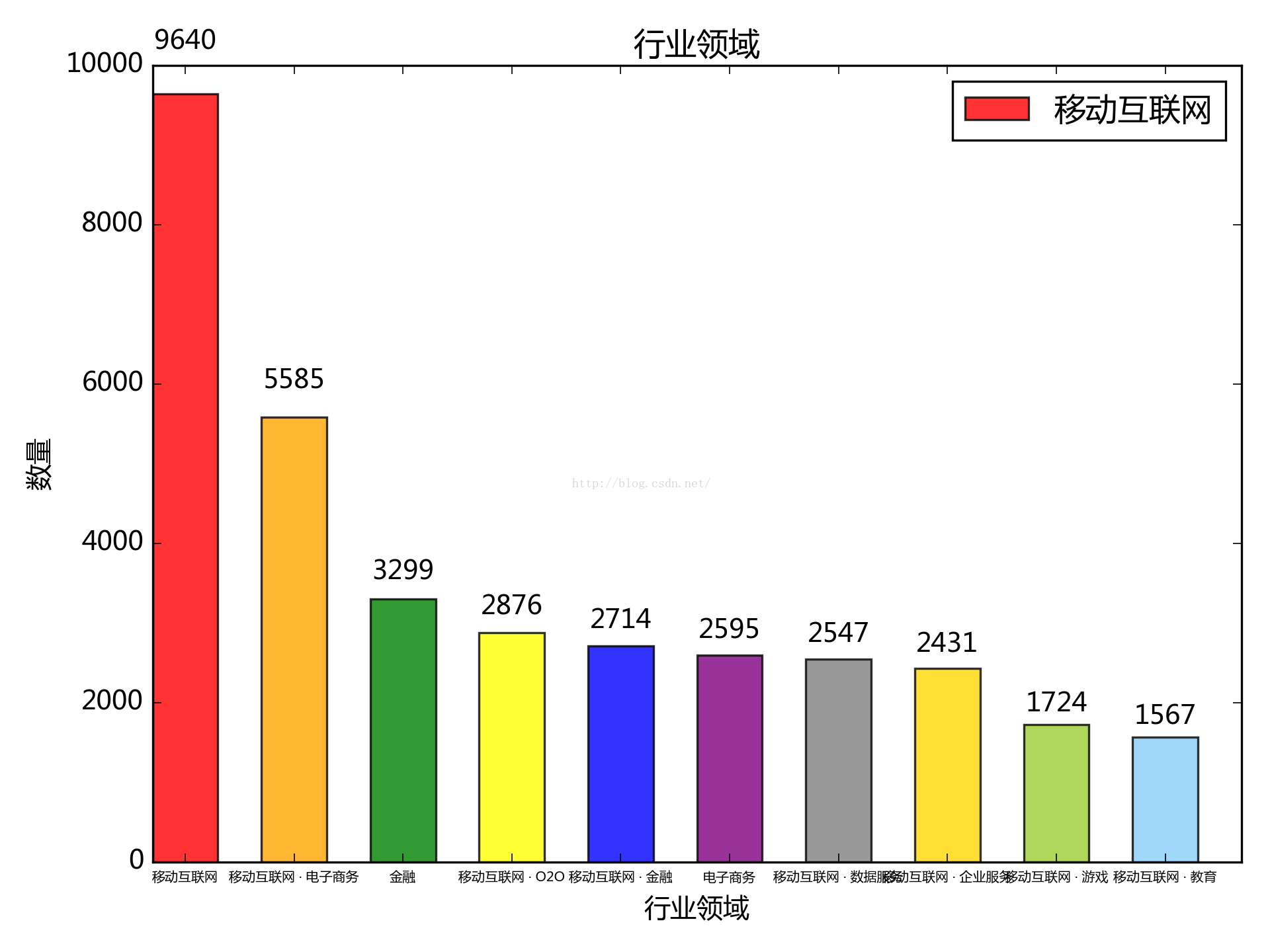
移動網際網路佔絕對統治地位,這是響應“大眾創業,萬眾創新”的網際網路+?
5. 按職位型別來看:
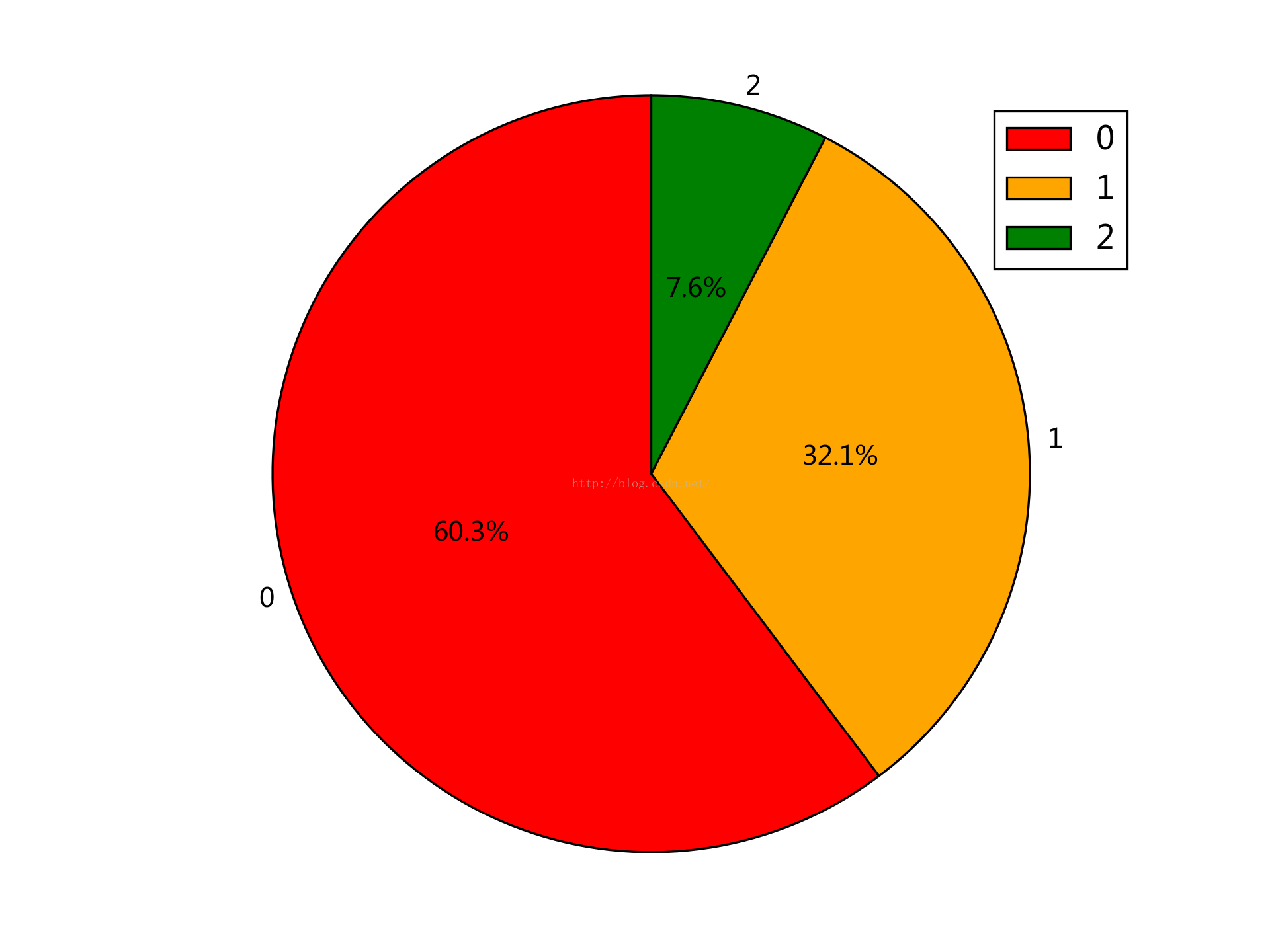
0,1,2分別是後端,前端和移動端,照資料來看後端需求明顯旺盛
6. 按職位名稱來看:(應為廈門的)
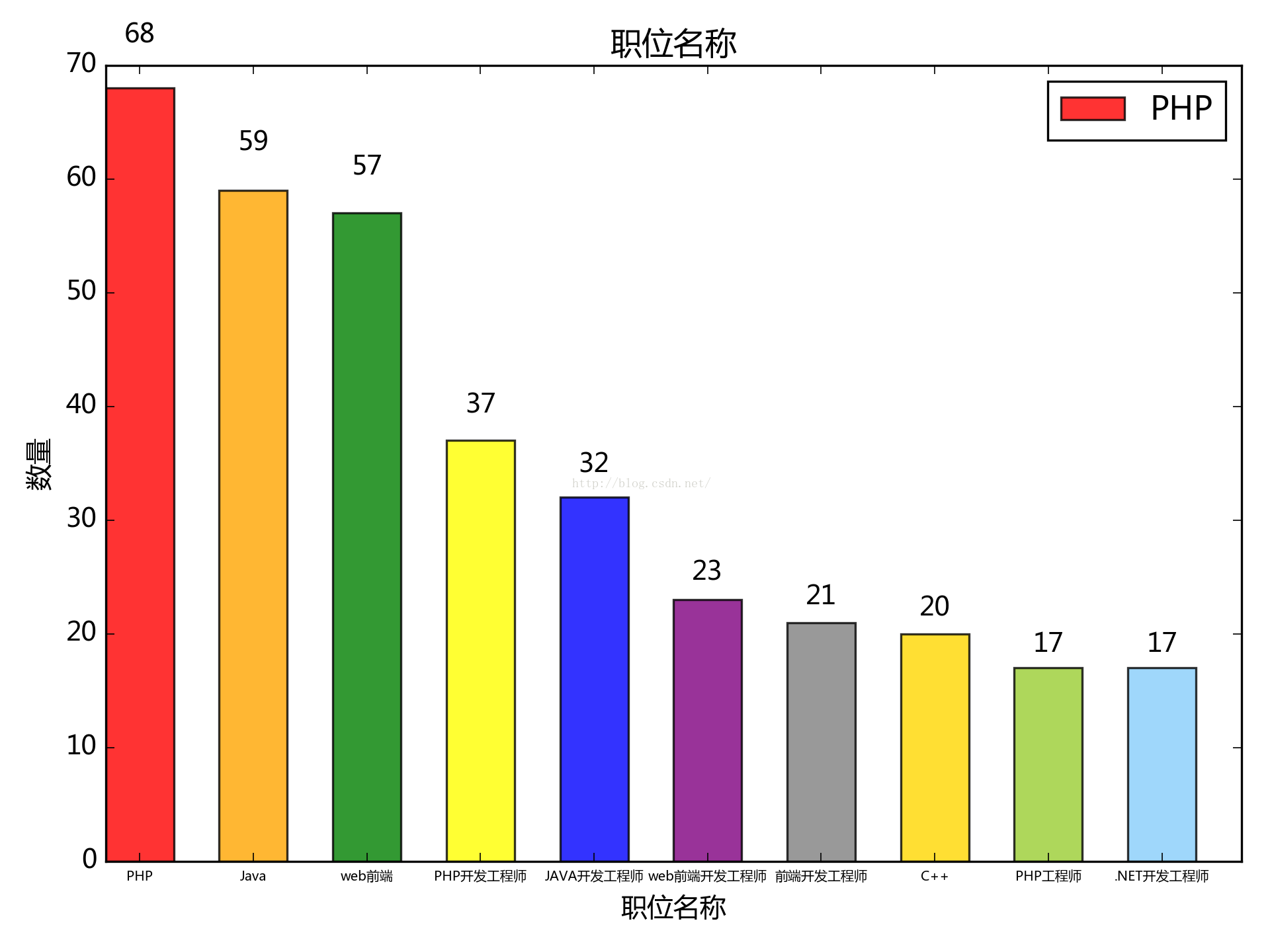
php跟java居多,c++看來需求疲軟
7. 按職位要求最低年限來看:
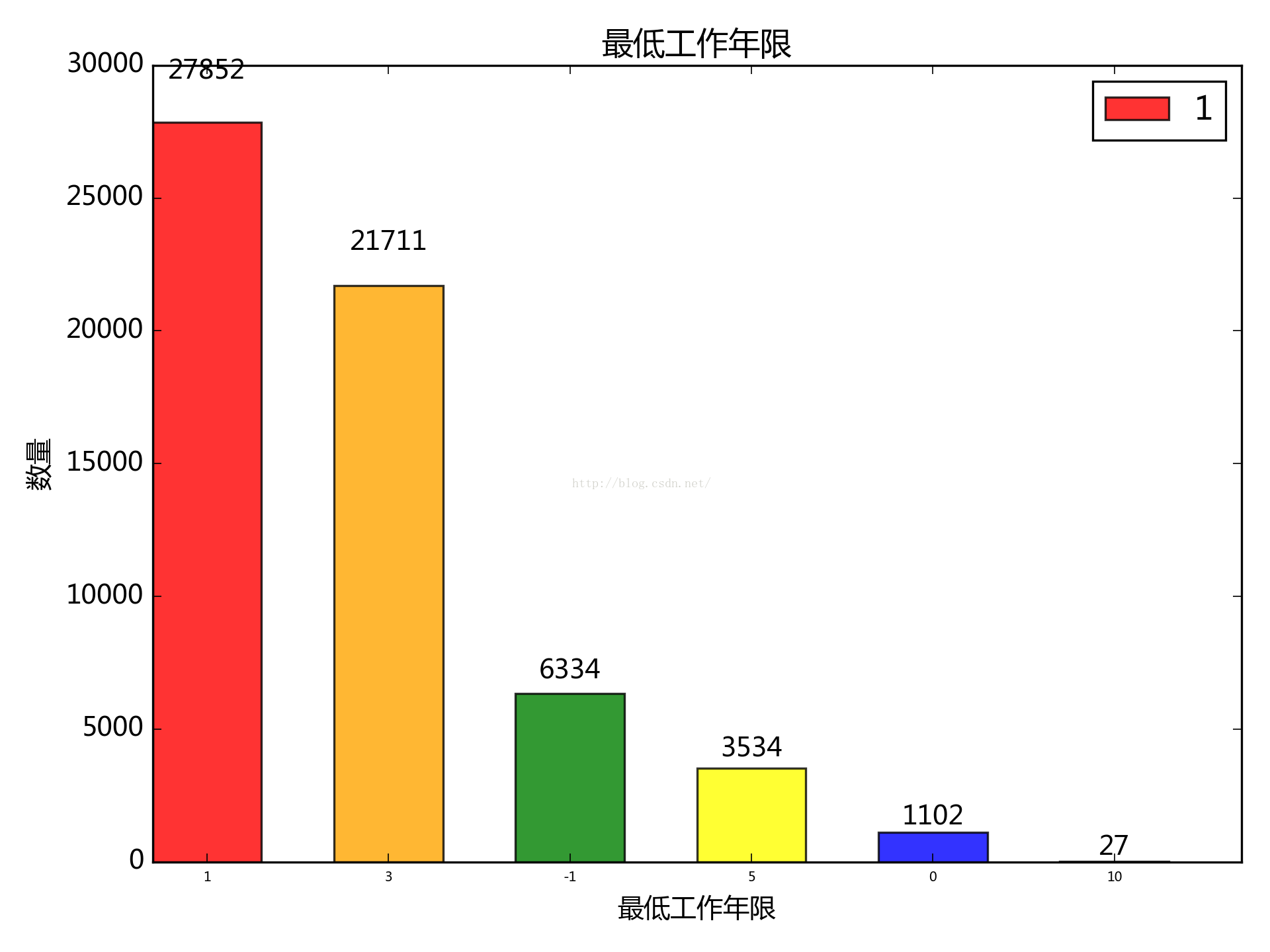
-1表示不限,集中在1~3年,10年以上的鳳毛麟角
8. 按最低起薪來看:
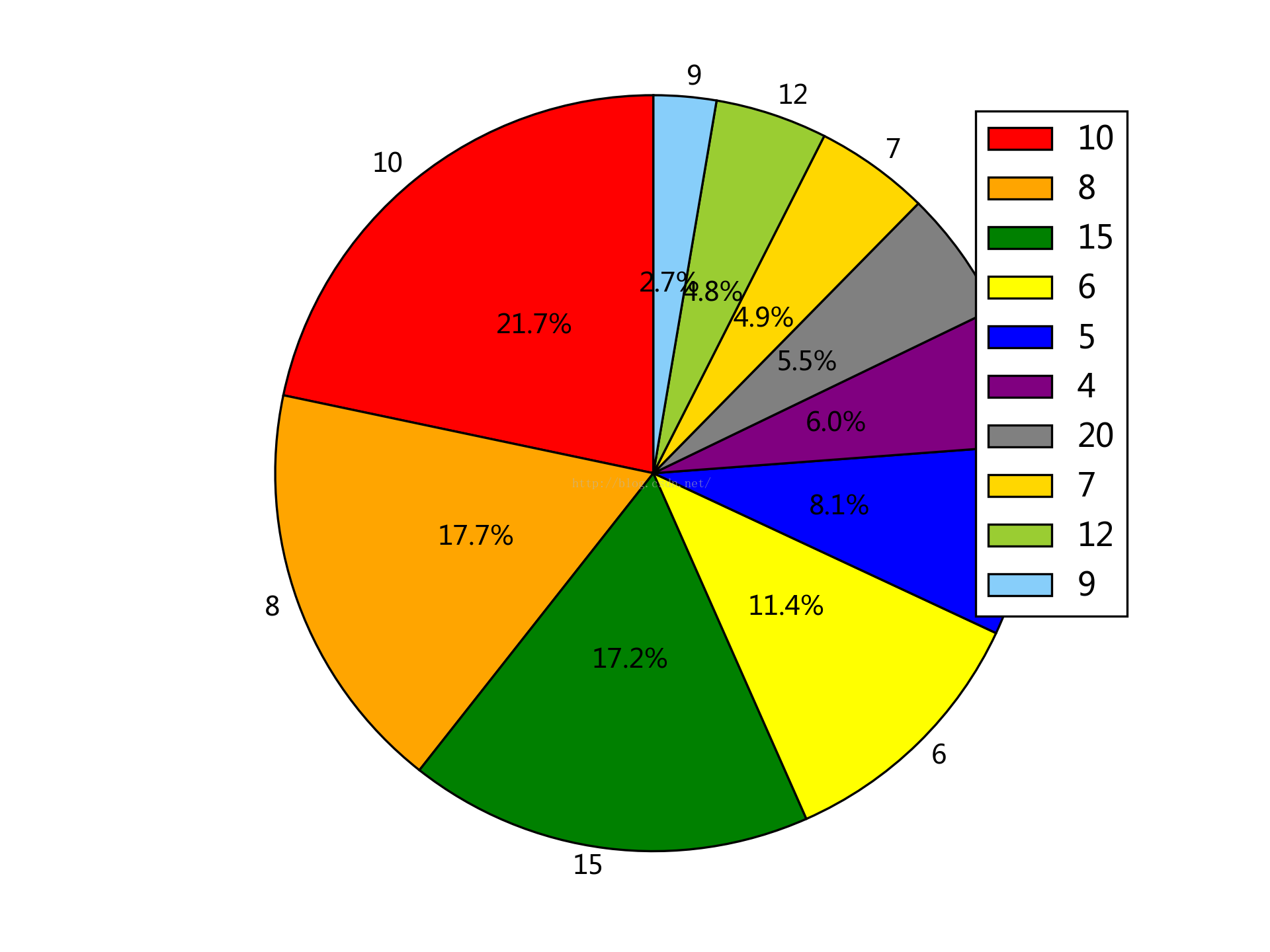
8-15k的佔了一半以上,相對其它行業來說還是不錯的
對於廈門這種二線城市又是什麼樣的情況呢,統計顯示如下:
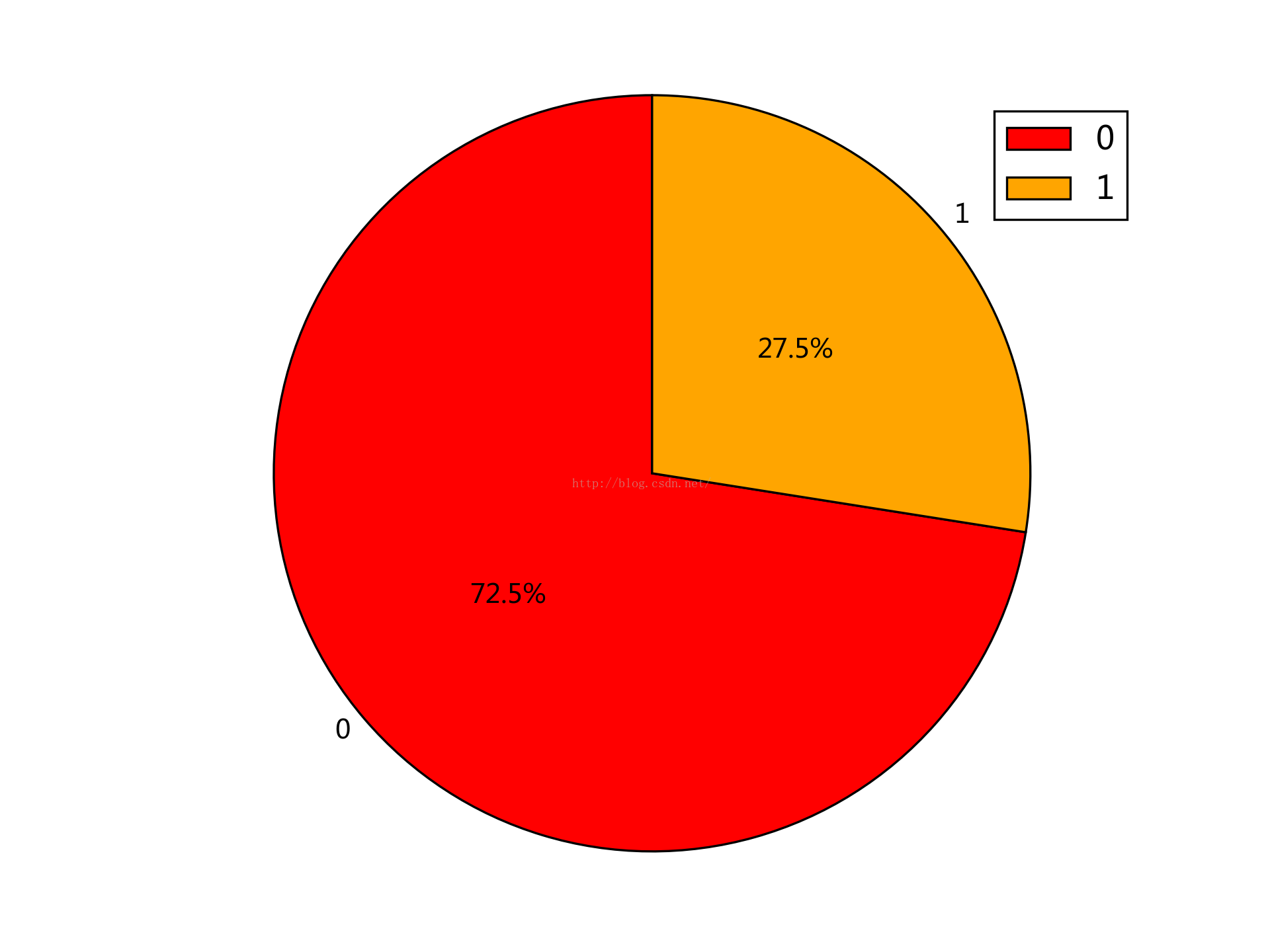
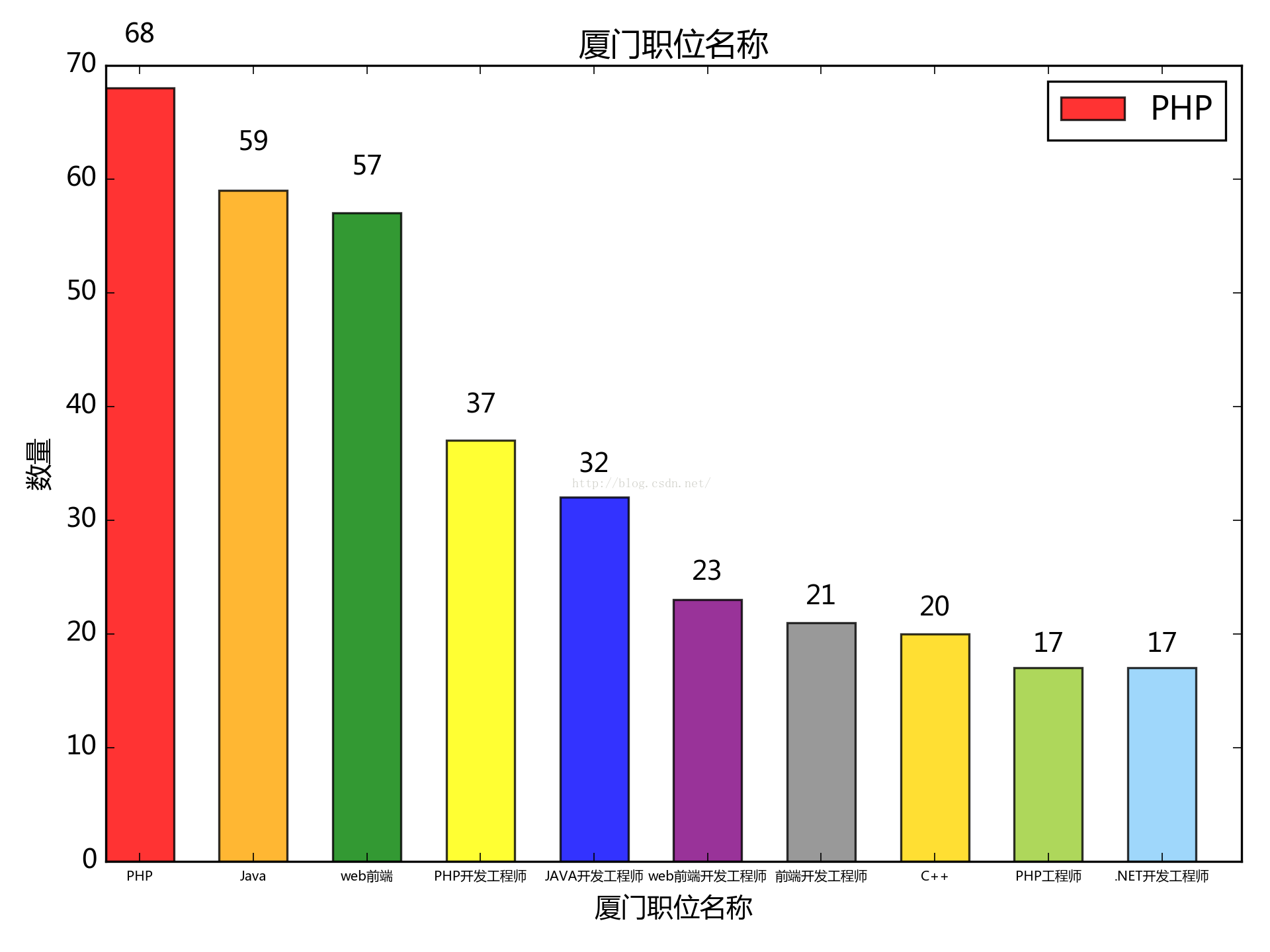
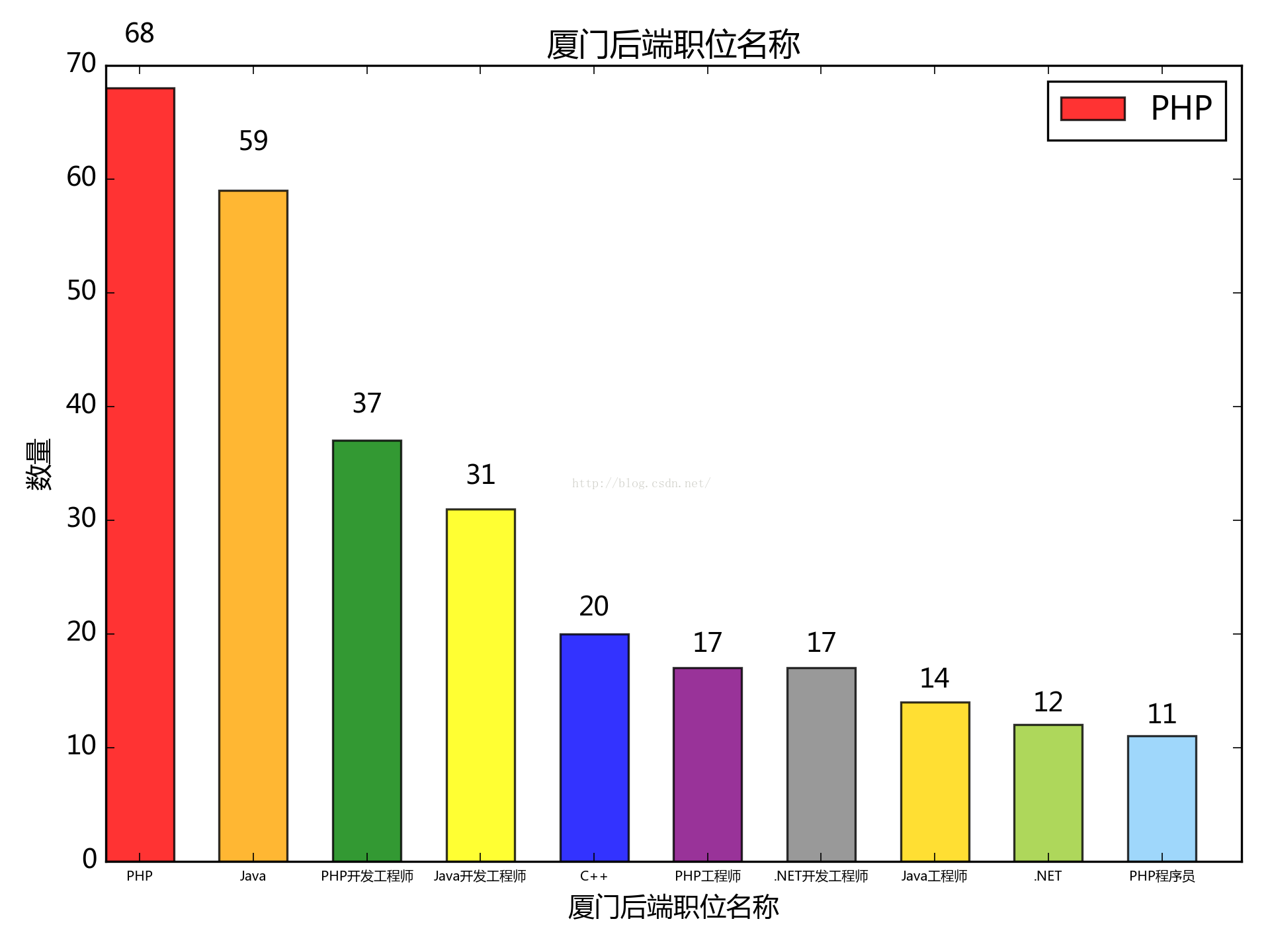
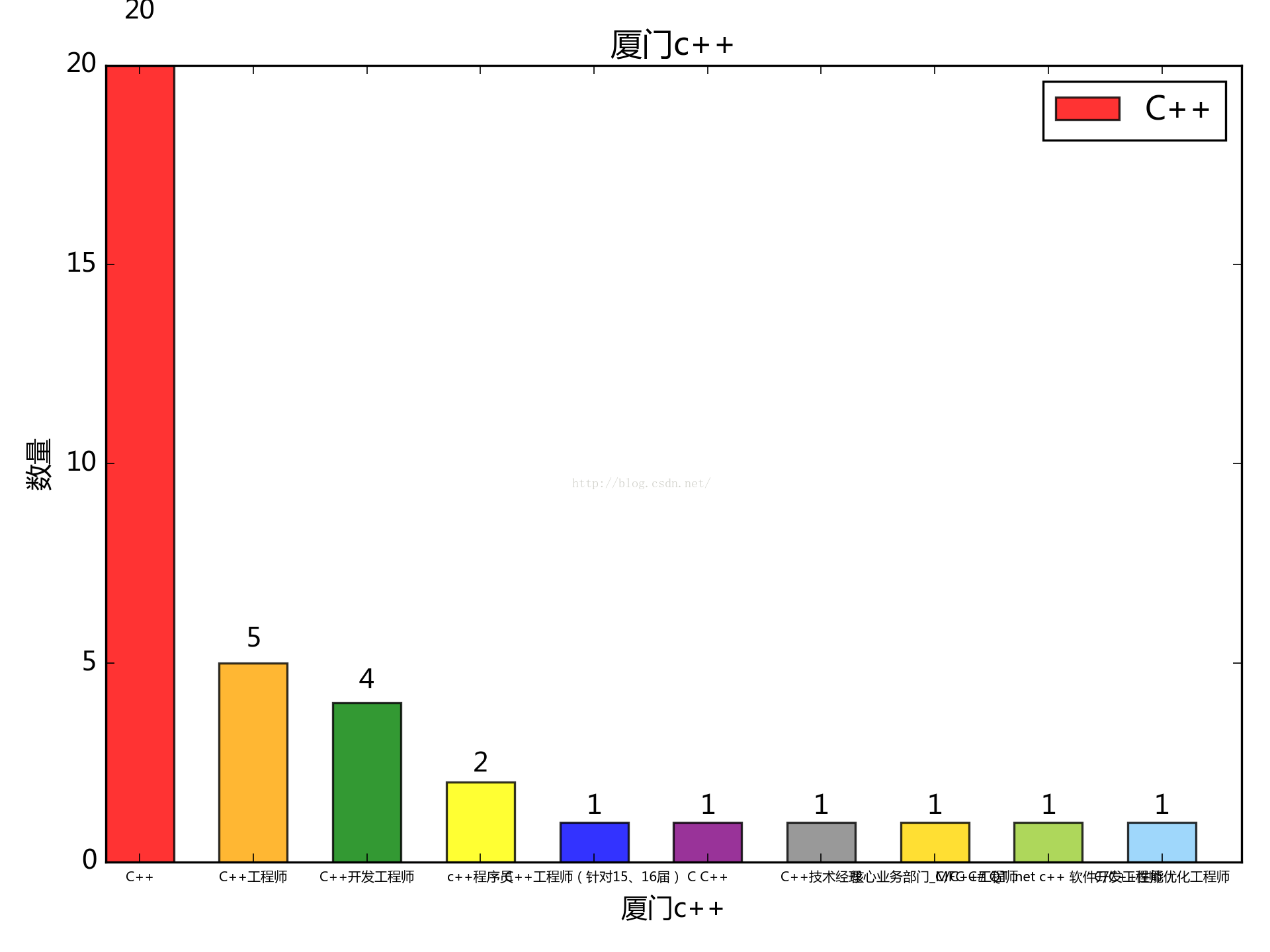
表示c++程式猿已無力吐槽
專案地址:https://github.com/chimmu/python
相關推薦
python3抓取到的拉勾資料統計
趁著最近有時間寫了個拉勾爬蟲抓取了後端、前端和移動端技術崗位的資料,總共大約6多萬條記錄,對其取前十名進行統計 按地域劃分: 可以看出北上廣深杭的數量遠遠超出其它城市,機會相對較多 2. 按融資階段來看: 初創型未融資的居多,已上市及A輪的差不多,C輪是最少的,難道就是
python 爬蟲2-正則表達式抓取拉勾網職位信息
headers mode data .cn 保存 time exc href ace import requestsimport re #正則表達式import time import pandas #保存成 CSV #header={‘User-Agent‘:‘M
scrapy抓取拉勾網職位信息(一)——scrapy初識及lagou爬蟲項目建立
報錯 中間鍵 方式 set 分享圖片 生成 pytho 薪酬 color 本次以scrapy抓取拉勾網職位信息作為scrapy學習的一個實戰演練 python版本:3.7.1 框架:scrapy(pip直接安裝可能會報錯,如果是vc++環境不滿足,建議直接安裝一個visua
scrapy抓取拉勾網職位資訊(一)——scrapy初識及lagou爬蟲專案建立
本次以scrapy抓取拉勾網職位資訊作為scrapy學習的一個實戰演練 python版本:3.7.1 框架:scrapy(pip直接安裝可能會報錯,如果是vc++環境不滿足,建議直接安裝一個visual studio一勞永逸,如果報錯缺少前置依賴,就先安裝依賴) 本篇
scrapy抓取拉勾網職位資訊(四)——對欄位進行提取
上一篇中已經分析了詳情頁的url規則,並且對items.py檔案進行了編寫,定義了我們需要提取的欄位,本篇將具體的items欄位提取出來 這裡主要是涉及到選擇器的一些用法,如果不是很熟,可以參考:scrapy選擇器的使用 依舊是在lagou_c.py檔案中編寫程式碼 首先是匯入Lag
python3 利用requests爬取拉勾網資料
學習python,瞭解了一點爬蟲的知識,成功的對拉勾網的招聘資訊進行了爬取,將爬取心得記錄下來,和大家一起學習進步。 準備工作: python3 requests pandas 谷歌瀏覽器(或者火狐瀏覽器、qq瀏覽器)
python爬取 拉勾網 網際網路大資料職業情況
爬取拉勾網資訊 資料處理 製圖 所需知識只有一點點(畢竟是個小白): requests基礎部分 json pyecharts wordcloud 接下來開始敲程式碼了,程式碼分成了3個部分:爬取、製圖、生成詞雲 爬取部分: 首先要說明的是,拉勾網有反爬
Python爬蟲:爬取拉勾網資料分析崗位資料
1 JSON介紹 JSON(JavaScript Object Notation)已經成為通過HTTP請求在Web瀏覽器和其他應用程式之間傳送資料的標準格式之一。比CSV格式更加靈活。Json資料格式,非常接近於有效的Pyhton程式碼,其特點是:JSON物件所
python爬取拉勾網資料儲存到mysql資料庫
環境:python3 相關包:requests , json , pymysql 思路:1.通過chrome F12找到拉鉤請求介面,分析request的各項引數 2.模擬瀏覽器請求拉鉤介面 3.預設返回的json不是標準格式 ,
爬取拉勾熱門城市“資料分析”崗位,並進行視覺化分析
首先,寫一個爬取崗位的爬蟲,如下:# -*- coding:utf-8 -*- from json import JSONDecodeError import requests import time import pandas as pd # 獲取儲存職位資訊的json
Python多程序抓取拉鉤網十萬資料
準備 安裝Mongodb資料庫 其實不是一定要使用MongoDB,大家完全可以使用MySQL或者Redis,全看大家喜好。這篇文章我們的例子是Mongodb,所以大家需要下載它。 在Windows中。由於MongoDB預設的資料目錄為C:\data\db,建議大家直接在安裝的時候更改預設
爬取拉勾網,並進行資料分析
拉勾網是現在網際網路招聘比較火熱的一個網站,本篇文章主要是爬取拉勾網“資料分析師”這個崗位,並且對所爬取到的資訊,進行資料分析。 資料採集 拉勾網的崗位資訊主要是用json檔案儲存,在position這個json檔案中,我們找到了所需要的崗位資訊
Python爬取拉勾網資料(破解反爬蟲機制)
人生苦短, 我學 Python! 這篇文章主要記錄一下我學習 Python 爬蟲的一個小例子, 是爬取的拉勾網的資料. 1.準備 配置 Python 環境什麼的就不說了, 網上教程很多, 自行解決. 2.扒原始碼 先開啟拉勾網的網頁. 我們要爬取這部分的資料
如果你不會Python多程序!那你會爬蟲?扯淡!抓取拉鉤網十萬資料
這篇文章我們來抓取 拉鉤網 的招聘資訊。全部抓取大概十幾萬條全國招聘資訊,並且儲存資料庫。準備安裝Mongodb資料庫其實不是一定要使用MongoDB,大家完全可以使用MySQL或者Redis,全看大家喜好。這篇文章我們的例子是Mongodb,所以大家需要 下載 它。最後我們需要開啟管理員許可權的 CMD 視
python爬取拉勾網資料並進行資料視覺化
爬取拉勾網關於python職位相關的資料資訊,並將爬取的資料已csv各式存入檔案,然後對csv檔案相關欄位的資料進行清洗,並對資料視覺化展示,包括柱狀圖展示、直方圖展示、詞雲展示等並根據視覺化的資料做進一步的分析,其餘分析和展示讀者可自行發揮和擴充套件包括各種分析和不同的儲存方式等。。。。。 一、爬取和分析
python設置代理IP來爬取拉勾網上的職位信息,
chrome https htm input post 進行 work port ota import requests import json import time position = input(‘輸入你要查詢的職位:‘) url = ‘https://www
python3 requests 獲取 拉勾工作數據
.post ict web data cit industry utf-8 wow64 first 1 #-*- coding:utf-8 -*- 2 __author__ = "carry" 3 4 import requests,json 5 6 fo
python3 抓取圖片
urllib def tao baidu taobao read ont all pytho import reimport urllib.request# import urllibimport osdef getHtml(url): page = urllib.r
scrapy的簡單應用-抓取鏈家資料
最近使用scrapy 抓取一批資料,就拿鏈家實驗一下吧 環境準備 pip install scrapy 基本命令 建立專案 scrapy startproject myproject 執行某個專案 scrapy crawl myspider 如何
抓取微博資料,如何防護爬蟲被牆
大資料時代下,資料採集推動著資料分析,資料分析推動發展。但是在這個過程中會出現很多問題。拿最簡單最基礎的爬蟲採集資料為例,過程中就會面臨,IP被封,爬取受限、違法操作等多種問題,所以在爬去資料之前,一定要了解好預爬網站是否涉及違法操作,找到合適的代理IP訪問網站等一系列問題。下面分享一些爬取微博資料時,防太陽