
漫談redis在運維資料分析中的去重統計方式

今天,我和大家分享下redis在運維資料分析中的去重統計方式。為了避免混淆,本文中對於redis的資料結構做如下約定:
SET:saddkey member
ZSET:zaddkeyscoremember
HYPERLOGLOG:pfaddkeyelement
STRING:setbitkeyoffset value
名詞約定:
維度:比如版本、作業系統型別、作業系統版本、運營商、裝置型號、網路型別等
複合維度:由兩個或多個維度交錯產生的維度,比如某個版本下的某個裝置型號。
去重統計在資料化運維的指標計算環節,並不是一個陌生的字眼,甚至可以說,在大部分的資料指標的中間計算過程中,最終會分為以下幾種資料集:
最大,最小,穩定性,疊加,去重統計。
這5種指標前面4種在實時處理框架或者大部分nosql中使用相對較小的開銷即可完成計算,基礎指標計算的大部分計算瓶頸還是落在io上面,而導致io瓶頸的問題源自於資料維度的劃分與聚合,特別是對於去重統計型別的資料,如果有一種需要實時顯示的去重指標,維度的切分對於io上的開銷簡直是一種災難。
例如,假定我們需要獲取手機終端中某個應用版本中的某個裝置型號或者某個系統的活躍裝置數。那麼,目前市場中的裝置型號有幾百種,各種系統版本x系統型別也有很多,對指標的去重統計來說每多一個維度,需要的記憶體開銷就要多上一倍,2個維度交叉產生的複合維度可能多達上百個,3個維度的交叉產生的複合維度可能數以千計。
因此,對於實時顯示的去重統計型別指標,最好的處理方式是在設計時儘量規避這種指標。如果實在無法規避,我們需要做的犧牲一部分插入時的效能或者空間上的效能換來該部分指標在讀取時不是o(n)的。
下面簡單介紹幾種在開發中基於redis研究出來的幾種資料去重方式。
1.於set的去重統計
這種結構的資料應該是最好理解的統計方式,也是常規的統計方式之一,直接把要去重的部分作為member插入一個set中,需要統計的時候直接使用scard統計該資料集的基數,對於時間等維度資訊,可以放在key中,然後拿取的時候通過拼接維度欄位的形式拿取。
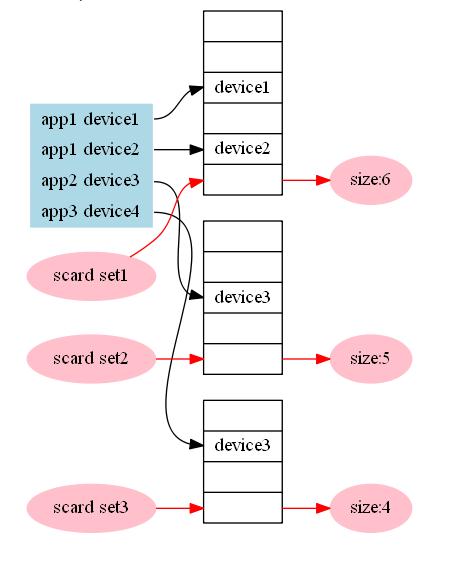
優點:
使用簡單,統計精確。
缺點:無法達成實時統計的功能,要一分鐘統計一次的話需要使用expire命令設定一個很短的回收時間,單一維度時佔用空間過大,資訊聚合成本過大,有幾個維度就需要幾倍的記憶體空間,3個以上覆合維度時基本不需要考慮此方案。
適用場景:需要統計的去重內容的基數非常小的情況下可以考慮,在優雲mobile中,對於使用者基數較小的影響裝置數的計算採用了此種方式。
2.基於zset的去重統計
傳統的基於跳錶/B樹的統計方式,key為維度資訊,score為時間,member為裝置id等原子資訊,通過zcount可以拿取所有的成員數量。
優點:插入和統計都是o(log(N))的,可以精確統計從現在開始到某個時間點的使用者,可以保留原子資料。
缺點:
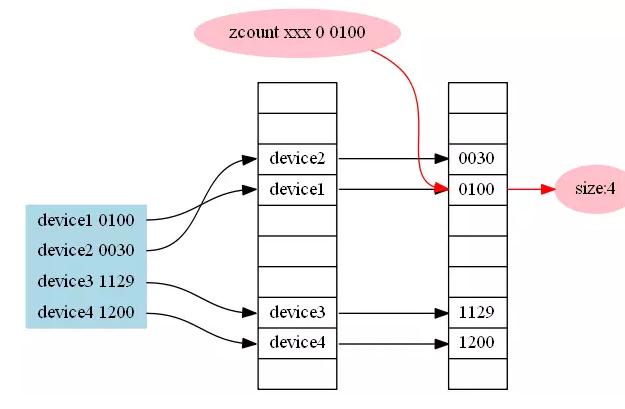
只能自定義時間域上的左區間,對於右區間只能定義為現在時間,否則會出現統計值比實際值偏小的情況(因為同一個裝置如果出現兩次,則會移除舊的那條),單一維度時佔用空間過大,有幾個維度就需要幾倍的記憶體空間,3個以上覆合維度時基本不需要考慮此方案。
適用場景:對於檢視從現在開始1分鐘5分鐘10分鐘等各種時間跨度的使用者基數時可以考慮,在優雲mobile中,採用了這種方案來統計活躍裝置數,早期開發時我們將各種時間維度和各種複合維度全部放在了redis中,結果發現記憶體開銷過大,現在的版本我們只存放了最近2分鐘的一些簡單維度的資料。
3.基於bitset的去重統計
將終端使用者id對映為一個bitset上的一個bit,利用現代處理器的特性進行快速計算。
優點:統計結果精確,對於不同維度可以使用and或者or進行聚合,資料具有原子性,通過較少的操作即可做到跨維度的計算。
缺點:
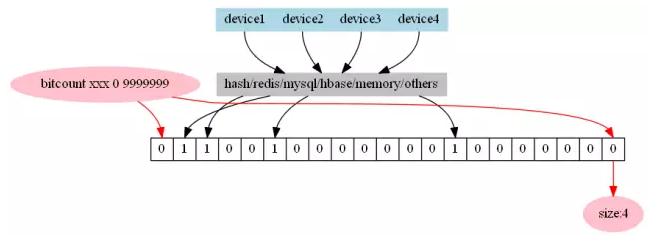
不適用於分鐘級別的統計,並且使用者id的對映較為麻煩。如果使用hash的方式進行對映,將會不可避免的產生hash碰撞,如果使用使用者id進行對映,那麼必然需要維護一份使用者id對映表,這份對映表放在記憶體中會佔用大量空間,放在磁碟中則會導致整個系統的處理速率降低。
備註:java中的bitset在一個byte位元組上是由低位到高位進行儲存,redis中則是由高位到低位進行儲存。
適用場景:適用於需要儲存原子資料並進行較大時間跨度或者自由拼接時間跨度聚合的場景。
4.基於hyperloglog的去重統計
hyperloglog是一種基於概率的統計方式,在redis的2.8.9版本後出現的新資料結構
詳細的內容可以檢視這幾篇文章:
http://blog.codinglabs.org/tag.html#基數估計
優點:每個hyperloglog只需要12K的空間,並且誤算率只有0.81%,不同的紀錄之間可以進行聚合,也就是可以通過聚合統計出任意時間範圍的去重結果,統計單個hyperloglog時時間複雜度為o(1)。
缺點:對於統計結果要求較為精確的場合並不是非常適用
適用場景:在對誤算率要求不高的情況下,同bitset。
5.基於布隆過濾器的去重統計
布隆過濾器是一種改良的bit對映方案,通過使用多種不同的hash種子,可以做到在較低誤判率以及較高的空間利用率的情況下進行統計,redis中並沒有布隆過濾器這個資料結構,不過可以通過lua指令碼的方式實現一個布隆過濾器,詳細原始碼可見
https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter1
優點:
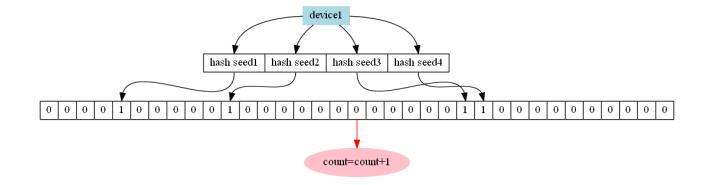
對於200萬用戶不超過萬分之一誤算率的統計,只需要8M左右redis記憶體即可完成統計,萬分之一的誤算率是在插入的不同裝置數達200萬次時才擁有的誤算率,在這之前的誤算率是從0開始線性增長的,在大多數情況下這個誤算率應該是可以容忍的。
缺點:布隆過濾器的統計結果無法聚合
適用場景:對於一些需要實時顯示的內容並且維度較少的內容,可以採用此資料結構,在優雲mobile中,總覽頁面的活躍裝置數採用了此方案來實時顯示今日活躍裝置數。
作者簡介:胡翀,廣通軟體旗下--優雲軟體打雜初級java開發工程師一枚,現任優雲大資料平臺開發工程師,負責統計平臺的資料的分析和儲存。
優雲軟體:秉承devops的理念,從監控、到應用體驗,到自動化持續交付,全棧運維解決方案服務商