
動態連通性之union-find演算法步步優化
設計和分析演算法,主要強調以下幾點:
- 優秀的演算法因為能夠解決實際問題而變得更為重要;
- 高效演算法的程式碼也可以很簡單;
- 理解某個實現的效能特點是一項有趣而令人滿足的挑戰;
- 在解決同一個問題在多種演算法之間進行選擇時,科學方法是一種重要的工具;
- 迭代式改進能夠讓演算法的而執行那個效率越來越高.
我們會不斷鞏固這些思想,本節的例子只一個原型.它將為我們用相同的方法解決許多其他問題打下基礎.
動態連通性
什麼是動態連通性問題
首先我們詳細說明一下問題:問題的輸入是一列整數對,其中每個整數都表示一種型別的物件,一對整數 p q可以理解為”p和q是相連的.”我們假設相連是一種等價關係,這也就意味著它具有:
- 自反性:p和q是相連的
- 對稱性: 如果p和q相連,那麼q和p也是相連的.
- 傳遞性:如果 p和q相連,q和r相連,那麼p和r也是相連的.
等價關係能夠將物件分為多個等價類.在這裡當且僅當兩個物件相連時他們才屬於同一個等價類.
我們的目標時編寫一個程式來過濾掉序列中所有無意義的整數對(兩個整數均來自一個等價類中).換句話說,當程式從輸入中讀取了整數對 p q 後,如果一直所有整數對都不能說明p和q是相連的,那麼則將這一對整數寫入到輸出中.如果已知的資料可以說明p和q是相連的,那麼程式忽略p和q這對整數對,繼續處理下一個整數對.
為了達到所期望的效果,我們需要設計一個數據結構來儲存程式已知的所有整數對的資訊,並用他們判斷一對新物件是否是相連的.我們講這個問題通俗的叫做 動態連通性 問題.
網路
連通性問題可以有一下應用.輸入中的整數對錶示的可能是一個大型計算機網路中的計算機,而整數對則表示網路中的連線,這個程式可以判斷我們是否需要在p和q之間架設一條連線才可以通訊,或是我們可以通過已有的連線在兩者之間建立通訊線路;或者這些整數可能表示電子電路中的觸點,而整數對錶示連線觸點之間的電路;或者這些整數可能表示社交網路中的人,而整數對錶示的是朋友關係.在此類應用中,我們可能需要數百萬的物件和數十億的連線.
- 為了進一步限定話題,我們會在本節以下內容中使用網路相關的術語.將物件成為觸點,將整數對成為連線,將等價類成為連通分量或者簡稱為分量.簡單起見,假設我們有用到 0到N-1 的整數所表示的N個觸點.這樣做並不會降低演算法的通用性,因為我們在後面的文章中將會學習一組高效的演算法,將整數識別符號和任意名稱關聯起來.
連通性問題只要求我們的程式能夠判別給定的整數對 p q是否相連,但並沒有要求給出兩者之間通路上的所有連線.這樣的要求會使問題更加複雜,並得到另一組不同的演算法.我們會在後面關於 圖的講解中使用到它.
union-find演算法
union-find的程式碼實現
package 動態連通性;
public class UF {
private int [] id;//分量id(以觸點為索引)
private int count;//分量數量
public UF(int N){
//初始化分量ID陣列
count =N;
id = new int[N];
for(int i=0;i<N;i++){
id[i] = i;
}
}
/**
* 連通分量的數量
* @return
*/
public int count(){
return count;
}
/**
* 如果p q之間存在一條分量,則返回true
* @param p
* @param q
* @return
*/
public boolean connected(int p,int q){
return find(p) == find(q);
}
/**
* p所在分量的識別符號
* @param p
* @return
*/
public int find(int p){return 0;}//暫未實現
/**
* 在p和q之間新增一條連線
* @param p
* @param q
*/
public void union(int p,int q){}//暫未實現
}
我們可以看到,為解決動態連通性問題設計演算法的任務轉化為了實現這份API.

眾所周知,資料結構的性質將直接影響演算法的效率,因此資料結構和演算法的設計是密切相關的.API已經說明觸點和分量都會用int表示,所以我們可以用一個 以觸點為索引的陣列id[] 作為基本資料結構來表示所有的分量. 我們將使用分量中某個觸點的名稱作為分量的識別符號,因此你可以認為每個分量都是它的觸點之一所表示的. 一開始我們有N個分量,每個分量都構成了一個只含有他自己的分量,因此我們就那個id[i]的值初始化為i.對於每個觸點i,我們使用find(int p) 方法判斷它所在分量的資訊並儲存在id[i]之中. connectend() 方法的實現只有一條語句 find(p) == find(q) ,他返回的是一個boolean 值.
- quick-find完整程式碼實現
public class UF {
private int[] id;// 分量id(以觸點為索引)
private int count;// 分量數量
public UF(int N) {
// 初始化分量ID陣列
count = N;
id = new int[N];
for (int i = 0; i < N; i++) {
id[i] = i;
}
}
/**
* 連通分量的數量
*
* @return
*/
public int count() {
return count;
}
/**
* 如果p q之間存在一條分量,則返回true
*
* @param p
* @param q
* @return
*/
public boolean connected(int p, int q) {
return find(p) == find(q);
}
/**
* p所在分量的識別符號
*
* @param p
* @return
*/
public int find(int p) {
return id[p];
}
/**
* 在p和q之間新增一條連線
*
* @param p
* @param q
*/
public void union(int p, int q) {
// 將p 和 q 歸併到相同的分量中
int pID = find(p);
int qID = find(q);
// 如果p 和q已經在相同的分量之中則不需要採取任何行動
if (pID == qID)
return;
// 將p的分量重新命名為 q的名稱
for (int i = 0; i < id.length; i++) {
if (id[i] == pID) {
id[i] = qID;
}
count--;
}
}
}
- quick-find演算法分析 在本演算法中,每次find()方法只需要訪問陣列一次,而歸併兩個分量 的union() 操作訪問陣列的次數在(N+3)到(2N+1) 之間,假設我們使用 quick-find 演算法來解決動態連通性問題並且最後只得到了一個連通分量,那麼這需要(N-1)此unoin(),則至少需要 (N+3)*(N-1)–N²次陣列訪問.因此我們馬上就可以知道動態連通性的 該演算法是平方級別的.我們需要尋找更好的演算法
quick-union 演算法
我們討論的下一個演算法的重點是要提高 union() 方法的速度.
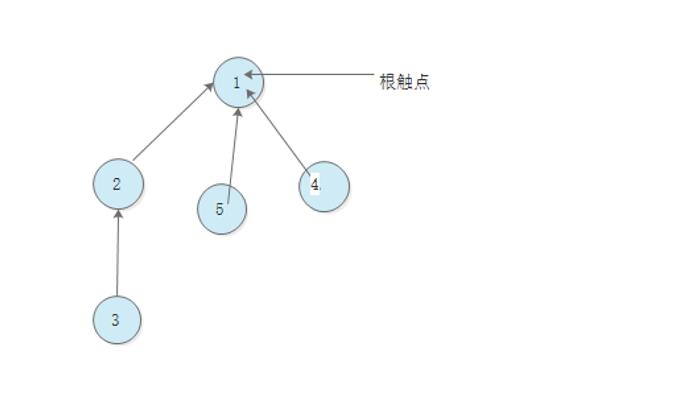
確切的說,每個觸點所對應的id[] 元素都是同一個連通分量中的另一個觸點的名稱(也可能是它自己)—-我們將這種聯絡成為 連結.
在實現find() 演算法時,我們從給定出點開始,由它的連結得到另一個觸點,再由這個觸點連結到第三個觸點,如此繼續跟隨者連結直到達一個根觸點,及連結指向自己的觸點,這樣一個觸點必然存在.
當且僅當分別由這連個觸點開始的這個過程之中到達了同一個跟觸點時,他們才在同一個分量之中.
下面是改進部分的程式碼
/**
* p所在分量的識別符號
*
* @param p
* @return
*/
public int find(int p) {
//找出分量的名稱,跟隨連結找到根節點
while(p!=id[p]) p = id[p];
return p;
}
/**
* 在p和q之間新增一條連線
*
* @param p
* @param q
*/
public void union(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
//將p和q的根節點統一
if(pRoot == qRoot)return;
id[pRoot] = qRoot;
count--;
}find() 方法用來找連結的根節點的名稱.
union() 方法實現很簡單:我們由 p和 q 的連結通過find() 方法分別找到它們的根觸點,然後只需將一個根觸點連線到另一個根觸點即可實現將一個分量重新命名另一個分量. 因此這個演算法叫做 quick-union.
- quick-union 演算法分析
quick-union 演算法看起來比 quck-find 演算法更快,因為它不需要為每對輸入遍歷整個陣列.分析可知:在最佳情況下是線性級別的,在最壞情況下是平方級別的.
目前我們可以將quick-union 演算法看作是對 quick-find演算法的改良,因為它解決的quick-find 演算法中最主要的問題(unio操作總是線性級別的).對於一般的輸入資料,這個演算法顯然是一次進步,但quick-union演算法仍然存在問題,我們不能保證在所有情況下它都比quick-find 快的多.
我們需要對quick-union 演算法繼續改進.
加權 quick-union 演算法
幸好,我們只需要簡單的修改quick-union演算法就能保證像這樣糟糕的情況不會再出現.與其在union() 方法中隨意的將一棵樹連線到另一棵樹.我們現在會記錄每一棵輸的大小並將小叔連線到大樹上面去.這項改動需要新增一個數組和一些程式碼來記錄樹中的節點數.它能夠大大改進演算法的效率,我們稱它為 加權 quick-union 演算法.
package 動態連通性;
public class UF2 {
private int[] id;// 分量id(以觸點為索引)
private int count;// 分量數量
private int[] sz; // 各根節點所對應的分量的大小
public UF2(int N) {
// 初始化分量ID陣列
count = N;
id = new int[N];
sz = new int[N];
for (int i = 0; i < N; i++) {
id[i] = i;
sz[i] = 1;
}
}
/**
* 連通分量的數量
*
* @return
*/
public int count() {
return count;
}
/**
* 如果p q之間存在一條分量,則返回true
*
* @param p
* @param q
* @return
*/
public boolean connected(int p, int q) {
return find(p) == find(q);
}
/**
* p所在分量的識別符號
*
* @param p
* @return
*/
public int find(int p) {
// 找出分量的名稱,跟隨連結找到根節點
while (p != id[p])
p = id[p];
return p;
}
/**
* 在p和q之間新增一條連線
*
* @param p
* @paramUF2.java q
*/
public void union(int p, int q) {
int pRoot = find(p);// 找到其根節點
int qRoot = find(q);
// 將p和q的根節點統一
if (pRoot == qRoot)
return;
// 將小樹的根節點連結到大樹的根節點
if (sz[pRoot] < sz[qRoot]) {
id[pRoot] = qRoot;
sz[qRoot] += sz[pRoot];// 兩樹的節點數相加
} else {
id[qRoot] = pRoot;
sz[pRoot] += sz[qRoot];
}
count--;
}
}
- 加權quick-union 演算法的分析對於加權 quick-union演算法和N個觸點,最壞情況下,find90,connected()和union()演算法的成本的增長數量級為logN .
有了加權 quick-union演算法我們就能夠保證在河裡的範圍內解決十幾種大規模動態連通性問題.只需要多寫幾行程式碼,我們所得到的程式在實際應用中的大型動態連通性問題時就會比簡單的演算法快數百倍.
展望
直觀感覺上,我們學習的每一種UF的實現都改進了上一個版本的實現,但這個過程並不突兀,因為我們可以總結為學者們對這些演算法對年的研究.我們明確的說明了問題,解決方法的實現也很簡單.