
機器學習:AdaBoost演算法及其實現
阿新 • • 發佈:2019-01-01
文章目錄
楔子
前面提到boosting演算法為一類演算法,這一類演算法框架分為3步:1、訓練一個弱分類;2、根據分類結果調整樣本權重;3、最後決策時,根據弱模型的表現來決定其話語權。
那麼這裡面就有2個關鍵點:
1、如何調整樣本權重;
2、如何根據弱模型的表現來決定其話語權。
演算法描述:
adaboost裡的樣本權重和話語權
事實上,能夠將這兩個問題的解決方案有機地糅合在一起、正是 AdaBoost 的巧妙之處之一。
如何調整樣本權重,一個弱分類器得到一個錯誤分類率e > 0.5, 我們調整樣本權重是分類錯誤率等於0.5,用這個樣本權重用於下一個分類器,這個這兩個分類器就不會強相關,這個就是調整樣本權重的主要思想。
分類錯誤樣本權重乘以d倍,分類正確樣本權重處理d,得到e*d = (1-e)/d =====> d^2 = (1-e)/e
我們定義該分類器的話語權為:alpha = ln(d) = 0.5*ln (1-e)/e,話語權是隨著錯誤率的增大而減小的。
事實上,能夠將這兩個問題的解決方案有機地糅合在一起、正是 AdaBoost 的巧妙之處之一。
實際的樣本權重是歸一化處理過的:
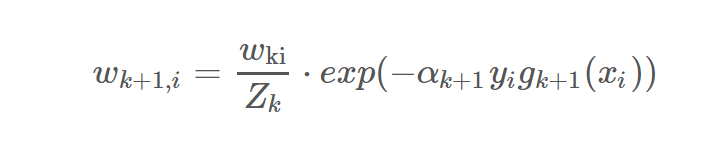
演算法描述

AdaBoost的實現:
實現比較簡單,首先你的分類器需要支援樣本權重,然後按照序列呼叫你的分類器就行了,每次把計算好的樣本權重傳進去。
class AdaBoost:
# 弱分類器字典,如果想要測試新的弱分類器的話、只需將其加入該字典即可
_weak_clf = {
"SKMNB": SKMultinomialNB,
"SKGNB": SKGaussianNB,
"SKTree": SKTree,
"MNB": MultinomialNB,
"GNB": GaussianNB, 數學基礎(瞭解)
AdaBoost 演算法是前向分步演算法的特例,AdaBoost 模型等價於損失函式為指數函式的加法模型。
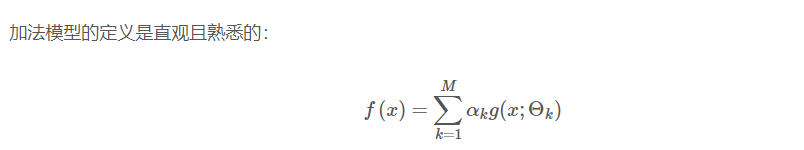
所謂的前向分步演算法,就是從前向後、一步一步地學習加法模型中的每一個基函式及其權重而非將f(x)作為一個整體來訓練,這也正是 AdaBoost 的思想。