
製作自己的yolo2資料集進行訓練
阿新 • • 發佈:2019-01-01
說明
本文承接上一篇修改yolo2相關配置的部落格,用來說明如何製作自己的訓練資料,。主要流程就是手動標註目標資訊了,當然,圖片首先要自己準備好。
注意:本文的識別型別只有1類
工具
- 畫框程式 https://github.com/puzzledqs/BBox-Label-Tool
- 格式轉換程式https://github.com/Guanghan/darknet?files=1 ——主要是用這裡的scripts/convert.py 轉換格式
畫框程式介紹
首先將該程式下載並解壓,會得到一個BBox-Label-Tool-master的資料夾,裡面還有Examples,Images,Labels三個資料夾。
將自己的圖片整合成一個資料夾,然後命名為002(003,004)這種形式,拷貝進Examples和Images裡。(不知道為啥要同時拷到兩個資料夾中,反正我拷到一箇中用不了)
- 通過命令列進入該資料夾,輸入:
python main.py可以得到如下畫面:
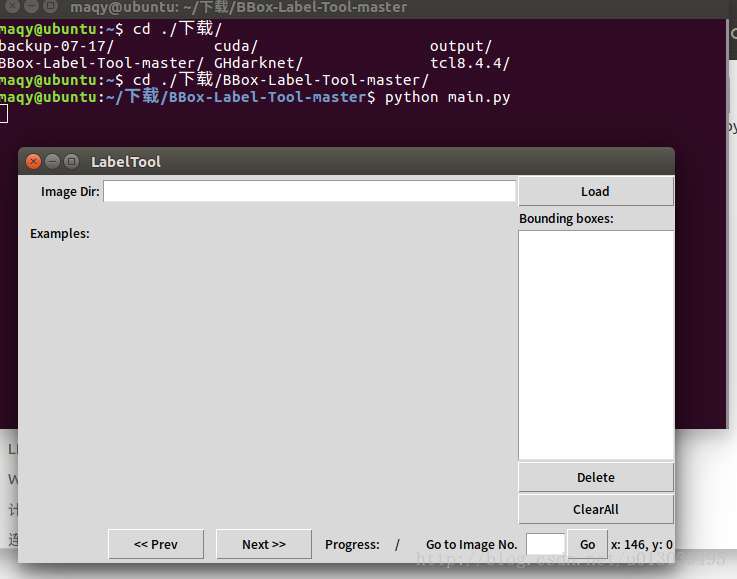
在image Dir的框中輸入2(3,4),就是你拷進去的資料夾名。然後就會顯示影象了,此時就可以開始慢慢的標記了,每標完一張圖要點選“next>>”才會儲存,txt儲存在labels資料夾下。
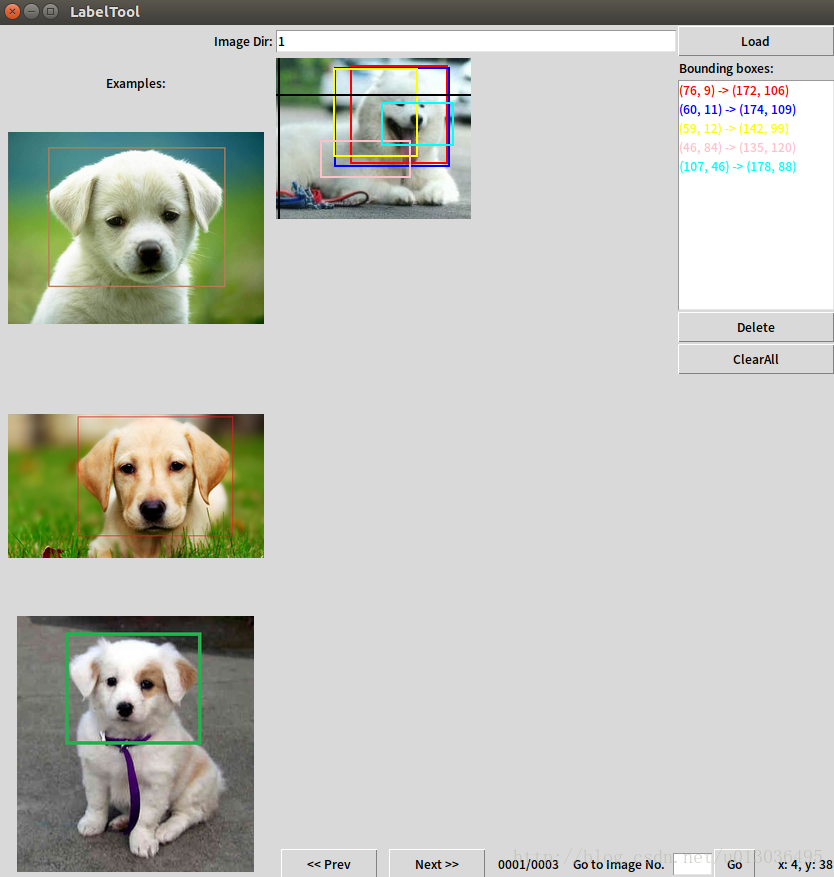
注意:該程式預設只能讀取.JPEG的檔案,如果你的圖片是.jpg是讀取不到的。 解決方法:編輯main.py,用CTRL+F搜尋JPEG,在134行和152行左右修改“.JPEG”為“
標記完成後進入labels資料夾,會出現對應的txt檔案,檔案內容類似如下:
2
112 73 155 154
205 128 277 154第一行表示個數,第二行開始表示框的位置和大小。前兩個數表示框的左上角頂點,後兩個數表示框的長和寬。
現在我們就得到了圖片和相應的標記了,但是還不能開始訓練,因為要將標籤轉化為yolo所需要的格式。
格式轉化程式
首先將該程式下載並解壓,我們僅需用到scripts/convert.py。這裡要修改convert.py,我加中文註釋的地方是需要修改的。
# -*- coding: utf-8 -*-
"""
Created on Wed Dec 9 14:55:43 2015
This script is to convert the txt annotation files to appropriate format needed by YOLO
@author: Guanghan Ning
Email: 然後在scripts/images/目錄下建立一個資料夾,名為程式碼段中修改過的cls的值。
cls = "ship" #修改為自己的類別
(我的即是ship) 的資料夾,將之前進行過標註的圖片拷貝進去。然後在目錄下執行:
python convert.py此時在你的輸出目錄下就有改好的txt檔案了。
準備訓練
回到自己的darknet目錄,進入scripts目錄,將圖片和標籤複製進來,並建立train.txt檔案。
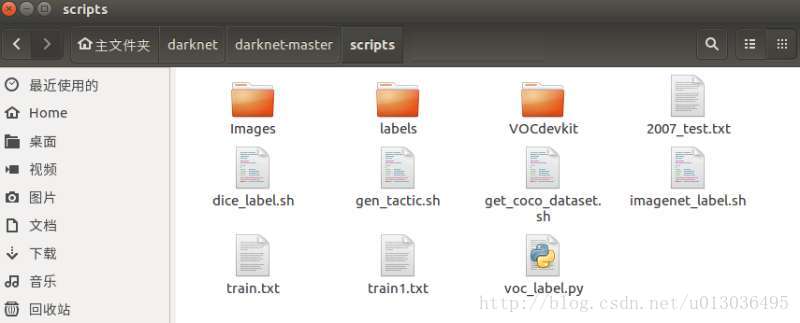
其中Images中儲存的是圖片,labels中儲存的是修改完後的標籤。train.txt中儲存訓練圖片的地址。
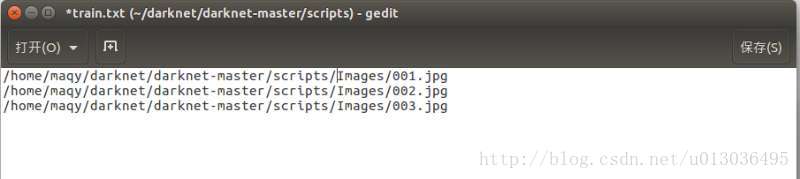
不過建議採取Voc的形式,即在scripts中建立資料夾VOCdevkit/VOC2012/JPEGImages和VOCdevkit/VOC2012/labels,將圖片和標籤分別放入這兩個資料夾。此時train.txt文件為:

開始訓練
首先下載一個預訓練的model(當然你也可以自己生成),放到darkent/目錄下。
下載地址 (76 MB):http://pjreddie.com/media/files/darknet19_448.conv.23
然後執行指令:./darknet detector train cfg/voc.data cfg/yolo-voc.2.0.cfg darknet19_448.conv.23
指令中的yolo-voc.2.0.cfg 可以換成別的網路。就可以開始訓練了,迭代次數為設定的max_batches數。
測試結果
此時在backup目錄下會有很多.weights檔案,利用他們就可以進行檢測了。
./darknet detector test cfg/voc.data cfg/yolo-voc.2.0.cfg ./backup/yolo-voc_final.weights ./data/test/sar10.jpg
其中 cfg/yolo-voc.2.0.cfg替換成你所用的,./data/test/sar10.jpg是用來檢測的影象,修改為自己的路徑即可。