
李巨集毅機器學習2016 第八講 深度學習網路優化小訣竅
Tips for Deep Learning
本章節主要講解了深度學習中的一些優化策略,針對不同的情況適用於不同的優化方法。
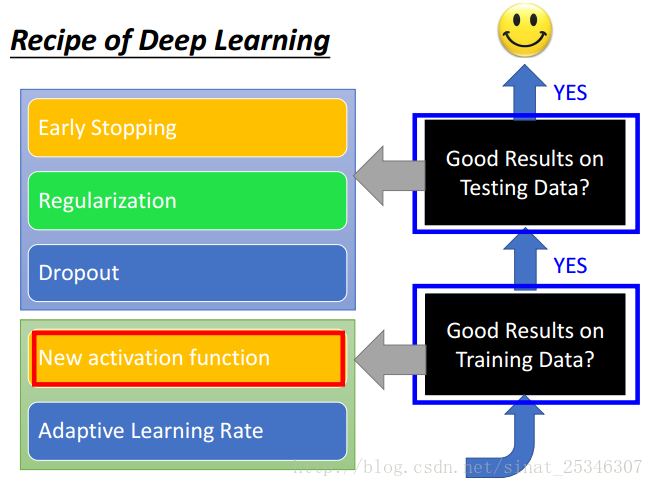
主要內容是:新的啟用函式(new activation function),自適應的學習率(adaptive learning rate),提早停止(early stop),正則化(regularization),丟棄(dropout)。
1.問題定義
在訓練網路的過程中,我們通常的評價標準是網路能否在訓練資料上得到好的結果以及網路能否在測試資料集上取得好的結果。正如我們之前所說,訓練神經網路只需要三步,就好像將大象放進冰箱那麼簡單,第一步定義一個函式集,即網路結構的選擇;第二步是定義評價函式的好壞,即損失函式的選擇;第三部是挑選一個最好的函式,即如果更新權重進行學習。
這裡我們需要注意的一個概念是overfitting,很多時候我們會將網路在測試集上表現不好而稱為過擬合,實際上在此之前需要檢查網路在訓練資料集上的表現是否足夠好。此外,過擬合通常不是我們訓練神經網路遇到的第一個問題,因為在資料量很大很大時,我們也很難能夠達到過擬合,一般會先遇到的問題是網路在訓練資料集上表現不好,這時就需要通過調整網路結構等方法進行優化。
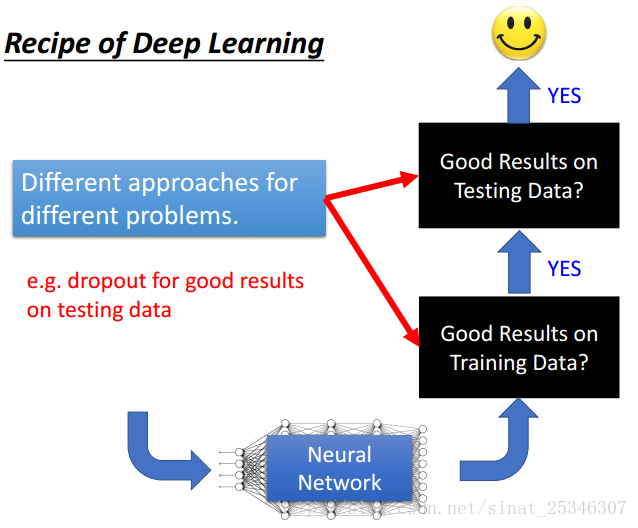
對於不同的情況我們會有不同的優化方法,每種症狀對應的解決方法是不一樣的。在深度學習中,我們要考慮每種方法的使用情況,對應於解決哪些問題。
本章節主要講解了以下方法。
2. New Activation Function
通常如果出現網路效能在訓練資料集上表現不好的時候,我們會調整網路結構,例如增加層數、神經元個數等。但這裡需要注意的問題是越深不代表就會越好。

在此例中,準確率隨著網路的層數反而會下降。這種情況並不能說因為函式太複雜了就是overfitting,因為過擬合一定要看其在訓練資料上的表現,不能僅僅根據層數或者數量而言。
梯度消失問題(Vanishing Gradient Problem)
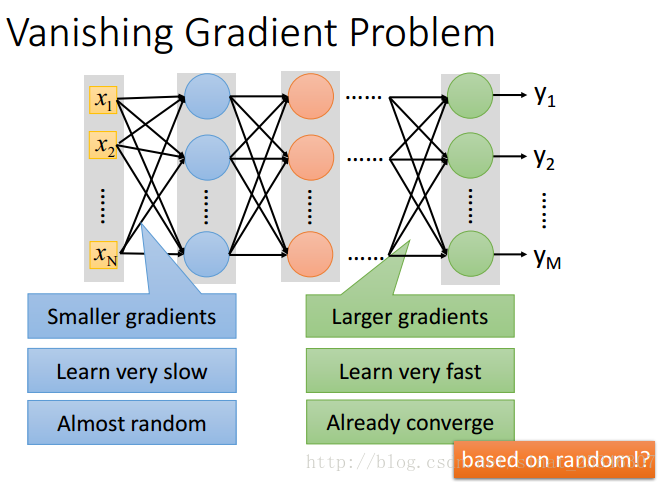
在靠近輸出層的單元的梯度大,學習速度快,會一下子收斂,導致認為網路已經收斂了。
而靠近輸入層的單元不會這樣,梯度會小,學習起來慢,就相當於隨機。
這樣整個網路就好像是基於隨機情況訓練而來的。肯定會效果不好。
如果考慮將權重初始化大一點的值,這又有可能造成梯度爆炸問題。
出現此類問題的根本原因並非是消失的梯度問題或者爆炸的梯度問題,而是在前面的層上的梯度是來自後面的層上項的乘積。所以神經網路非常不穩定。

直覺的想法是在損失函式的對於權重的梯度變化對於靠近輸入層上的梯度影響會極其小,這是因為sigmoid函式在很大的輸入時,也是很小的輸出。
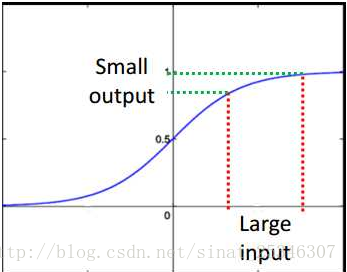
所以只要是sigmoid函式的神經網路都會造成梯度更新的時候極其不穩定,產生梯度消失或者爆炸問題。
解決方法可以用新的啟用函式。
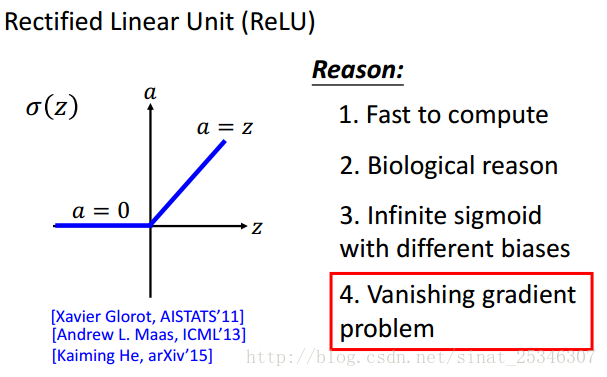
使用Relu啟用函式最重要的一點是能夠解決梯度消失的問題,在大於0的部分函式是線性的。
小於0時即為0,這就好像捨棄了部分單元,然後成為了一個瘦長的線性網路。可以理解為網路整體是線性的,而對input有著較大改變的,那就是非線性的。
此外還有別的進化版的Relu函式
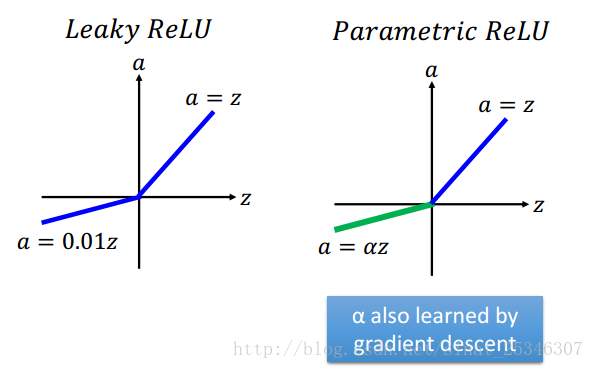
還有一種方法是Maxout,這是一種可學習的啟用函式,其實Relu就是Maxout的一種特殊情況。

在Maxout中,將單元進行分組然後是一個max pooling的過程,這是分組是事先決定的。
分組是任意的,多少個元素單元在一個組就有多少片(pieces),這也就決定了啟用函式是z怎樣的分段線性凸函式。關於Maxout的訓練和測試可類比與CNN中的Maxpooling。
2.Adaptive Learning Rate
在之前我們講解了Adagrad方法更新學習率,使用了之前的偏導值去更新接下來的偏導值。

介紹下一種新的更好的方法RMSProp (Root Mean Square)

通過α的值大小可以設定不同的傾向方向。α小傾向於新的梯度值,大就傾向於之前的 值。
在訓練網路中,我們經常擔心會陷入區域性最小值。但是其實不用過於擔心這個問題,對於一個很大的神經網路,引數很多,其陷入區域性最小值的概率是非常低的。
Momentum(動量方法)
此方法主要用了物理學上的慣性知識,當進行權值更新時,不僅要考慮此處的偏導值,也要考慮上一個狀態的更新方向,兩個方向的向量和就是新的更新方向。

從上圖的左部分就可以直覺看出,藍色是動量方向,其值是由梯度值和上一步的動量值共同決定的。
我們也可以認為使用動量方向能夠幫助我們跳出區域性最小值。
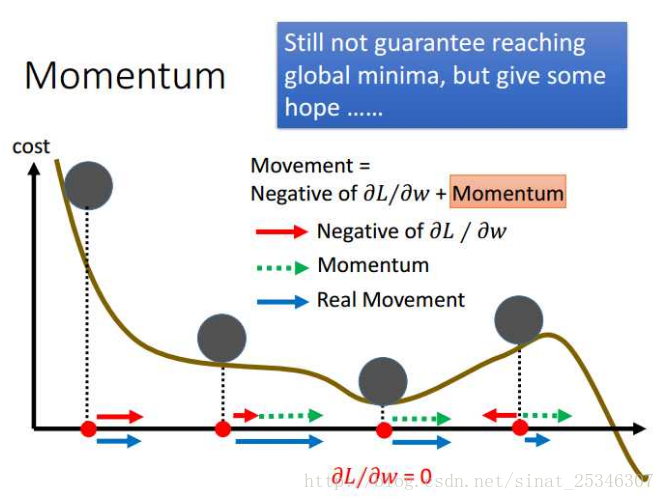
在梯度等於0的那個區域性最小值點,上一步的動量方向會告訴我們應該繼續往右而不是停止,進而能夠在一定程度上跳出那個區域性最小值點,雖然不能保證。
Adam
Adam的本質其實就是結合了上面講的RMSProp和Momentum方法,此外還使用了一種偏差修置的方法。具體可看吳恩達深度學習課程 改善深層神經網路:超引數除錯、正則化以及優化 - 網易雲課堂 關於bias-corrected介紹。

3.Early Stopping
提早停止是一個較為傳統的機器學習優化方法。
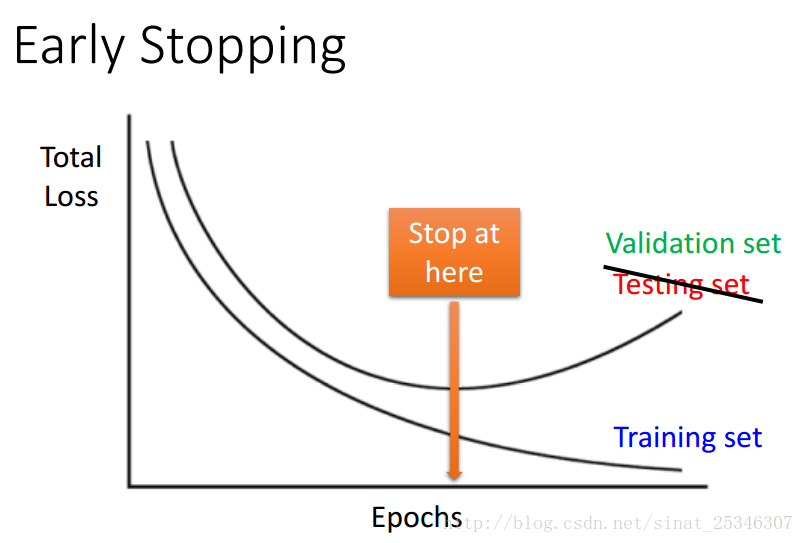
隨著在訓練資料上的損失不斷減小,在驗證集上的誤差會在達到某個最小值後反而增大,這時可以考慮提早終止網路的訓練,保留一個在訓練集合驗證集上效果都較好的網路。
4.Regularization
正則化在原來的損失函式上進行部分修改。
通過下式,我們可以看到L2正則化會帶來權值衰減的效果。

其實正則化在深度學習中的作用並沒有像在傳統的機器學習(SVM)中作用那麼大。
此外還有別的正則化方法,L1 regularization

L1的方法每次都是減去一個固定值,權值前係數大於0就加小於0則減。而L2是在前權值上有一個乘積的效果,訓練起來會更快。
此外,需要注意L1方法會使得權值接近0,更加稀疏。
5.dropout
dropout是以一定的概率丟棄部分單元,這樣網路就簡化了。
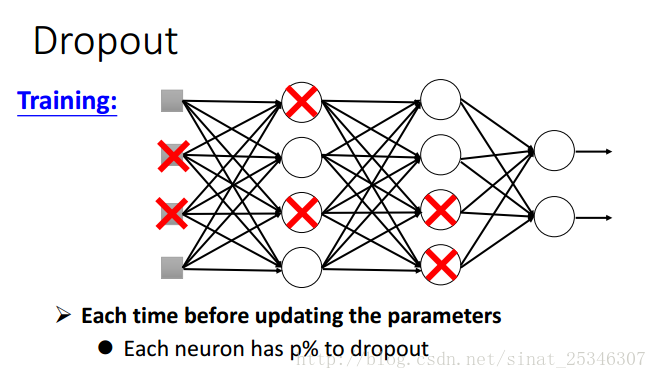

對於每一個min-batch,我們都要重新進行drouput,改變網路的結構,並使用新的網路結構去訓練。

在測試時,是不能dropout的,並且要將權值都乘上1-p係數。
為什麼要這麼做,原因有很多。

較為直覺的想法是訓練時腳上綁重物,在測試時拿下了重物後就會變得很強。

還可以理解為分組做project時,組隊時都認為隊友不會做(dropout),然後只能靠自己一個人好好做,到測試時,沒有一個人不做,都好好做,效果就很好。
測試時為什麼要乘1-p呢?
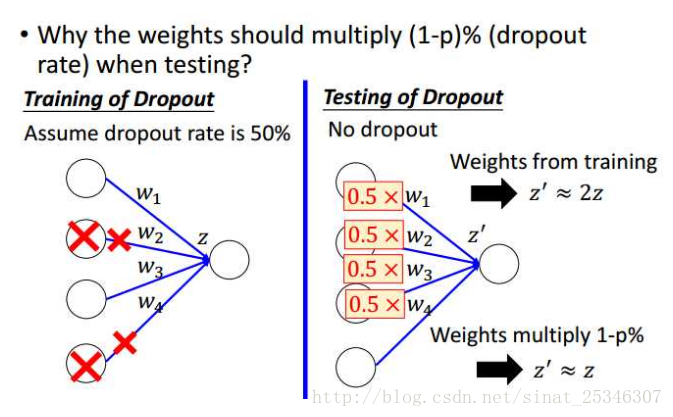
可以像上圖這樣理解,p為0.5時,在測試階段得到的值會等於訓練時的兩倍,所以乘上1-p的係數就可使二者近似相等。
還可以理解dropout為一種整合。
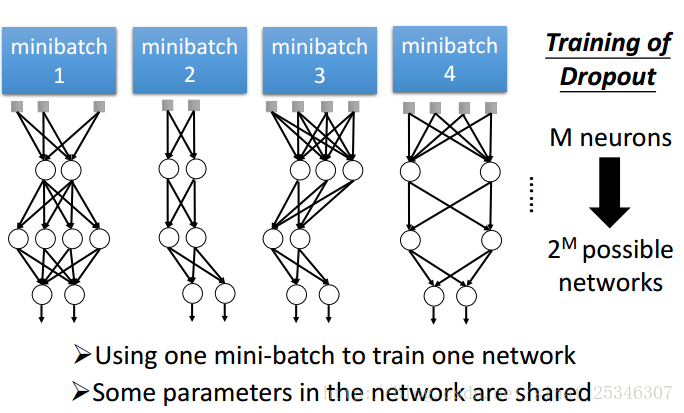
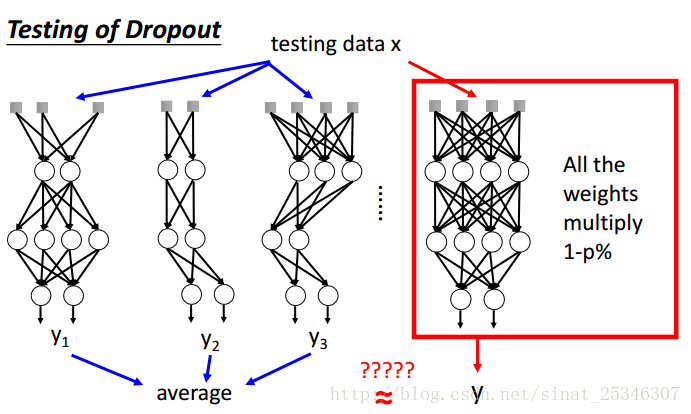
考慮一種較為簡單的線性情況:
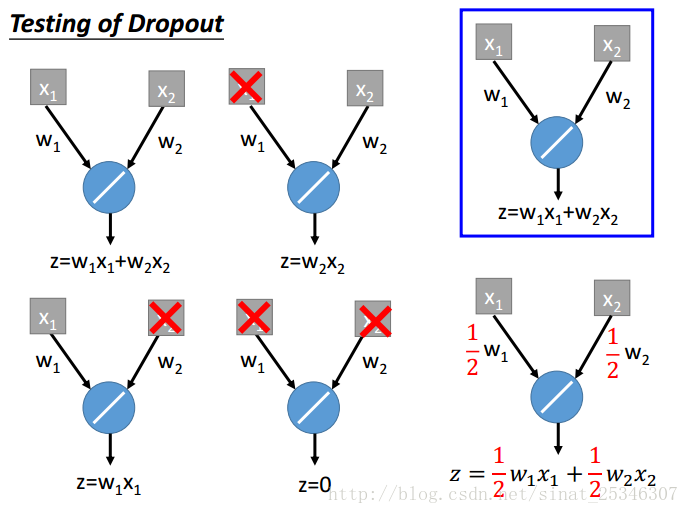
兩個單元,四種情況,其可能取平均就等於最後全結構乘上1-p。
對於線性來說,這無疑會相等,非線性不會完全相等,但可認為是近似相等,有用。
6.總結
本章節內容較多而且比較重要。主要知識點在於介紹優化網路,處理不同網路問題的方法。
主要介紹了Relu啟用函式、Adam更新權值、early stop、正則化以及dropout。