
Deep Forest 復現與自己資料的實現
花了半天不到的時間看了一下論文,論文地址:https://arxiv.org/abs/1702.08835
本身做影象比較多,機器學習比較少,以下只是我簡單粗淺的理解。
摘要
優點:在small-scale資料集上表現良好;可以處理各類資料,結構化資料,文字資料,影象資料等等等。
1. Introduction
所謂gcForest,指的是multi-Grained Cascade Forest,主要分為兩部分,即multi-Grained和Cascade部分,具體結構可以參考Figure4。
2. The Proposed Approach
2.1 Cascade Forest Structure
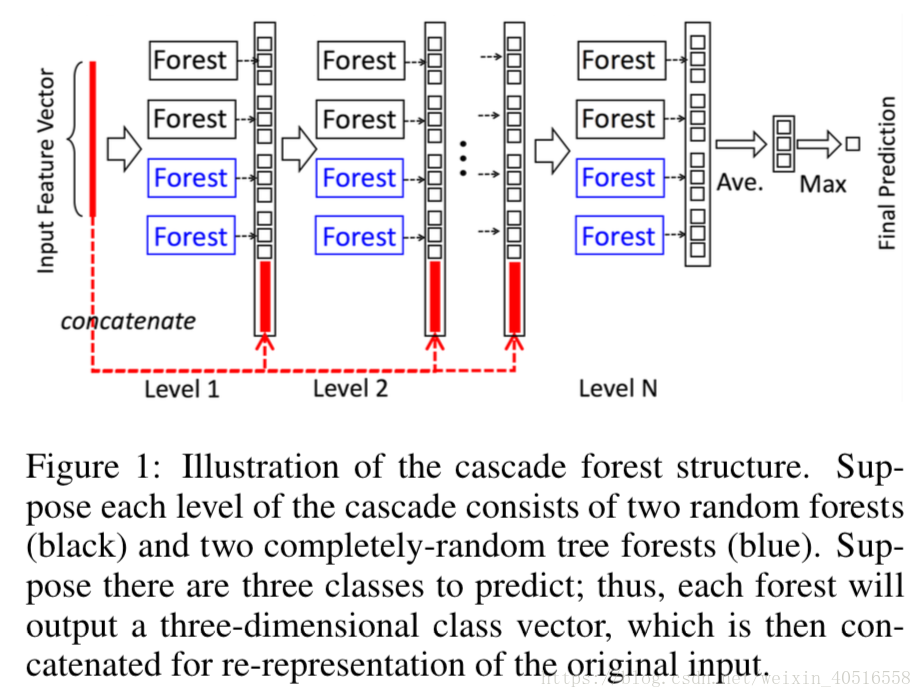
DNN中表徵學習一般都是通過對原始特徵進行一層一層的加工實現的。受到這一思想的啟發,gcForest採用的是級聯結構,如圖1所示,每一層都接受來自於前一層加工的結果,再把輸出結果輸入到下一層中去。
從圖中可以看出每一個水平都是一系列決策森林的ensemble,除此之外,每一層上為了多樣性的考慮,選擇了兩種不同的森林,分別是completely-random trees和一般的rf,圖中有2個completely-random trees和2個一般的rf,每一個completely-random trees或者一般的rf都包含500棵樹。completely-random trees和一般的rf區別在於,前者是通過隨機選擇任意一個特徵作為結點的分割,而後者則選擇根號(d)個特徵作為候選,然後選擇其中gini係數最大的作為結點的分割。
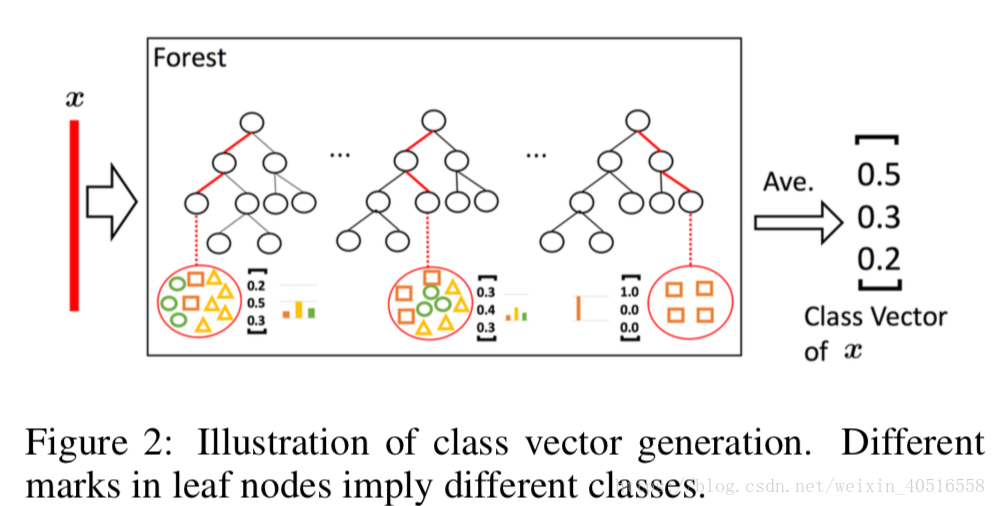
如圖2所示,每一個訓練樣本(此處的訓練樣本是被sliding window加工後得到的擴充樣本)輸入到森林中後,進入森林中的每一棵決策樹。最後在每一棵決策樹的結點上得出一個3維向量,分別代表三個類別的概率。然後再求取每棵樹上的平均,最後再求取整個森林上的平均,再將所有301個向量(當sliding window大小為100-dim時)進行concatenate之後輸出。因此最後每個森林的輸出維度為301x3=903維。
為了緩解過擬合問題,最後產生的class vector都是經過k折交叉驗證過的。即,每一個instance都會被當做訓練樣本使用k-1次,得到k-1個class vector,然後對其求平均產生一個最後的class vector作為提升特徵放入到下一level的cascade中去。在擴充套件一個新的水平的cascade之後,會對整個cascade的表現在驗證集上進行評估,gcForest的cascade水平是自適應的,一旦模型表現沒有了顯著提升,訓練過程就會隨時停止。
2.2 Multi-Grained Scanning
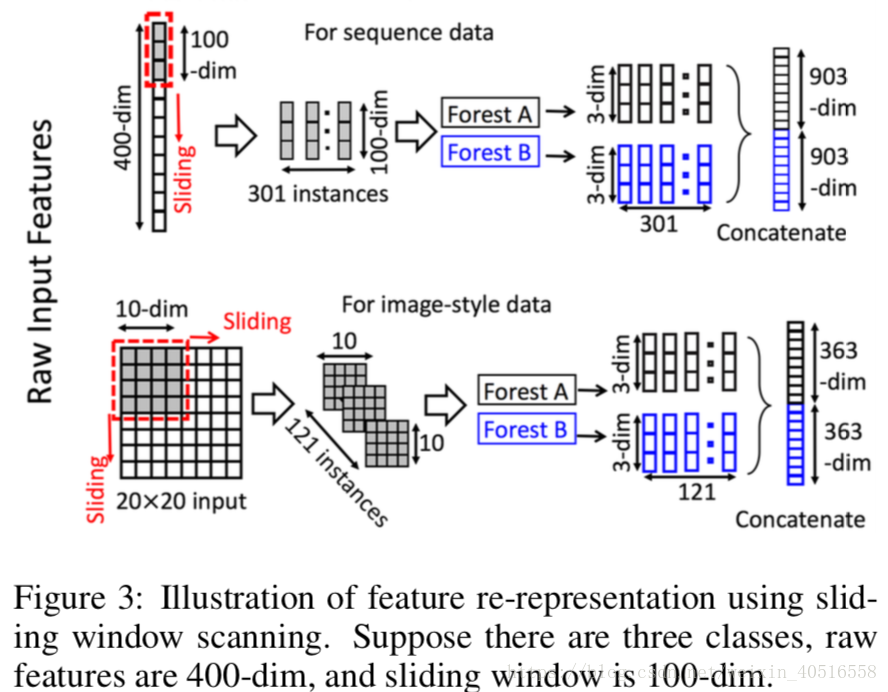
如圖3所示,滑動視窗是用來對原始特徵進行掃描的。假設原始特徵的維數為400-dim,滑窗大小為100-dim。對於序列資料,滑動視窗滑動一次會產生一個100-dim的向量,因此總共會產生301個特徵向量。如果原始特徵具有空間關係,比如一個20x20大小的圖片,那麼一個10x10大小的滑窗會產生121個
下采樣,因為completely-random tree forest和random forest對特徵分割都較為不敏感甚至是沒有任何關係。
通過使用不同大小的窗寬,我們就實現了Multi-Grained Scanning。

圖4總結了gcForest完整的流程。假設輸出原始特徵為400-dim,使用三種窗寬進行多粒度掃描。對於m個訓練樣本,窗寬大小為100-dim的情況下,會產生301xm個100-dim的訓練樣本。隨後這些資料將會被用來訓練一個completely-random tree forest和一個random forest。對三個類別進行預測,就會生成一個1806-dim的特徵向量。經過上述轉化後的訓練集將會被用來訓練cascade forest的1st-grade。
類似地,窗寬大小為200和300的將會針對每一個訓練樣本分別產生1206-dim和606-dim的特徵向量。轉化後的特徵向量,同前一層生成的提升特徵進行連線後,會分別用來訓練cascade forests的2nd-grade和3rd-grade。這一過程將會重複直到驗證集效果手鍊。換句話說,最終模型實際上是一個cascade of cascade forests,其中每個cascade的的每一水平是由多個grades的cascade forests組成,每一個grade對應著一種掃描細粒度。對於更加困難的任務,可以在算力允許的情況下嘗試更多細粒度。
給定一個測試樣例,它會經過多細粒度掃描過程得到它對應的轉變後的特徵表徵,然後經過cascade直到達到最後一個水平。那麼如果獲得最後的預測結果呢?我們通過對最後一個水平上的4個3-dim的class vectors進行加總,然後選出最大值。
表1展示了DNN和gcForest的一些超引數,gcForest中給出的是作者在實驗中的一些預設值。

3. Experiments
3.1 Configuration
以下將gcForest和DNN以及其他幾個流行的學習演算法進行對比。發現gcForest不僅可以達到同DNN相同的效果,而且對於不同種的任務調參也變得更為簡單。在所有實驗中gcForest都是用的是同一種cascade結構,每一水平都包含4棵completely-random tree和4棵random forest,每一個都包含500棵樹。class vector的生成使用了3折交叉驗證。cascade的水平是自動決定的。細節方面,作者將訓練集分為兩部分,即growing set和estimating set。然後用growing set對cascade進行生長,用estimating set來估計表現情況。如果生長一個新的水平沒有提升表現,那cascade的生長就終止,我們就得到了估計的水平數。在這之後,cascade又會基於growing set和estimating set上進行再訓練。所有的實驗中訓練資料的80%作為growing set,60%作為estimating set。在多粒度掃描,選用了三種大小的滑動視窗。如果我們有d個原始特徵,那選擇使用ceil(d/16)、ceil(d/8)和ceil(d/4)大小的滑窗。在DNN方面,作者選擇了ReLU作為啟用函式,交叉熵函式作為損失函式,adadelta作為優化方法,隱藏層的dropout rate根據訓練資料規模,選擇0.25或0.5。
github倉庫地址:https://github.com/kingfengji/gcForest
用conda建立好虛擬環境,按照requirements配置好需要的依賴即可
最簡單的調包實現方式,即建模、擬合、預測,完了- -
from gcforest.gcforest import GCForest
gc = GCForest(config) # should be a dict
X_train_enc = gc.fit_transform(X_train, y_train)
y_pred = gc.predict(X_test)目前lib中支援了幾種分類器,分別是隨機森林、XGB、ExtraTrees、 LR以及SGD,除此之外,可以自己手動在lib/gcforest/estimators/__init__.py新增分類器。具體分類器需要先在sklearn_estimators.py定義類。