
實戰案例:AI產品經理如何介紹“計算機視覺”?
深度學習交流QQ群:116270156
作者根據親身經理的專案案例和平時所學,從產品實踐的角度,談談計算機視覺,希望對你有所幫助。

計算機視覺(Computer Vision)對我來說也算是老朋友了,我最開始接觸人工智慧就是計算機視覺相關的知識。最近受益於老大每日帶我去旁聽的演算法例會,又加上看了徐立(商湯)的《計算機視覺的完整鏈條,從成像到早期視覺再到識別理解》,發現很多資訊,當時不覺得有什麼,現在想想,每一步都是有意義的。
今天,我會根據親身經理的專案案例和平時所學,從產品實踐的角度,談談計算機視覺。
一、前言
計算機視覺(computer vision)是使用計算機以及相關裝置對生物視覺的一種模擬。它主要任務是通過對採集的圖片或視訊進行處理以獲得相應場景的三維資訊。
在徐立的分享中,將計算機視覺的完整鏈條分為了三部分:
- 成像(image)
- 早期視覺(early vision)
- 識別理解(Recognition)
本文也將根據徐立對整個鏈條的三部分分類,分別用實際例子結合談談產品在三部分中可以關注的內容。
二、成像(image)
成像就是模擬的相機原理,就是在解決怎樣把拍攝照片的質量進行提升的問題。
我們在實際工業運用中,經常發現實際資料和實驗室資料相差過大,實驗資料的質量遠遠差於實驗室資料。更甚者在最開始訓練模型的時候,我們會發現實驗室模型在實際場景毫無效用。
經過多次試驗測試,我們發現影響影象質量的因素大概有以下幾類:
光照影響
過暗或過亮等非正常光照環境,會對模型的效果產生很大幹擾。在解決光照影響這個問題上,我想可以通過兩種方式:
1)從產品角度控制:
a.在使用者可以更換環境的前提下(比如手機自拍等),可語音/介面提示使用者目前環境不理想,建議換一個環境。
b.使用者不能控制更換環境的情況下(比如人臉識別、車輛識別等攝像頭固定的場景),只能通過除錯硬體設施彌補這個問題。
- 夜晚:在工業上我們碰到過曝或者過暗的情況更多都是在晚上,由於攝像頭在晚上會自動切換到黑夜場景(從圖片上看就是從彩色切換為黑白),因此在晚上強光下(例如車燈照射)影象就會過曝,這樣的情況我們可以通過強制設定攝像頭環境為白天(影象為彩色)來避免。過暗的情況從節省成本角度看,我們可以在攝像頭旁邊增加一個光線發散、功率不高的燈來彌補。當然這兩個問題也可以通過購買高質量的攝像頭解決,但這樣做也意味著更高的成本。
- 白日:白天也會出現光線過亮的情況,這種情況可以考慮用濾光片等等。
2)演算法角度控制
用演算法將圖片進行處理,可以將圖片恢復得讓人眼看清的程度。徐立在文中舉例了這樣一張圖片:

這張圖片從暗到明,經過演算法的處理我們可以顯而易見地觀察到整個圖片的內容。這個辦法非常靈活,但也對公司的演算法提出了更高的要求。我們知道每一次演算法的過濾時間是非常重要的,如果在對時間要求非常嚴格的場景(人臉識別、車輛識別),這樣在識別之前還要對圖片進行轉化,無疑是增加了輸出結果的時間。技術實力不那麼強的公司可能是需要權衡一下的。
模糊(blur)
模糊也是工業中經常遇到且令人十分頭痛的問題。這裡我們先將模糊分下類:
- 運動模糊:人體移動、車輛移動
- 對焦模糊:攝像頭距離等因素構成,類似近視眼,影象中低頻存在,高頻缺失。所以需要用演算法設法補齊高頻部分。
- 低解析度差值模糊:小圖放大等,影象中低頻存在,高頻缺失。所以需要用演算法設法補齊高頻部分。
- 混合模糊:多種模糊型別共同存在
對於模糊產品上能控制的場景比較少,僅針對於第一種運動模糊且產品和使用者有互動的情況下才能做到。其他型別的模糊均需要採用演算法進行處理。
我們發現大多數模型(包括face++等技術比較前沿公司的模型),也會出現大量正常影象被判為模糊。從演算法角度講這可能不是很理想,但從工業角度講這是可以被接受的,被誤判為模糊影象的正常影象會被過濾掉或者經過演算法處理後再識別,這對使用者來說不會造成使用上的不適。而且我們也能保證閾值以上的圖都是正常圖片,對模型訓練來說也是有利的。所以,產品需要關注的精確率和召回率在某種特定情況下可以降低要求。
影響影象質量的因素除了光照、模糊還有很多比如噪聲、解析度等等問題,這些問題大多也是從演算法和硬體上去優化,值得注意的是我之前提過的,需要考慮到時間和成本的權衡。
三、早期視覺(early vision)
early vision這部分其實我之前沒有總的概念,看了徐立的分享,回頭來才發現“哦!原來大家當時做的是這個部分的內容”。
early vision主要是做哪些工作呢?主要是影象分割、邊緣求取、運動和深度的估計。這些內容其實沒有直接的結果應用,是一個“中間狀態”。

影象分割是指將特定的影像分割成【區域內部屬性一致】而【區域間不一致】的技術,是影象處理中最基礎和最重要的領域之一。
影象分割方法有很多種,比如灰度閾值分割的方法、邊緣檢測法和區域跟蹤等方法。很多種類的影象或景物都有相對應的分割方式對其分割,但同時有些分割方法也僅限於某些特殊型別的影象分割。
拿邊緣檢測來說,其目的是找到影象中亮度變化劇烈的畫素點構成的集合,表現出來就是輪廓。

徐立提出了early vision現目前的兩個問題:
- 結果不精確
- 需要長時間的知識沉澱才能做到
第一個問題的解決辦法是用端到端的方式,第二個問題的解決辦法可以依靠資料驅動。
這部分產品介入的比較少吧,平時跟演算法同事溝通聽見比較偏多的反饋是在影象分割上有一些缺陷。像徐立說的“怎麼樣用這種中間的結果去得到更好的應用,至今來說覺得這都是一個比較難回答的問題”,因此產品或許可以去考慮早期視覺直接應用的場景。
四、識別理解(Recognition)
識別理解是需要把一張(輸入)圖對應到一張(輸出)圖,或者說一張(輸入)圖對應到一箇中間結果。簡單來說就是把一張圖對應到一個文字或標籤。這其中有兩個重要的因素:標籤、資料。這兩個因素廣度和精度越高,針對模型最後的識別效果就越好。
標籤
標籤的定義其實也就是規則的定義,我在上一篇文章《AI產品經理需要了解的資料標註工作》裡有提過,越精確的標籤肯定對模型的結果有利,但同時越精確的標籤意味著這類標籤下的資料量就會越少,產品也需要考慮到這個因素。
還有一些會被主觀因素影響的標籤定義,比如顏值,每個人對顏值的評價都是不一樣的。徐立說在他們的顏值模型裡會分為“漂亮”“不漂亮”兩個標籤,主要是靠社交網站上的評分和明星與大眾的區別來標註。其實我以前也跟過顏值的模型,在我的模型裡對顏值更加細化了:有好看、普通、醜。除了根據社交網站打分、明星打分這種方式,我的經驗是關注資料的場景型別,很多資料被歸為一類都是場景相似的。比如如花,我們覺得醜吧?大多數男扮女的裝扮也都會被定義為醜。
另外更細的標籤細分會有更多的落地可能性,我印象最深的就是以前顏值模型有一個節日運營活動,主題是扮醜,辦得越醜的人還會有小禮品,這個活動上線後在友商的使用者圈內引起了很高的關注度。當時我接到這個活動的時候思想其實是被顛覆的,因為我最開始認為顏值模型可能存在的場景主要是去識別美的人,比如在直播等平臺中去區分主播的顏值,推薦更優質的主播上首頁等等後端的應用,沒有想過還能反著用。經過這個活動的啟發,後來我們也發現顏值模型在娛樂性上可以有更多挖掘的可能性。
這樣看來由於我們的模型多了一個標籤定義,就多了一種落地的可能性,標籤的重要性也就不言而喻了。
資料優化
資料的數量和質量對模型來說舉足重輕。最近剛接收到的重磅訊息:阿法狗的弟弟阿法元沒有任何先驗知識的前提下,通過完全的自學,打敗了由資料訓練出來的阿法狗。我相信以後這個技術肯定會越來越多的應用,說不定以後確實在某些領域不利用海量資料也能完成模型訓練。但是就目前而言,在計算機視覺領域,資料的大量性是重中之重的。
我們大家肯定都知道,資料優化可以使模型越來越好。什麼型別的功能表現得不好,就要填補那些對應的資料。而除了這個常識外,其實資料優化還可以用來解決我們經常在訓練過程中出現的問題:過擬合。
什麼是過擬合?

通常來講是模型把資料學習過深,資料中的細節和噪音也學習進去了,這樣就導致模型泛化的效能變差。過擬合的表現是,一個模型(一個假設)在訓練集上表現得很好,但是在測試集上表現的確不是很好。
那該如何通過資料限制過擬合呢?
- 重新清洗資料。資料的噪音太多會影響到模型效果,清洗資料能夠把由於這個因素造成的過擬合問題規避
- 增加訓練集的資料量。如果訓練集佔總資料的比例太少,也會造成過擬合。
當然也能通過演算法限制這個問題的,比如正則化方法和dropout法,以後有空我們可以再深入討論。
五、專案實踐 (以車型識別舉例)
車輛檢測系統下有很多CV相關的應用,比如車型識別、車牌識別、車顏色識別等等。我們從車型識別這一個例子著手,探索專案的具體流程。
專案前期準備
1.資料準備:
車型這個主題說大不大,說小不小。全世界的車輛品牌數目大約三四百個,每個品牌下面又有幾十種車系。我們從0開始立項,至少需要把常見的車輛車系都包含。像大眾、豐田、賓士、寶馬、奧迪、現代等等熱門車輛品牌更是需要拿全資料。每一種車型至少有車頭、車尾、車身三種基礎資料。
比如賓士C200:
這三張圖片代表了三種資料,不同場景下這三種資料的重要性大為不同。在專案前期假設我們定下來識別車型這個需求主要應用場景是“停車場識別車輛”,那車頭這個資料相對而言就更加重要,需要花更多心思收集。為什麼呢?我們可以想象,停車場的車輛識別攝像頭為了捕捉車牌號,一般會將攝像頭正對車輛,攝像頭傳上來的資料很少會有純側面車身的資料甚至車尾資料。我們為了專案更快地應用落地,其他型別資料比較缺少的情況是可以暫時放下後期再做優化的。

在資料準備的過程中,首先需要爬蟲從網上爬取資料,再由人工篩選過濾到不可用的資料,將資料統一整合,才能進行下一步工作。
2.文件準備
A)資料標註文件,包括我們專案一共所含多少鍾車型、每一種車型分別對應什麼樣式。資料標註中需要注意的問題,多輛車的圖片、角度刁鑽的圖片是否需要捨棄等等。
B)產品文件,包括落地場景說明、需求說明文件等常規文件。這裡拿工業車輛識別需求分析下系統設計:
- 演算法需求描述(識別的種類、範圍、速度、準確率、穩定性等等)
- 攝像頭裝置硬體需求描述、環境描述、資料傳送描述、攝像頭配置描述
- 平臺程式設計(車輛識別系統平臺前後端設計)
- 資料關聯描述(車輛資訊分析統計關聯)
如果攝像頭在區域網,且有布控功能(識別車輛黑名單的需求)還需要:
- 下發程式(考慮雲端到本地的影象特徵下發)
- 點播程式設計(可以從網際網路檢視本地攝像頭)
專案流程跟蹤
1.軟硬體端:按照常規的軟硬體專案跟蹤開發
2.演算法:車型識別的流程基本如下:

車型影象上傳:通過過攝像頭/web上傳
影象預處理:包含了上文成像部分中的模糊影象恢復處理(運動模糊有快速演算法去模糊:通過已知速度V、位移S,確定影象中任意點的值)

early vision中的影象分割(將目標影象從背景圖中標識出來,便於影象識別,可以考慮邊緣檢測方法)、影象二值化(將影象中的畫素點的灰度值設定為0或者255,使用輪廓跟蹤讓目標輪廓更為凸顯)
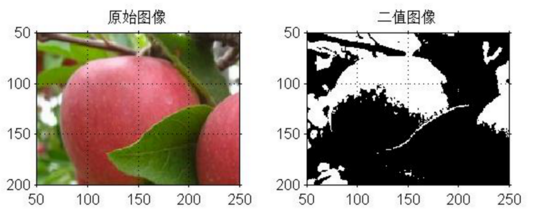
影象特徵提取
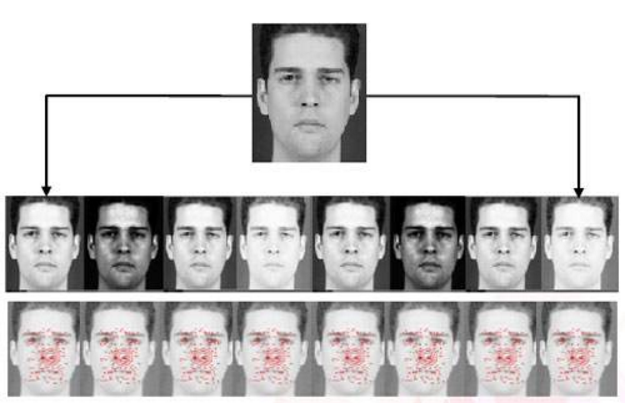
特徵比對
專案測試
- 攝像頭測試
- 攝像頭與點播程式測試
- 點播程式(可實時檢視攝像頭的程式)與平臺後臺程式測試
- 演算法與平臺後臺測試、備用介面測試
- 模型識別時間測試
- 模型識別準確率、召回率測試
- 伺服器穩定性測試
- 網路頻寬限制測試
- 正反向測試
- 其他平臺、硬體產品常規測試
- 專案驗收
產品按照流程功能逐一驗收