
神經網路在關係抽取中的應用
一、關係抽取簡介
資訊抽取的主要目的是將非結構化或半結構化描述的自然語言文字轉化成結構化資料(Structuring),關係抽取是其重要的子任務,主要負責從文字中識別出實體(Entities),抽取實體之間的語義關係。
如:句子“Bill Gates is the founder of MicrosoftInc.”中包含一個實體對(Bill Gates, Microsoft Inc.),這兩個實體對之間的關係為Founder。

Freebase中的關係型別
現有主流的關係抽取技術分為有監督的學習方法、半監督的學習方法和無監督的學習方法三種:
1、有監督的學習方法將關係抽取任務當做分類問題,根據訓練資料設計有效的特徵,從而學習各種分類模型,然後使用訓練好的分類器預測關係。該方法的問題在於需要大量的人工標註訓練語料,而語料標註工作通常非常耗時耗力。
2、半監督的學習方法主要採用Bootstrapping進行關係抽取。對於要抽取的關係,該方法首先手工設定若干種子例項,然後迭代地從資料從抽取關係對應的關係模板和更多的例項。
3、無監督的學習方法假設擁有相同語義關係的實體對擁有相似的上下文資訊。因此可以利用每個實體對對應上下文資訊來代表該實體對的語義關係,並對所有實體對的語義關係進行聚類。
與其他兩種方法相比,有監督的學習方法能夠抽取更有效的特徵,其準確率和召回率都更高。因此有監督的學習方法受到了越來越多學者的關注。
因為NLP中的句子長度是不同的,所以CNN的輸入矩陣大小是不確定的,這取決於m的大小是多少。卷積層本質上是個特徵抽取層,可以設定超引數F來指定設立多少個特徵抽取器(Filter),對於某個Filter來說,可以想象有一個k*d大小的移動視窗從輸入矩陣的第一個字開始不斷往後移動,其中k是Filter指定的視窗大小,d是Word Embedding長度。對於某個時刻的視窗,通過神經網路的非線性變換,將這個視窗內的輸入值轉換為某個特徵值,隨著視窗不斷往後移動,這個Filter對應的特徵值不斷產生,形成這個Filter的特徵向量。這就是卷積層抽取特徵的過程。每個Filter都如此操作,形成了不同的特徵抽取器。Pooling 層則對Filter的特徵進行降維操作,形成最終的特徵。一般在Pooling層之後連線全聯接層神經網路,形成最後的分類過程。
二、論文研讀

- 假如現在有一語料集,要判斷Bill Gates is the founder of Microsoft這句話中Bill Gates 和Microsoft這兩者之間的關係,首先要找出包含這兩個單詞的句子集{,, … ,}。現在要判斷這些句子中兩者眾多關係中關係r的概率。
- 考慮句子集中每個包含m個單詞的句子x。,為了表達這個句子的意思,將每個單詞轉化為對應的word embedding (維度)。同時找出每個單詞相對於兩個實體之間距離的position embeddings (維度)。講兩者聯結起來,構成新向量集,(維度)

位置向量
- 接下來則要進行卷積運算了,設d=|w|, l為滑動視窗長度,可以就看出圖一的例子中d=6 , l=2 。現在假設為w中第i-l+1到i行構成的。其中,超出邊界(i<1或i>m)的值為0。
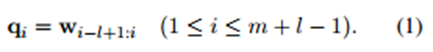
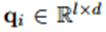
因此,卷積層的第i個滑動視窗由下式計算得到。
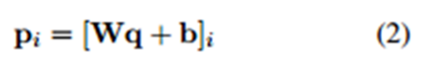
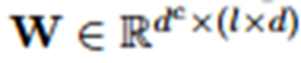
接著最大池化得到一數。
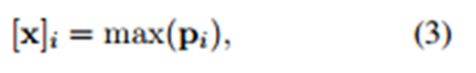
- 這篇論文在池化層時將通過兩個實體位置將 feature map 分為三段進行池化,其目的是為了更好的捕獲兩個實體間的結構化資訊。最後,通過 softmax 層進行分類。
如果將句子通過兩個實體的位置將其分為三段,這樣,就被分成了三段
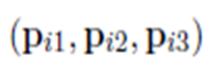
然後再對每一段最大池化,
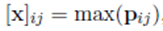
接著將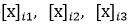
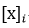
最後,通過非線性層tanh得到向量
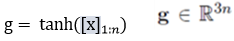
最後一層全連線層
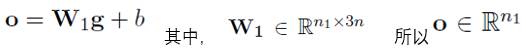
(n1是最後的關係分類數)
- 原始句子經過CNN的處理後,就成為了一個具有多個特徵的向量,之後就可以用不同的方法去處理了。
- 這篇論文使用了多示例學習(multi-instance learning)的方法。
7. 假設網路所有引數為θ,訓練集有T個包,
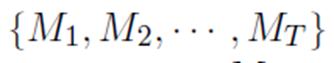
第i個包有qi個示例:
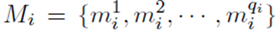
演算法流程如下:

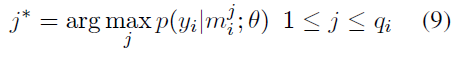
目標函式:
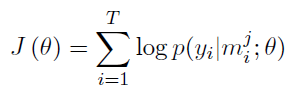
最大化目標函式以學習引數。
- 論文在前半部分的處理與前一篇論文一樣,不多做闡述。
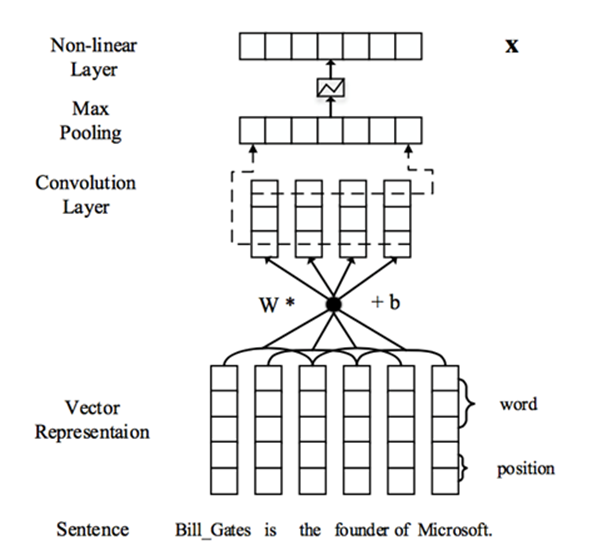
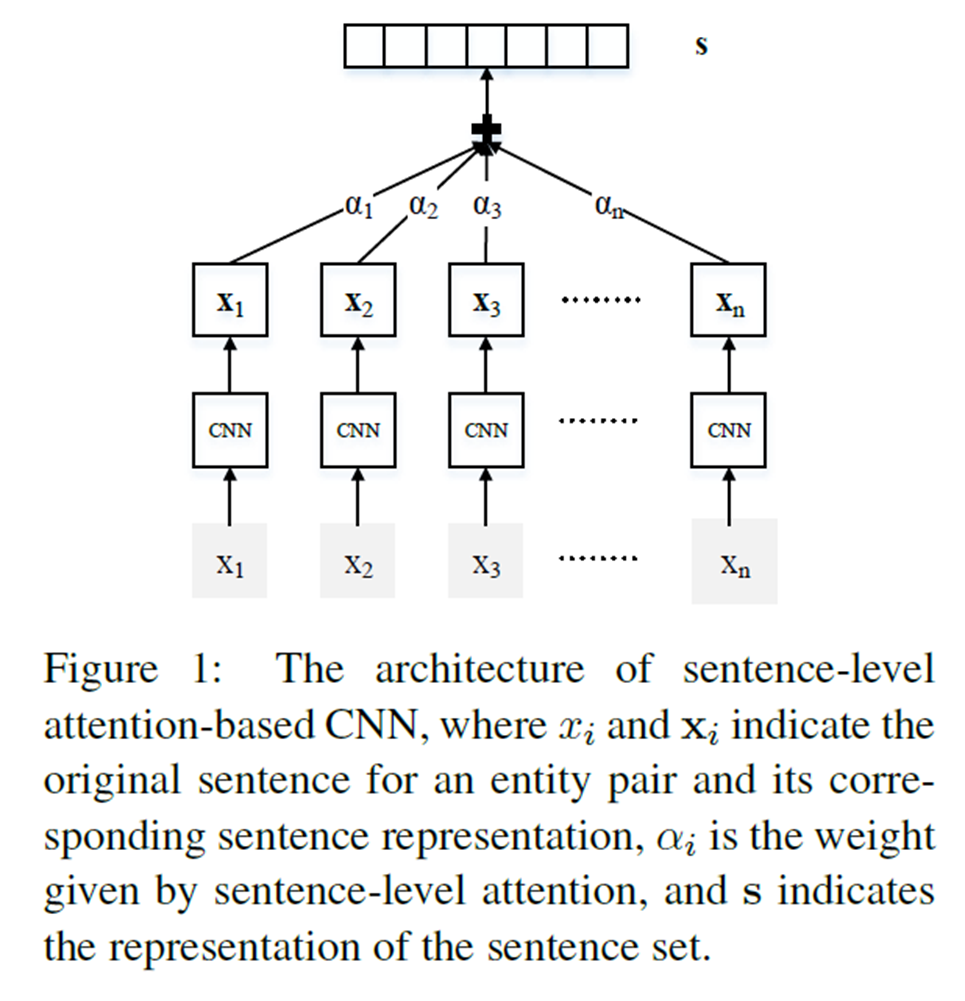
- 如上圖所示,主要區別在於全連線層本篇論文使用了選擇性關注機制。
- 考慮包含兩個實體的句子集合
,將這些向量加權求和:
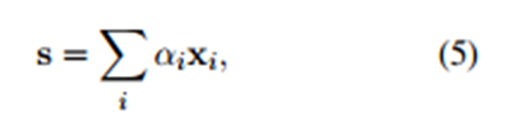
- 論文中選擇了兩種求權值的方法,如下:
(1)取平均(AVE): (2)選擇性關注(ATT):
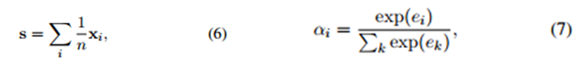
該方法主要是為了減少錯誤標籤的影響。
- 加入attention之後的s,再通過一層網路:

這一層網路的引數M是現存所有實體關係的向量所組成的矩陣,這樣的處理在數學上的意義也是很直觀的,最後將該層網路的輸出經過一個softmax層,那麼所要最大化的的就是的就是在網路引數下某實體關係的概率:
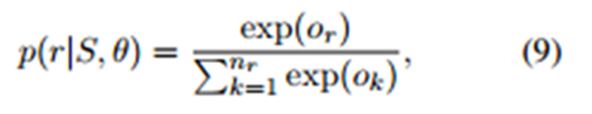
- 選取交叉熵函式並利用隨機梯度下降進行優化最後便可以學得網路的所有引數:
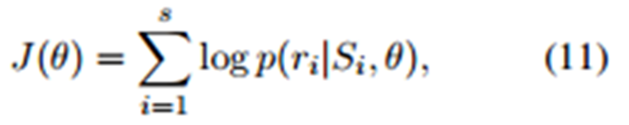
- 該論文在前面也做了類似的詞向量和位置向量處理。後面使用了LSTM的方法。
- 主要流程圖如下:
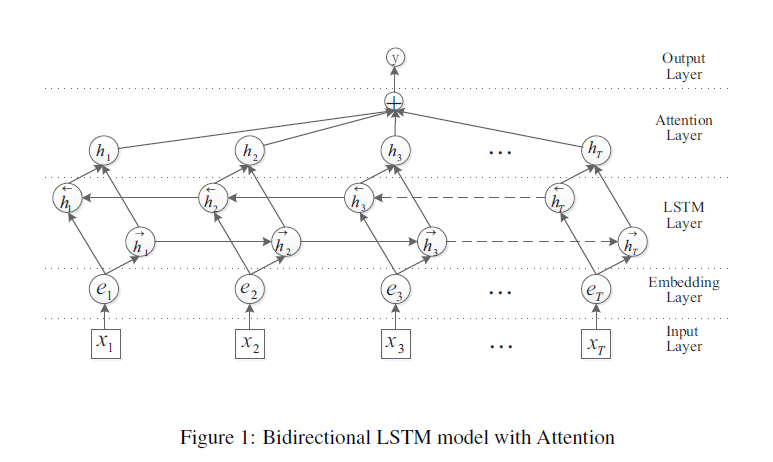
- 這裡只簡要各層的功能:
輸入層:將原始句子輸入該層;
向量層:將每個單詞對映到一個低維向量;
LSTM層:利用BLSTM從輸入的向量得到該句子的強特徵
關注層:產生一個權重向量,將LSTM中的每一個時間節點通過這個權重向量聯結起來;
輸出層:將上面得到的向量運用到關係分類任務上。
三、實驗過程與驗證:
1、前兩篇論文實驗:
程式碼使用的語言是C++,在Ubuntu環境下測試
下載完程式碼後,編譯,進入資料夾要測試的資料夾包括CNN+ONE, PCNN+ONE,CNN+ATT, PCNN+ATT開啟終端輸入make
其中:PCNN+ONE對應第一篇論文,PCNN+ATT對應第二篇論文。
訓練資料: ./train
測試資料: ./test
p.s.作者已經訓練好資料並且已儲存好模型,可以直接test,所以沒有必要每個都執行train。
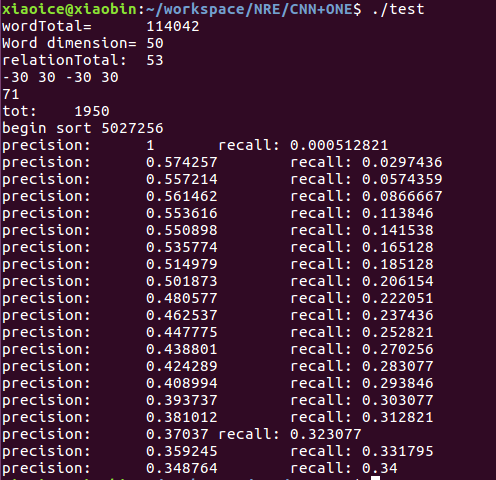
(1)CNN+ONE結果
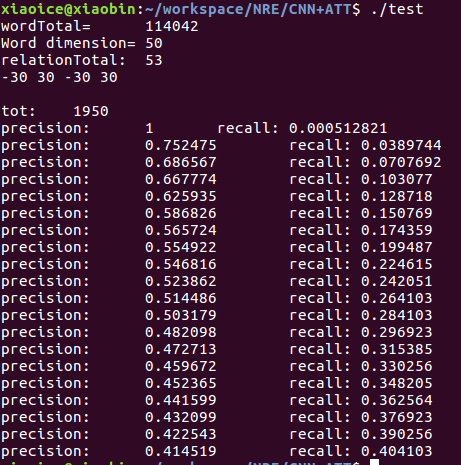
(2)CNN+ATT結果
(3)PCNN+ONE結果
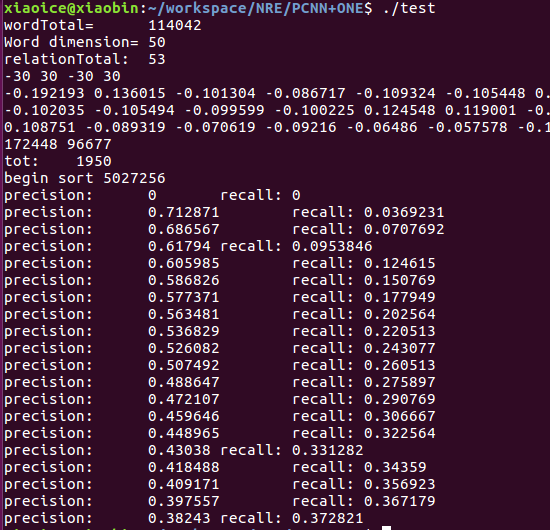
(4)PCNN+ATT結果
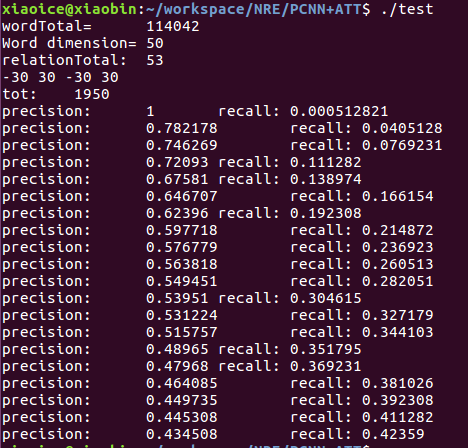
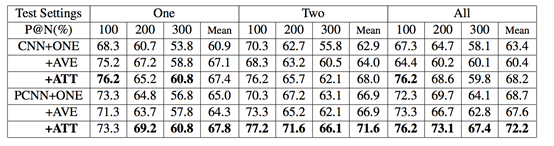
效果上PCNN > CNN
ATT>ONE
2、第三篇論文實驗:
第三篇論文實驗使用的python3語言,在Ubuntu環境下測試
作者使用的python版本是python2,同時tensorflow的版本是r0.11
而我電腦上的python版本是python3,tensorflow 的版本是1.1.0
又不想重新安裝,所以只能改動原始碼。
首先,ubuntu中預設安裝的python2中有個2to3工具,可以直接將python2的程式碼轉換為python3的程式碼。
終端輸入 2to3 –w example.py就能將example.py轉換為python3,同時產生example.oy.bak的備份檔案。
這樣就可以將所有的相關程式碼轉換為對應的python3語言,非常方便,省的一個一個改。
接著就要改tensorflow了,由於tensorflow版本的變動比較大,所以要改的地方還挺多的,針對我改動過程中遇到的問題,整理如下,當然一些沒遇到的就沒有整理了。
Tensorflow 新舊版本的改動
一、AttributeError:module 'tensorflow.python.ops.nn' has no attribute 'rnn_cell'
tf.nn.rnn_cell ===》
tf.contrib.rnn
二、TypeError:Expected int32, got list containing Tensors of type '_Message' instead.
tf.concat引數調換下位置,數字放在後面
三、AttributeError:module 'tensorflow' has no attribute 'batch_matmul'
batch_matmul ===》
matmul
四、AttributeError:module 'tensorflow' has no attribute 'mul'
mul ===>
multiply
五、ValueError:Only call `softmax_cross_entropy_with_logits` with named arguments (labels=...,logits=..., …)
註明哪個是labels,哪個是logits
六、AttributeError:module 'tensorflow' has no attribute 'scalar_summary'
tf.audio_summary ===》 tf.summary.audio
tf.contrib.deprecated.histogram_summary===》 tf.summary.histogram
tf.contrib.deprecated.scalar_summary===》 tf.summary.scalar
tf.histogram_summary===》 tf.summary.histogram
tf.image_summary===》 tf.summary.image
tf.merge_all_summaries===》 tf.summary.merge_all
tf.merge_summary===》 tf.summary.merge
tf.scalar_summary===》 tf.summary.scalar
tf.train.SummaryWriter===》 to tf.summary.FileWriter
七、WARNING:initialize_all_variables(from tensorflow.python.ops.variables) is deprecated and will be removed after2017-03-02.
Instructions forupdating:
Use`tf.global_variables_initializer` instead.
程式碼改完後,就可以運行了。
Python3 train_GRU.py
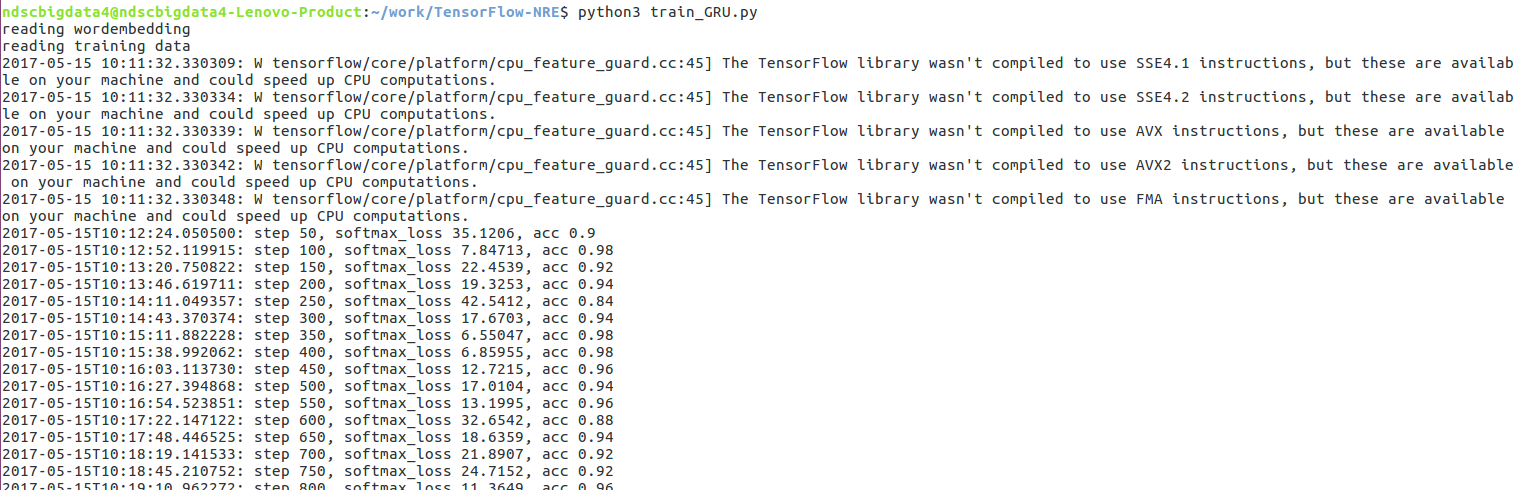
根據儲存的模型修改test.py中的testlist:

修改完後執行
Python3test_GRU.py
在眾多評測結果中我找到的比較好的結果是iter16000,結果如下
Evaluating [email protected] iter 16000
Evaluating [email protected] one
0.71
0.65
0.5866666666666667
Evaluating [email protected] two
0.72
0.64
0.62
Evaluating [email protected] all
0.74
0.705
0.6533333333333333
2017-05-15T16:12:42.613068
Evaluating alltest data and save data for PR curve
saving all testresult...
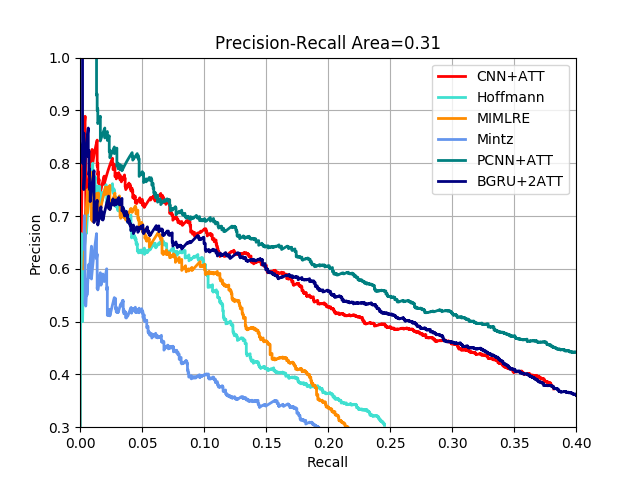
PR curvearea:0.309841978919
2017-05-15T16:15:40.915434
[email protected] for all testdata:
0.7
0.665
0.65
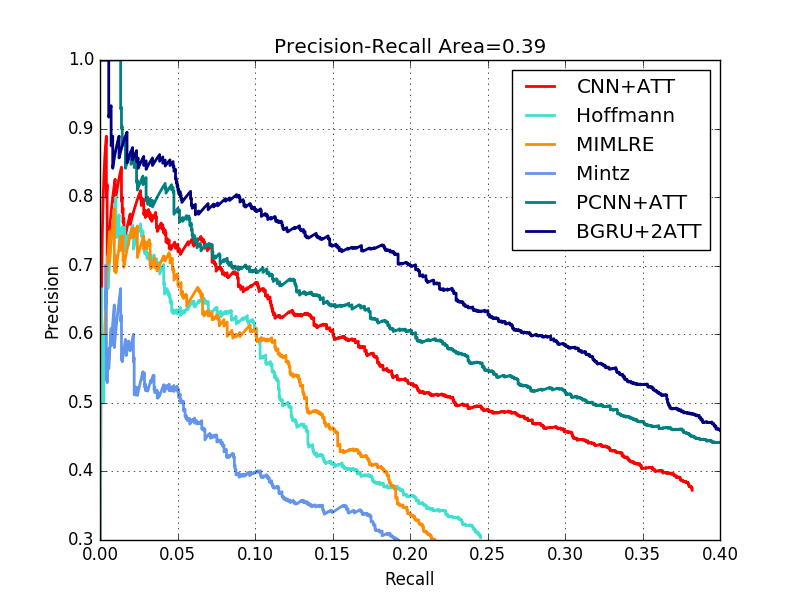
而作者找到的較好的結果是iter10900,PR曲線 ,可見其效果是最好的。
而我得到的PR曲線如下,效果跟CNN+ATT差不多
參考資料: