
跨領域對抗訓練在關係抽取中的應用
Genre Separation Network with Adversarial Training for Cross-genre
Relation Extraction
Abstract
論文的動機來源與主流關係抽取模型在不同的領域甚至是不同的資料集上效能的參差不齊。論文中提出了一種領域分離網路,其含有基於本領域獨立的編碼器,和基於領域共享的編碼器。該網路可以抽取特定型別和型別未知的兩種型別特徵。
Approach
Overview
這篇輪文的主要任務如下:
![]()
si代表一個由若干單片語成的句子,ei1和ei2代表句子中的兩個實體,ri代表這兩個實體在句子中表達的某種關係。我們對源型別資料S建立模型,最後要將此模型應用到其他不同型別的領域當中去。
Genre Separation Network (GSN)

如圖一所示,我們的目標就是去區分出不可知特徵(如圖中紅色矩形),具體特殊特徵(如圖中藍色和綠色)。我們用一個源型別私有CNN去抽取具體明確的私有特徵fsp,用一個共享CNN去抽取型別未知的特徵fsc。相同的我們同樣的從其他目標型別領域中去抽取ftp和ftc。
對於一個源型別句子![]() ,s中的每個單詞wi可以被向量化的表示為 vi=
,s中的每個單詞wi可以被向量化的表示為 vi=![]() 。
。
這裡vi是一個預訓練好的詞向量,pi代表句子中兩個實體的位置embedding,ti代表句子中兩個實體的型別embedding,ci是分類embedding,ηi代表是否word對於實體e1 e2 有最短路徑(具體可以參閱
為了區分出這四種不同型別的特徵,我們使用loss(squared Frobenius norm)來區分。
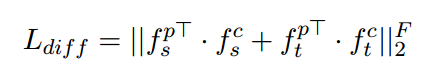
為了將各種型別的型別不可知特徵限制為共享特徵空間,我們使用對抗網路來訓練。
論文中將源領域和目標領域的genre-agnostic features送到GRL(http://jmlr.org/papers/volume17/15-239/15-239.pdf)層中,同過GRL層的處理模型將不能區分出輸入特徵是來自於源領域還是目標領域。
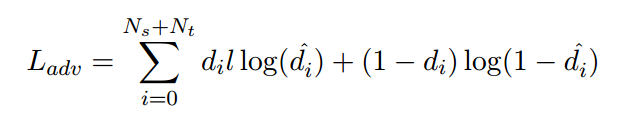
這裡di取值{0,1}用以區分樣例是來自於源領域還是目標領域,Ns和Nt分佈代表源領域和目標領域中的樣例數目,di^代表樣例來自於源領域的可能性(通過一個線性分類器得出的型別分類結果)。
Genre Reconstruction

Cross Genre Relation Extraction

將fs送入一個全連線層來獲得一個稠密向量,然後應用一個線性分類器來或得一個關係型別:

最後我們將loss函式線性結合用於多關係型別的關係分類:
