
對抗訓練在關係抽取中的應用
Adversarial Training for Relation Extraction
Abstract
對抗訓練是一種在訓練過程中加入噪聲的正則分類演算法。這篇論文在多例項多標籤的關係抽取任務中加入對抗噪聲來提升模型表現。通過在CNN和RNN兩種主流框架上進行對抗訓練,在兩種不同的資料集上都去得了不錯的效果。
Methodology
在多例項多標籤的關係抽取任務中,X={x1,x2,. . .,xn} 代表這些句子都包含一個相同的實體對。而我們任務就是給該實體對找到一個合適的關係型別:P(r| x1, . . . , xn)。
Sentence Encoder
對與每個句子xi,我們都希望通過非線性轉換來使其變成一個向量化的特徵表示si (si =f(xi; θ))。對於如何構造模型來使其滿足這一要求,我們採用關係抽取任務中常用的PCNN()和RNN來代替目標函式。
Selective Attention
一個實體對所要表達的關係取取決於所有包含該實體對的句子。這裡αr代表注意力權重。論文中下邊的公式來計算注意力權重:
![]()
這裡qr的embedding是根據關係r來計算的。
Loss Function
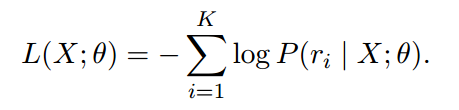
這裡由於是多標籤問題,K代表X表達的k種關係。
Dropout:
論文中對word embedding 使用dropout,對position embedding不使用dropout。
Adversarial Training
對抗訓練是一種正則化分類演算法,旨在通過對訓練資料增加小而持久的擾動來提高模型的魯棒性。增加擾動之後的損失函式就變成了如下形式了:
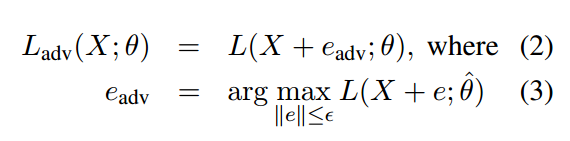
這裡Eadv就相當於對word embedding增加的小擾動。由於公式(3)在神經網路中難以計算,顧用一下公式代替:
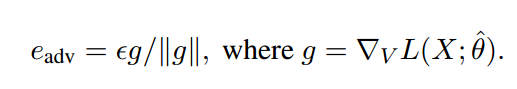
這裡V代表X中所有詞的向量化表示,||g||代表X中的所有單詞的梯度變化。

Experiments
For The NYT dataset


For The UW dataset


Discussion
對於CNN和RNN來說,CNN對於擾動較為敏感,RNN對於擾動較為穩定,這也說明了RNN在此任務中的魯棒性更好,這也是為什麼RNN的實驗效果更好的原因。再有,對於對抗網路的訓練,我們旨在對其施加小而持久的擾動,這樣才能提高網路的魯棒性。擾動過高會使得資訊的語義發生改變,從而降低模型的表現。