
12種降維方法終極指南(含Python程式碼)
阿新 • • 發佈:2019-01-01
你遇到過特徵超過1000個的資料集嗎?超過5萬個的呢?我遇到過。降維是一個非常具有挑戰性的任務,尤其是當你不知道該從哪裡開始的時候。擁有這麼多變數既是一個恩惠——資料量越大,分析結果越可信;也是一種詛咒——你真的會感到一片茫然,無從下手。
面對這麼多特徵,在微觀層面分析每個變數顯然不可行,因為這至少要幾天甚至幾個月,而這背後的時間成本是難以估計的。為此,我們需要一種更好的方法來處理高維資料,比如本文介紹的降維:一種能在減少資料集中特徵數量的同時,避免丟失太多資訊並保持/改進模型效能的方法。

什麼是降維?
每天,我們都會生成大量資料,而事實上,現在世界上約90%的資料都是在過去3到4年中產生的,這是個令人難以置信的現實。如果你不信,下面是收集資料的幾個示例:
● Facebook會收集你喜歡、分享、釋出、訪問的內容等資料,比如你喜歡哪家餐廳。
● 智慧手機中的各類應用會收集大量關於你的個人資訊,比如你所在的地點。
● 淘寶會收集你在其網站上購買、檢視、點選的內容等資料。
● 賭場會跟蹤每位客戶的每一步行動。
隨著資料的生成和資料收集量的不斷增加,視覺化和繪製推理圖變得越來越困難。一般情況下,我們經常會通過繪製圖表來視覺化資料,比如假設我們手頭有兩個變數,一個年齡,一個身高。我們就可以繪製散點圖或折線圖,輕鬆反映它們之間的關係。
下圖是一個簡單的例子:
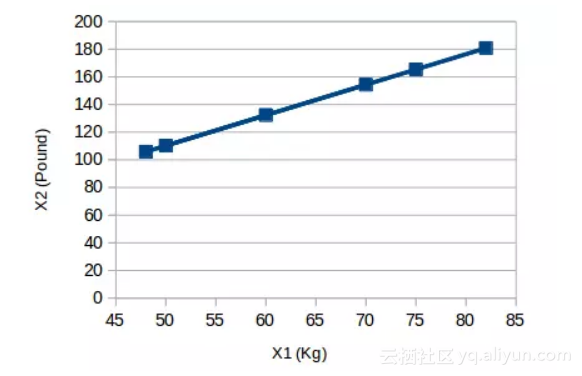
其中橫座標X1的單位為“千克”,縱座標X2的單位為“磅”。可以發現,雖然是兩個變數,但它們傳達的資訊是一致的,即物體的重量。所以我們只需選用其中的一個就能保留原始意義,把2維資料壓縮到1維(Y1)後,上圖就變成: