
人臉檢測演算法對比分析
人臉識別包括以下5個步驟:人臉檢測、影象預處理、特徵提取、匹配、結果輸出。
人臉檢測是人臉識別中的第一個環節,是一項關鍵技術。人臉檢測是指假設在輸入影象中存在一個或者多個人臉區域的情況下,確定影象中全部人臉的位置、大小和姿勢的過程。從教學理論上來講,人臉檢測本質上是對一副影象的特徵提取,如果提取了M個體徵,則此模式可以用一個M維特徵向量描述:x=(x1,x2,x3......xm),表現為M維歐式空間中的一個點。按照統計學的觀點,好的特徵提取方法必須滿足以下條件:特徵之間相互獨立,減小類內距離的同時增大類間距離,特徵向量的維數m儘量小。參考文章:《幾種人臉檢測演算法的對比研究》趙東方、楊明、鄧世濤
人臉檢測演算法一般包括兩大類:基於統計的方法、基於結構特徵的方法;
方法1 基於直方圖粗分割和奇異值特徵的人臉檢測演算法((基於統計的方法))
適應:複雜背景下的人臉檢測
方法:在灰度基本均勻的平面上,雙眼、鼻、口成一定結構分佈特徵。先根據平滑的直方圖對影象進行粗分割,再根據一定的灰度空間對人眼進行定位,進而確定出人臉區域。
第一步:用高斯函式對直方圖進行平滑處理
第二步:眼睛的定位
第三步:基於奇異值特徵的人臉驗證
效果:檢測率較高,但耗時較長,平均每個影象需10~15秒,而且待檢測的影象中人臉姿勢、表情等比較固定,當臉部光照變化較大或臉部有陰影(特別是眼部區域)時,影象很難被檢測到。
方法2 基於二進小波變換的人臉檢測(基於統計的方法)
二進小波變換得到的低頻分量和高頻分量不是下采樣型的,他們具有平移不變性。而二進小波變換有兩個過程組成:學習過程和檢測過程。
缺點:在統計學習的過程中,對原始影象的要求比較高,當影象的背景相對複雜時,比如從側面拍攝人臉時,水平方向的和垂直方向的高低頻分量很難獲取,這將直接影響到自由引數的準確性,從而很大程度上影響人臉檢測的檢準率。
方法3基於AdaBoost演算法的人臉檢測
2010年viola和Jones引入積分圖的概念,提出了基於Haar-like特徵、級聯結構的AdaBoost演算法,成功應用於模式識別領域,實現了實時人臉檢測,使人臉檢測技術取得了突破性進展。為適應背景的複雜性,研究者提出了將膚色等人臉特徵和AdaBoost演算法相結合的人臉檢測新演算法。演算法首先結合人臉特徵,利用人臉特徵確定人臉的大致方向,然後用級聯結構的AdaBoost演算法進行驗證。下圖為該演算法的人臉檢測流程圖
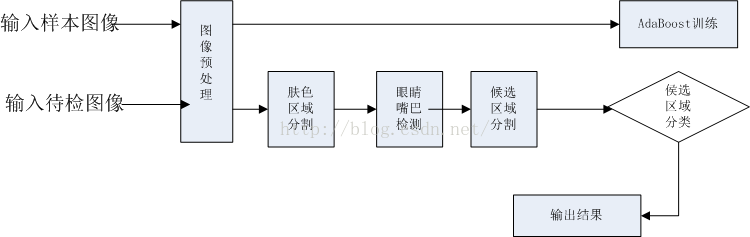
第一步:膚色區域檢測
膚色的差別主要是亮度的差別而非我們表面認知的色彩差別,因此檢測膚色區域時極容易受光照的影響,採用YCbCr色彩空間,可以使膚色有較好的聚類性。
第二步:人臉候選區域分割
在YCbCr色彩空間中,眼睛與面板的Cb和Cr分量有很大的差異,眼睛的灰度值相對較低,Y分量集中分佈在(0,120)內,而且眼睛的Cb分量普遍比Cr分量的值高,由此將眼睛的色彩和亮度對映結合起來就能檢測出眼睛區域的大小和位置。多數情況下嘴巴的方向和人臉的方向一致,具有很強的穩定性,嘴巴檢測的情況類似眼睛的檢測,此時Cb比Cr分量的值高很多,也就是說,嘴巴相對眼睛更容易檢測到。最後根據人體學特徵,根據人臉各部件的大體位置很容易確定人臉候選區域。
第三步:人臉候選區域分類
這一步利用AdaBoost演算法,通過對人臉候選區域進行積分圖計算,快速計算Harr-like特徵,利用AdaBoost演算法將Harr-like特徵生成的弱分類器疊加成為強分類器,再將多個強分類器級聯成人臉檢測分類器。
方法4 基於面部雙眼結構特徵的人臉檢測
首先在原始灰度影象上計算各畫素點的梯度方向對稱性,然後以梯度方向對稱性高的點為特徵點,並進一步組合成特徵塊,通過一種簡單的抑制方法,濾去大部分孤立的非人臉部件的特徵點,再運用一定的規則對各個特徵塊進行組合得到候選人臉區域最後對候選人臉進行人臉部件的驗證,剔除假臉,得到真正的人臉區域。
第一步:梯度方向對稱分佈特徵點的提取
第二步:雙眼特徵塊的提取
第三步:人眼的驗證