
論文:Dilated Convolutions閱讀筆記
Dilated Convolutions
目錄
1 概述
本模型提出了一種新的卷積神經網路模組,主要是為了解決密集預測的問題。本模型採用了膨脹卷積,使感受野得到了指數級的拓展,而不損失覆蓋率和解析度。它可以聚集多尺度的背景資訊,能應用在任何解決方案的框架當中。
現在主要有兩種方法來解決多尺度推理和密集預測的問題,其中一種是不斷地進行反向卷積,來恢復下采樣過程當中所丟失的資訊,另外一種是對輸入的影象進行多尺度的變換。但是這同樣引起了我們的質疑,下采樣是必要的嗎?對輸入進行多尺度變換是必要的嗎?
我們最終在PASCAL VOC 2012資料集上面進行了驗證,把這種新的卷積神經網路模組加入到現有的語義分割架構之中,發現準確度有了明顯的提升。
2 膨脹卷積操作

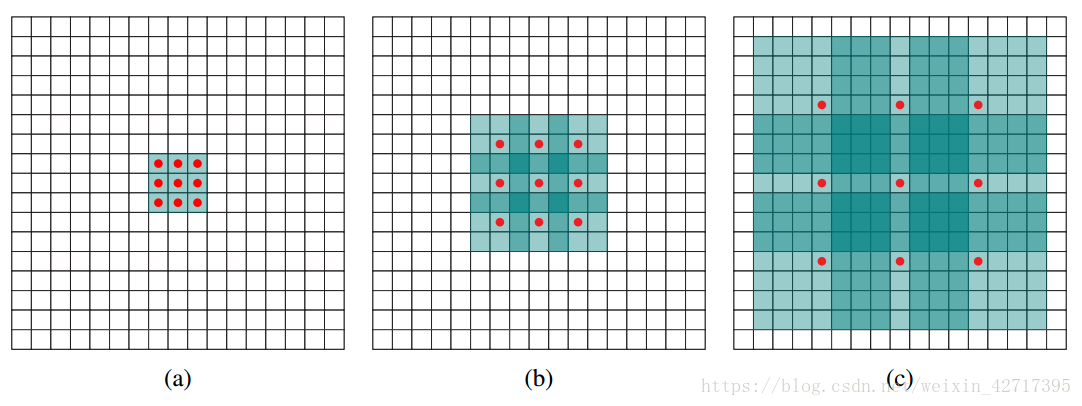
圖2-1 膨脹卷積示意圖

3 背景模型-多尺度聚集背景資訊
背景模組通過收集多尺度的背景資訊來提升架構密集預測的準確度。在基礎背景模型中我們定義每層有C個通道,則卷積運算元的維度為3*3*C。在此基礎上進行了1,1,2,4,6,8,16倍的膨脹操作。模型結構如圖3-1所示。最後的輸出進行1*1的卷積,每一個卷積都會經過max(.,0)函式的擷取操作。
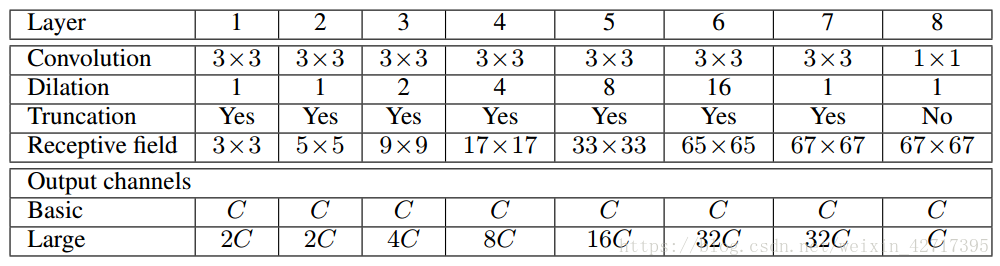
圖3-1 模型結構示意圖
在最初的嘗試中我們並沒有提高精確度,實驗證明初始化步驟中出現了問題。卷積神經網路通常在隨機分佈裡面取樣來初始化,但是這樣效果並不好。我們發現了一種更加高效的方法:
其中a是輸入特徵圖的索引,b為輸出特徵圖的索引。這使得每層簡單的將輸入傳遞給下一個,但並不會影響反向傳播對資訊的傳輸,同樣可以提高精確度。這個基礎背景模型同時提高了密集預測的質量和數量,但卻有很小的引數量,約為64。
我們訓練了一個大型背景模型,它在更深層使用更大特徵圖。和是連續的兩個層,服從正態分佈,是一個隨機噪聲,初始化操作為:

4 前端模型
我們訓練了一個前端預測模型,把一張彩色圖片作為輸入,並把一個C=21的特徵圖作為輸出。使用了VGG-16網路,去掉了所有的池化層,對所有池化層之後的特徵層使用2倍的膨脹卷積操作。

圖4-1 PASCAL VOC 2012訓練集模型指標對比示意圖
這個簡化的模型在PASCAL VOC 2012訓練集上面進行訓練,訓練是通過SGD(隨機梯度下降)進行的,引數分別設定為:mini-batch=14,learning rate=10^-3,momentum=0.9,iterations=60K。
我們和FCN-8s和Deeplab進行對比,結果如上圖所示,指標資料來自於VOC-2012。結果表明,我們的模型簡單又準確,與其他兩種方法相比,高出了5個百分點。
5 模型實驗
我們的模型實現是基於Caffe框架的,膨脹卷積已經成為了標準Caffe的一部分。實驗主要分兩個部分進行,在第一階段,同時在PASCAL VOC 2012和MS COCO資料集上面進行SGD訓練,引數分別設定為:mini-batch=14,momentum=0.9。先以learning rate=10^-3進行100K次迭代,先以learning rate=10^-4進行40K次迭代。在第二階段,只在PASCAL VOC 2012進行Fine-tuning,以learning rate=10^-5進行50K次迭代。從PASCAL VOC 2012驗證集上所得到的影象不用於訓練。
前端訓練的模型,在VOC-2012驗證集上面的mIoU達到了69.8%,在測試集上達到了71.3%。這個資料是由前端模組單獨實現的,還沒有新增背景模組和結構化預測模組。之後我們將Basic和large的背景模型都新增進前端模型。
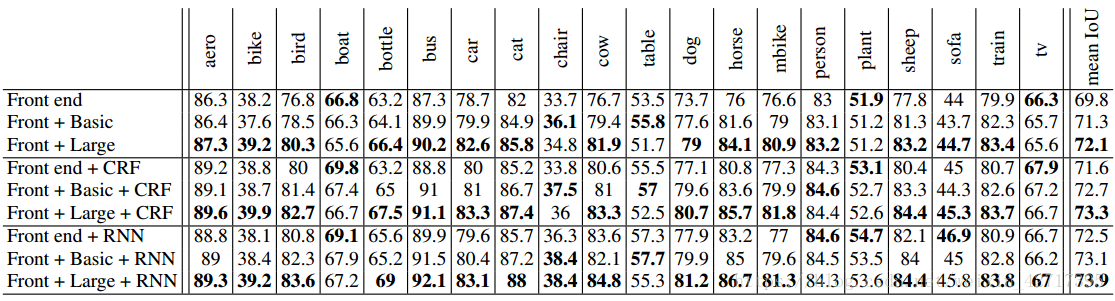
圖4-2 VOC-2012驗證集模型指標對比示意圖
如圖4-2所示,第一類中,並沒有加入結構化預測。第二類中,採用了CRF來執行結構化預測,並通過在驗證集上的網格預測來進行CRF的引數訓練。第三類中,採用了CRF-RNN來進行結構化預測。
從實驗結果可以看出來:
1)背景模型提升了準確率。
2)大型背景模型更大程度的提升了準確率。
3)背景模型和結構化預測可以協同工作。
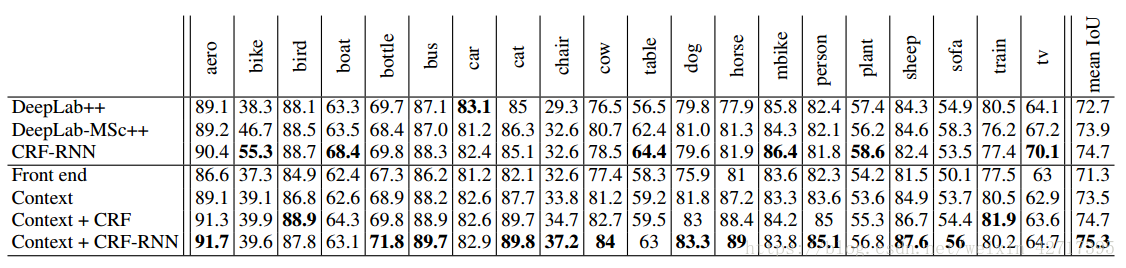
圖4-3 VOC-2012測試集模型指標對比示意圖
最後,我們將模型提交到VOC-2012測試集上面。從圖4-3的結果可以看出來,大型背景模型在前端模組的基礎上提升了準確率。沒有使用結構化預測的背景模型,優於DeepLab-CRF-COCO-LargeFOV。背景模型聯合CRF-RNN進一步提升了CRF-RNN的效果。
6 結論
- 膨脹卷積由於其擴大了感受野的大小,非常適用於密集預測。
- 設計了一種基於膨脹卷積的新型網路結構,當將之用於現有的語義分割系統時,可以很大程度上提高準確度。
- 附錄中給出了模型在三個資料集上對城市場景的表現:CanVid、KITTI、Cityscapes,並給出了在訓練過程中的引數配置,在github上釋出了訓練模型的程式碼。