
自然語言處理之word2vec原理詞向量生成
前言
word2vec是如何得到詞向量的?這個問題比較大。從頭開始講的話,首先有了文字語料庫,你需要對語料庫進行預處理,這個處理流程與你的語料庫種類以及個人目的有關,比如,如果是英文語料庫你可能需要大小寫轉換檢查拼寫錯誤等操作,如果是中文日語語料庫你需要增加分詞處理。這個過程其他的答案已經梳理過了不再贅述。得到你想要的processed corpus之後,將他們的one-hot向量作為word2vec的輸入,通過word2vec訓練低維詞向量(word embedding)就ok了。不得不說word2vec是個很棒的工具,目前有兩種訓練模型(CBOW和Skip-gram),兩種加速演算法(Negative Sample與Hierarchical Softmax)。本答旨在闡述word2vec如何將corpus的one-hot向量(模型的輸入)轉換成低維詞向量(模型的中間產物,更具體來說是輸入權重矩陣),真真切切感受到向量的變化,不涉及加速演算法。如果讀者有要求有空再補上。
1 Word2Vec兩種模型的大致印象
剛才也提到了,Word2Vec包含了兩種詞訓練模型:CBOW模型和Skip-gram模型。
- CBOW模型根據中心詞W(t)周圍的詞來預測中心詞
- Skip-gram模型則根據中心詞W(t)來預測周圍詞
拋開兩個模型的優缺點不說,它們的結構僅僅是輸入層和輸出層不同。請看:
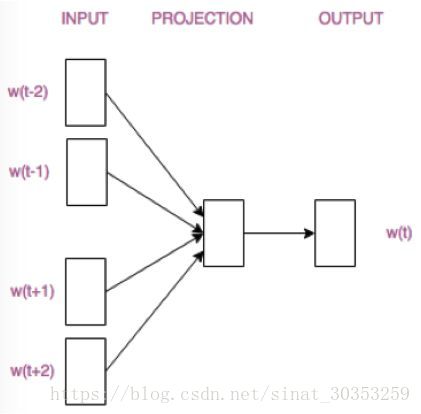
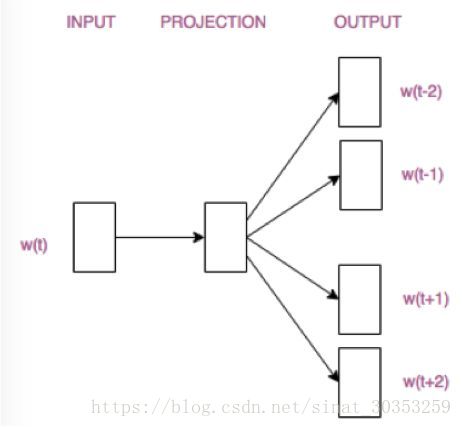
這兩張結構圖其實是被簡化了的,讀者只需要對兩個模型的區別有個大致的判斷和認知就ok了。接下來我們具體分析一下CBOW模型的構造,以及詞向量是如何產生的。理解了CBOW模型,Skip-gram模型也就不在話下啦。
2 CBOW模型的理解
其實數學基礎及英文好的同學可以參照斯坦福大學Deep Learning for NLP課堂筆記。
當然,懶省事兒的童鞋們就跟隨我的腳步慢慢來吧。
先來看著這個結構圖,用自然語言描述一下CBOW模型的流程:
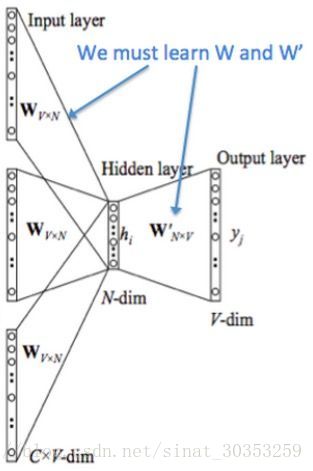
- 輸入層:上下文單詞的onehot. {假設單詞向量空間dim為V,上下文單詞個數為C}
- 所有onehot分別乘以共享的輸入權重矩陣W.{V*N矩陣,N為自己設定的數,初始化權重矩陣W}
- 所得的向量 {因為是onehot所以為向量} 相加求平均作為隱層向量,size為1*N.
- 乘以輸出權重矩陣W’ {N*V} 得到向量 {1*V} 啟用函式處理
- 得到V-dim概率分佈 {PS:因為是onehot嘛,其中的每一維斗代表著一個單詞},概率最大的index所指示的單詞為預測出的中間詞(target word)
- 與true label的onehot做比較,誤差越小越好
所以,需要定義loss function(一般為交叉熵代價函式),採用梯度下降演算法更新W和W’。訓練完畢後,輸入層的每個單詞與矩陣W相乘得到的向量的就是我們想要的詞向量(word embedding),這個矩陣(所有單詞的word embedding)也叫做look up table(其實聰明的你已經看出來了,其實這個look up table就是矩陣W自身),也就是說,任何一個單詞的onehot乘以這個矩陣都將得到自己的詞向量。有了look up table就可以免去訓練過程直接查表得到單詞的詞向量了。
這回就能解釋題主的疑問了!如果還是覺得我木有說明白,彆著急!跟我來隨著栗子走一趟CBOW模型的流程!
3 CBOW模型流程
舉例假設我們現在的Corpus是這一個簡單的只有四個單詞的document:
{I drink coffee everyday}
我們選coffee作為中心詞,window size設為2也就是說,我們要根據單詞”I”,”drink”和”everyday”來預測一個單詞,並且我們希望這個單詞是coffee。
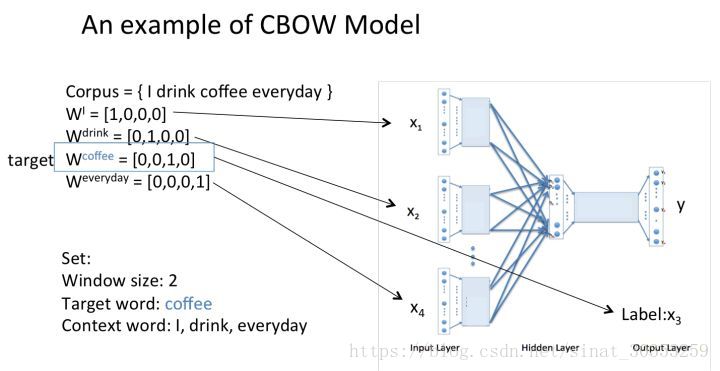
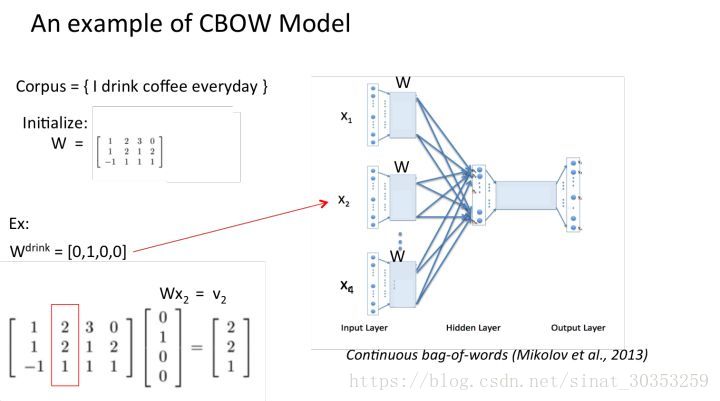
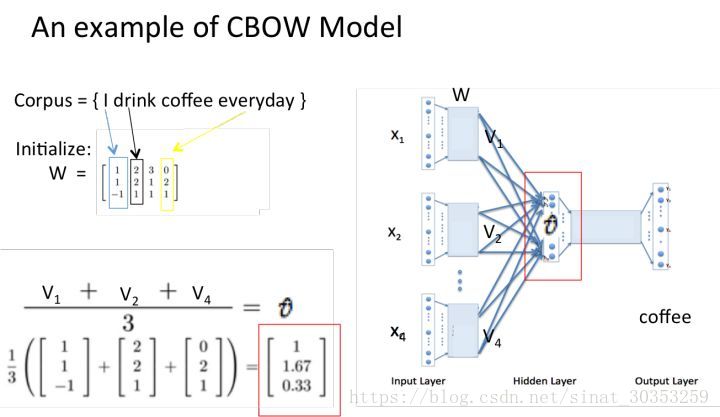
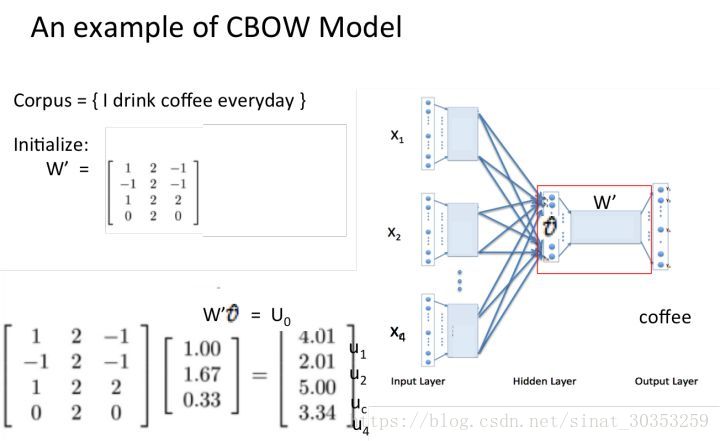

假設我們此時得到的概率分佈已經達到了設定的迭代次數,那麼現在我們訓練出來的look up table應該為矩陣W。即,任何一個單詞的one-hot表示乘以這個矩陣都將得到自己的word embedding。