
自然語言處理之中文分詞器詳解
中文分詞是中文文字處理的一個基礎步驟,也是中文人機自然語言互動的基礎模組,不同於英文的是,中文句子中沒有詞的界限,因此在進行中文自然語言處理時,通常需要先進行分詞,分詞效果將直接影響詞性,句法樹等模組的效果,當然分詞只是一個工具,場景不同,要求也不同。在人機自然語言互動中,成熟的中文分詞演算法能夠達到更好的自然語言處理效果,幫助計算機理解複雜的中文語言。
1基於詞典分詞演算法
基於詞典分詞演算法,也稱為字串匹配分詞演算法。該演算法是按照一定的策略將待匹配的字串和一個已經建立好的"充分大的"詞典中的詞進行匹配,若找到某個詞條,則說明匹配成功,識別了該詞。常見的基於詞典的分詞演算法為一下幾種:正向最大匹配演算法,逆向最大匹配法,最少切分法和雙向匹配分詞法等。
基於詞典的分詞演算法是應用最廣泛,分詞速度最快的,很長一段時間內研究者在對對基於字串匹配方法進行優化,比如最大長度設定,字串儲存和查詢方法以及對於詞表的組織結構,比如採用TRIE索引樹,雜湊索引等。
這類演算法的優點:速度快,都是O(n)的時間複雜度,實現簡單,效果尚可,
演算法的缺點:對歧義和未登入的詞處理不好。
2基於理解的分詞方法
這種分詞方法是通過讓計算機模擬人對句子的理解,達到識別詞的效果,其基本思想就是在分詞的同時進行句法、語義分析,利用句法資訊和語義資訊來處理歧義現象,它通常包含三個部分:分詞系統,句法語義子系統,總控部分,在總控部分的協調下,分詞系統可以獲得有關詞,句子等的句法和語義資訊來對分詞歧義進行判斷,它模擬來人對句子的理解過程,這種分詞方法需要大量的語言知識和資訊,由於漢語言知識的籠統、複雜性,難以將各種語言資訊組成及其可以直接讀取的形式,因此目前基於理解的分詞系統還在試驗階段。
3基於統計的機器學習演算法
這類目前常用的演算法是HMM,CRF,SVM,深度學習等演算法,比如stanford,Hanlp分詞工具是基於CRF演算法。以CRF為例,基本思路是對漢字進行標註訓練,不僅考慮了詞語出現的頻率,還考慮上下文,具備良好的學習能力,因此對歧義詞和未登入詞的識別都具有良好的效果。
Nianwen Xue在其論文中《Combining Classifier for Chinese Word Segmentation》中首次提出對每個字元進行標註,通過機器學習演算法訓練分類器進行分詞,在論文《Chinese word segmentation as character tagging》中較為詳細地闡述了基於字標註的分詞法。
演算法優點:能很好處理歧義和未登入詞問題,效果比前一類效果好
演算法缺點: 需要大量的人工標註資料,以及較慢的分詞速度
4現行常見的中文詞分類器
常見的分詞器都是使用機器學習演算法和詞典相結合的演算法,一方面能夠提高分詞準確率,另一方面能夠改善領域適應性。
隨著深度學習的興起,也出現了基於神經網路的分詞器,例如有研究人員嘗試使用雙向LSTM+CRF實現分詞器,其本質上是序列標註,所以有通用性,命名實體識別等都可以使用該模型,據報道其分詞器字元準確率可以高達97.5%,演算法框架的思路與論文《Neural Architectures for Named Entity Recogintion》類似,利用該框架可以實現中文分詞,如下圖所示
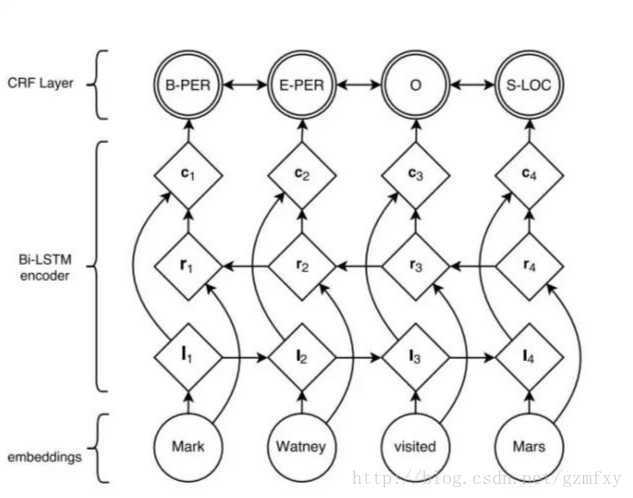
首先對語料進行字元嵌入,將得到的特徵輸入給雙向的LSTM,然後加一個CRF就得到標註結果。
5分詞器當前存在問題
目前中文分詞難點主要有三個:
1. 分詞標準:比如人名,在哈工大的標準中姓和名是分開的,但是在Hanlp中是合在一起的,這需要根據不同的需求制定不同的分詞標準。
2. 歧義:對於同一個待切分字串存在多個分詞結果。
歧義又分為組合歧義,交集型歧義和真歧義三種分類。
1)組合型歧義:分詞是有不同的粒度的,指某個詞條中的一部分也可以切分未一個獨立的詞條,比如“中華人民共和國”,粗粒度的分詞就是“中華人民共和國”,細粒度的分詞可能是“中華/人民/共和國”
2)交集型歧義:在“鄭州天和服裝廠”中,“天和”是廠名,是一個專有名詞,“和服”也是一個詞,它們共用了“和”字
3)真歧義:本身的語法和語義都沒有問題,即便採用人工切分也會產生同樣的歧義,只有通過上下文的語義環境才能給出正確的切分結果,例如:對於句子“美國會通過對臺售武法案”,既可以切分成“美國/會/通過...”也可以切分成“美/國會/通過...”
一般在搜尋引擎中,構建索引時和查詢時會使用不同的分詞演算法,常用的方案是,在索引的時候,使用細粒度的分詞以保證召回,在查詢的時候使用粗粒度的分詞以保證精度。
3. 新詞:也稱未被詞典收錄的詞,該問題的解決依賴於人們對分詞技術和漢語語言結構進一步認識。
6部分分詞工具集合
中科院計算所NLPIR http://ictclas.nlpir.org/nlpir/
ansj分詞器 https://github.com/NLPchina/ansj_seg
哈工大的LTP https://github.com/HIT-SCIR/ltp
清華大學THULAC https://github.com/thunlp/THULAC
斯坦福分詞器 https://nlp.stanford.edu/software/segmenter.shtml
Hanlp分詞器 https://github.com/hankcs/HanLP
結巴分詞 https://github.com/yanyiwu/cppjieba
KCWS分詞器(字嵌入+Bi-LSTM+CRF) https://github.com/koth/kcws
ZPar https://github.com/frcchang/zpar/releases
IKAnalyzer https://github.com/wks/ik-analyzer
以及部分分詞器的簡單說明:
哈工大的分詞器:主頁上給過呼叫介面,每秒請求的次數有限制。
清華大學THULAC:目前已經有Java、Python和C++版本,並且程式碼開源。
斯坦福分詞器:作為眾多斯坦福自然語言處理中的一個包,目前最新版本3.7.0, Java實現的CRF演算法。可以直接使用訓練好的模型,也提供訓練模型介面。
Hanlp分詞:求解的是最短路徑。優點:開源、有人維護、可以解答。原始模型用的訓練語料是人民日報的語料,當然如果你有足夠的語料也可以自己訓練。
結巴分詞工具:基於字首詞典實現高效的詞圖掃描,生成句子中漢字所有可能成詞情況所構成的有向無環圖 (DAG);採用了動態規劃查詢最大概率路徑, 找出基於詞頻的最大切分組合;對於未登入詞,採用了基於漢字成詞能力的 HMM 模型,使用了 Viterbi 演算法。
字嵌入+Bi-LSTM+CRF分詞器:本質上是序列標註,這個分詞器用人民日報的80萬語料,據說按照字元正確率評估標準能達到97.5%的準確率,各位感興趣可以去看看。
ZPar分詞器:新加坡科技設計大學開發的中文分詞器,包括分詞、詞性標註和Parser,支援多語言,據說效果是公開的分詞器中最好的,C++語言編寫。
7關於速度
由於分詞是基礎元件,其效能也是關鍵的考量因素。通常,分詞速度跟系統的軟硬體環境有相關外,還與詞典的結構設計和演算法複雜度相關。比如我們之前跑過字嵌入+Bi-LSTM+CRF分詞器,其速度相對較慢。另外,開源專案https://github.com/ysc/cws_evaluation曾對多款分詞器速度和效果進行過對比,可供大家參考。
最後附上公開的分詞資料集
測試資料集
1、SIGHAN Bakeoff 2005 MSR,560KB
http://sighan.cs.uchicago.edu/bakeoff2005/
2、SIGHAN Bakeoff 2005 PKU, 510KB
http://sighan.cs.uchicago.edu/bakeoff2005/
3、人民日報 2014, 65MB
https://pan.baidu.com/s/1hq3KKXe
參考內容:
| 本文來源於知乎專欄中Emotibot對中文分詞方案的回答,來源地址為:https://www.zhihu.com/question/19578687
歡迎關注公眾號學習自然語言處理技術
