Spark叢集搭建與並驗證環境是否搭建成功(三臺機器)
在之前hadoop的基礎上,進行Spark分散式叢集:
(1)下載Spark叢集需要的基本軟體,本篇需要的是:Scala-2.10.4、spark-1.4.0-bin-hadoop
(2)安裝Spark叢集需要的每個軟體
(3)啟動並檢視叢集的狀況
(4)t通過spark-shell測試spark工作
1.Spark叢集需要的軟體
在前面構建好的hadoop叢集的基礎上構建spark叢集,這裡需要的軟體主要是:Scala-2.10.4、spark-1.4.0-bin-hadoop,從網上可以下載到這兩個版本的安裝包,以防萬一,我這裡提供下載地址:http://pan.baidu.com/s/1kVFtn9d
2.安裝Scala與Spark
2.1 安裝scala
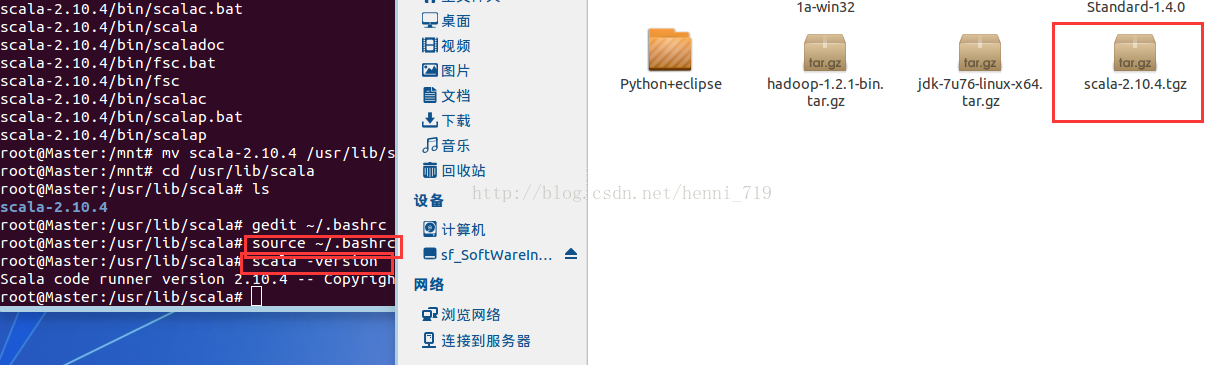
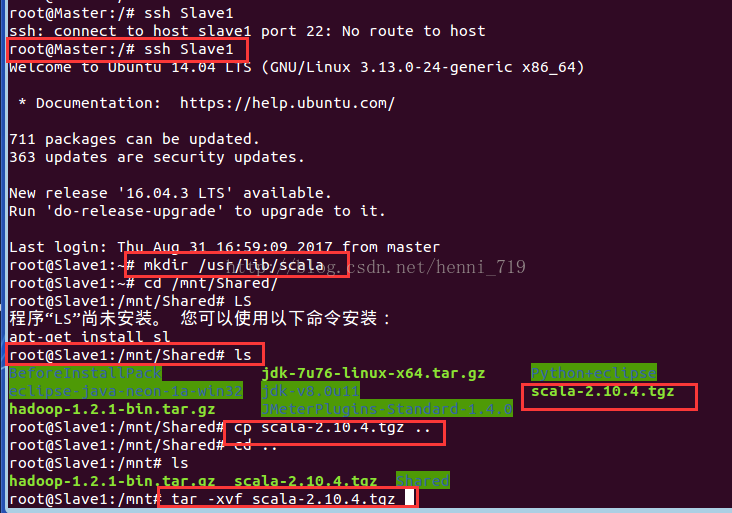
在Master節點上,開啟終端執行命令:mkdir /usr/llib/scala,進入到下載檔案目錄下,解壓scala壓縮檔案,執行類似於下圖操作:

把解壓的scala檔案移動到建立的目錄下!
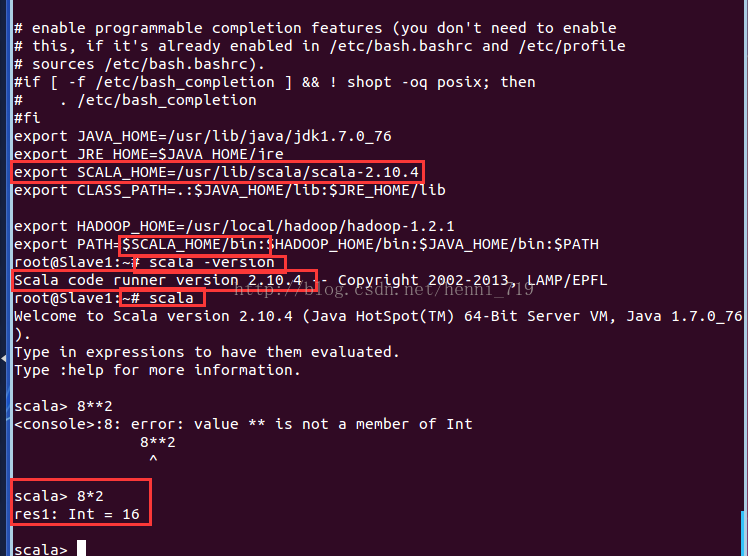
修改環境變數,操作截圖如下:

執行下圖所示操作,使環境配置修改生效,並檢測scala是否安裝成功!
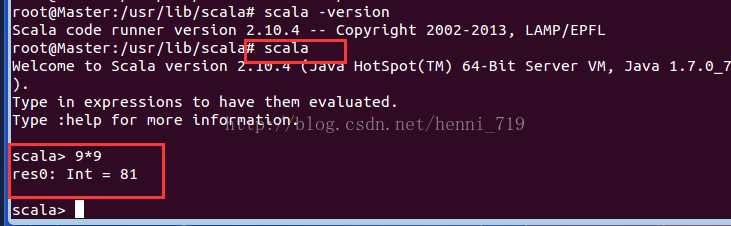
在命令列,直接輸入scala進入scala命令互動介面,操作如下截圖:
關於Slave1與Slave2的操作截圖如下所示:

由於gedit無法使用,所以通過scp命令進行了複製!



2.2 安裝Spark
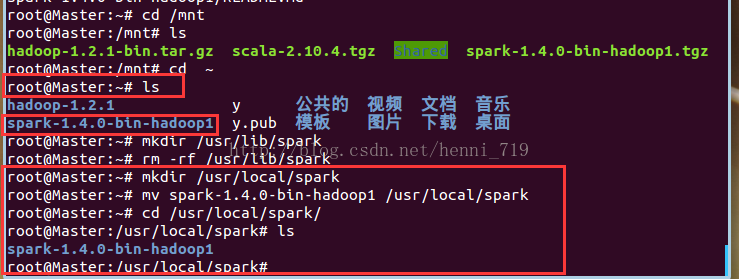
進入到下載目錄下,解壓spark壓縮檔案:

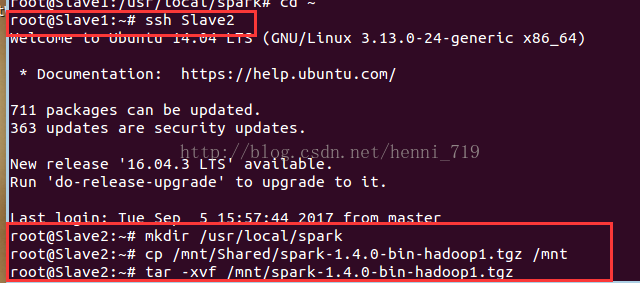
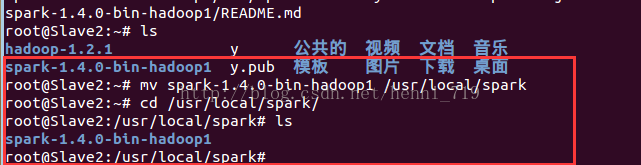
開啟終端,執行命令:mkdir /usr/local/spark,移動解壓的spark檔案,操作截圖:
配置spark環境變數,操作截圖如下:
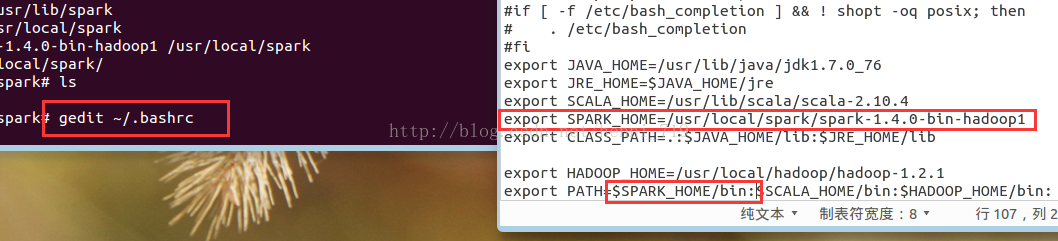
執行如下命令,是修改配置生效:

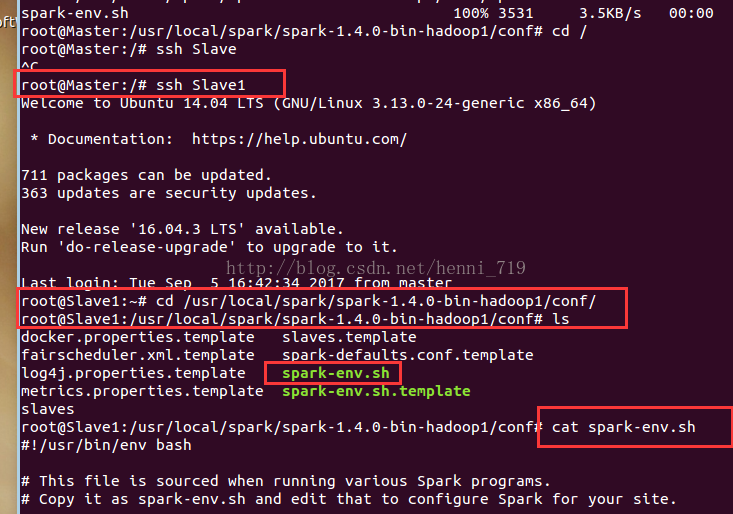
進入到spark的conf目錄下,把spark-env.sh.template檔案拷貝到spark-env.sh,並進行編輯,操作截圖如下:
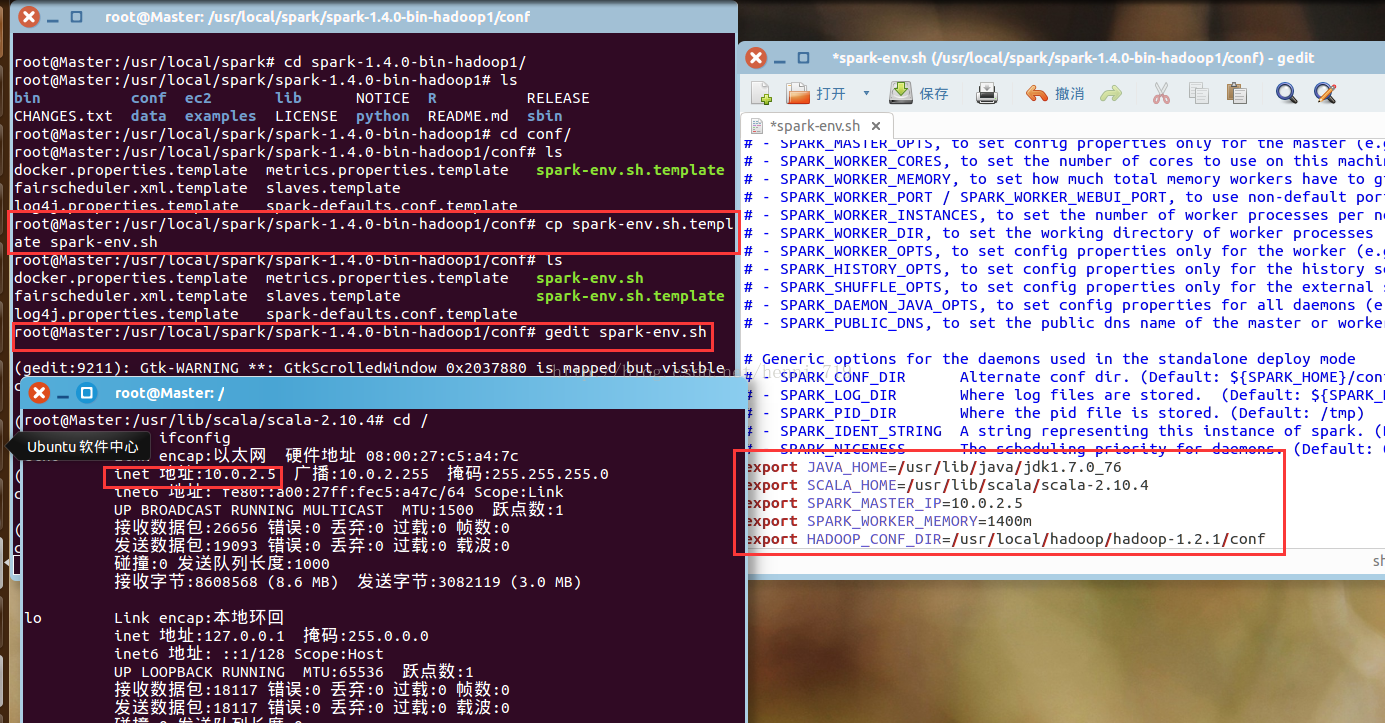
spark-env.sh配置成功後!
接下來配置spark的conf下slaves檔案,把Worker節點都新增進去,順序執行操作截圖如下:
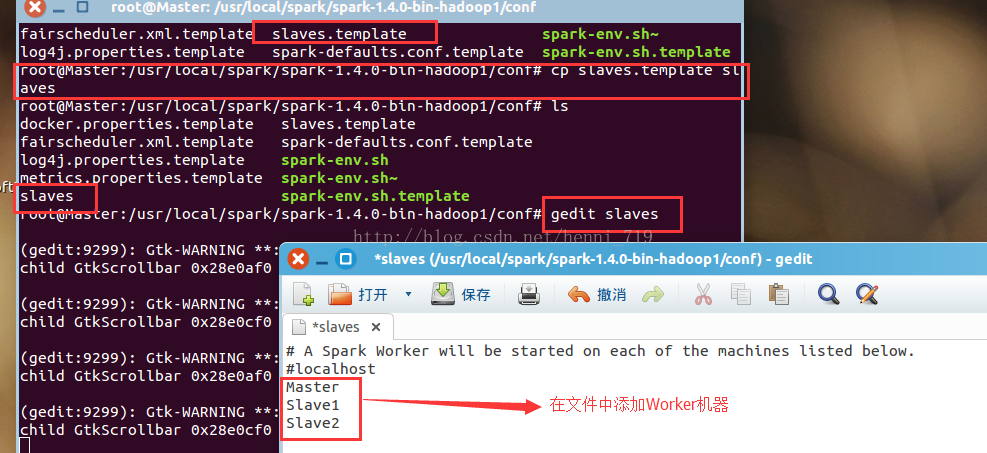
上述是對於master節點的spark配置,關於slave1與slave2節點的操作截圖如下:
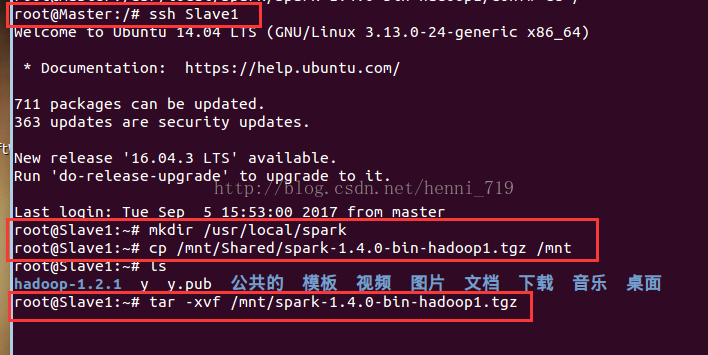
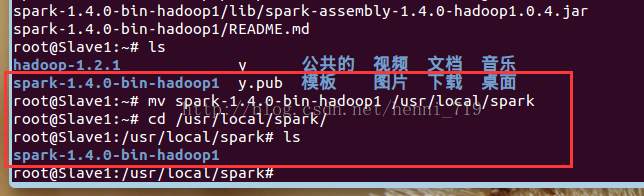

3.啟動並檢視叢集狀況
在master節點上執行命令啟動hadoop服務,啟動之後,執行jps檢視程序,三臺機器截圖如下:
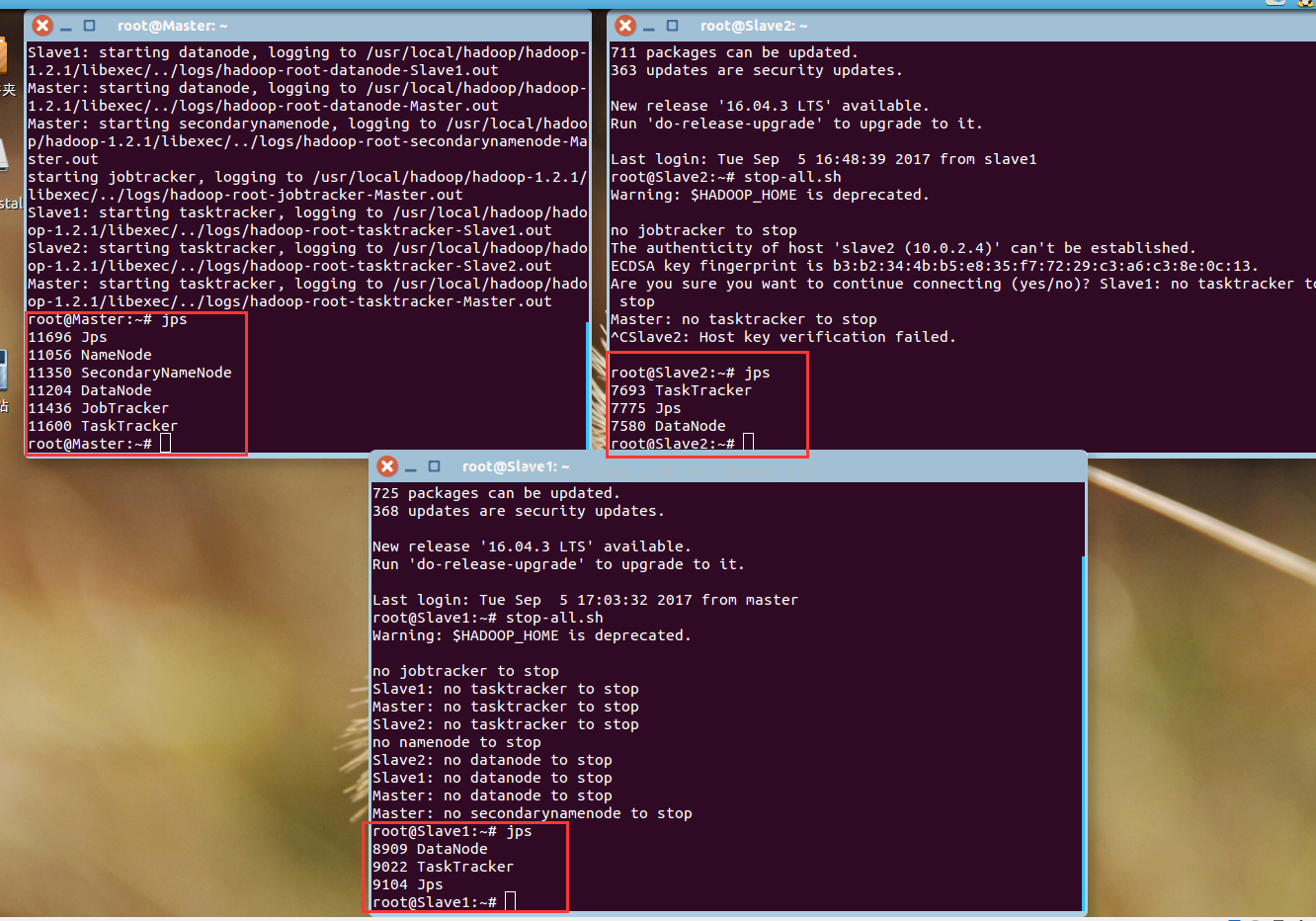
hadoop啟動成功後,在master節點上,進入到spark的sbin目錄下,執行命令:./start-all.sh
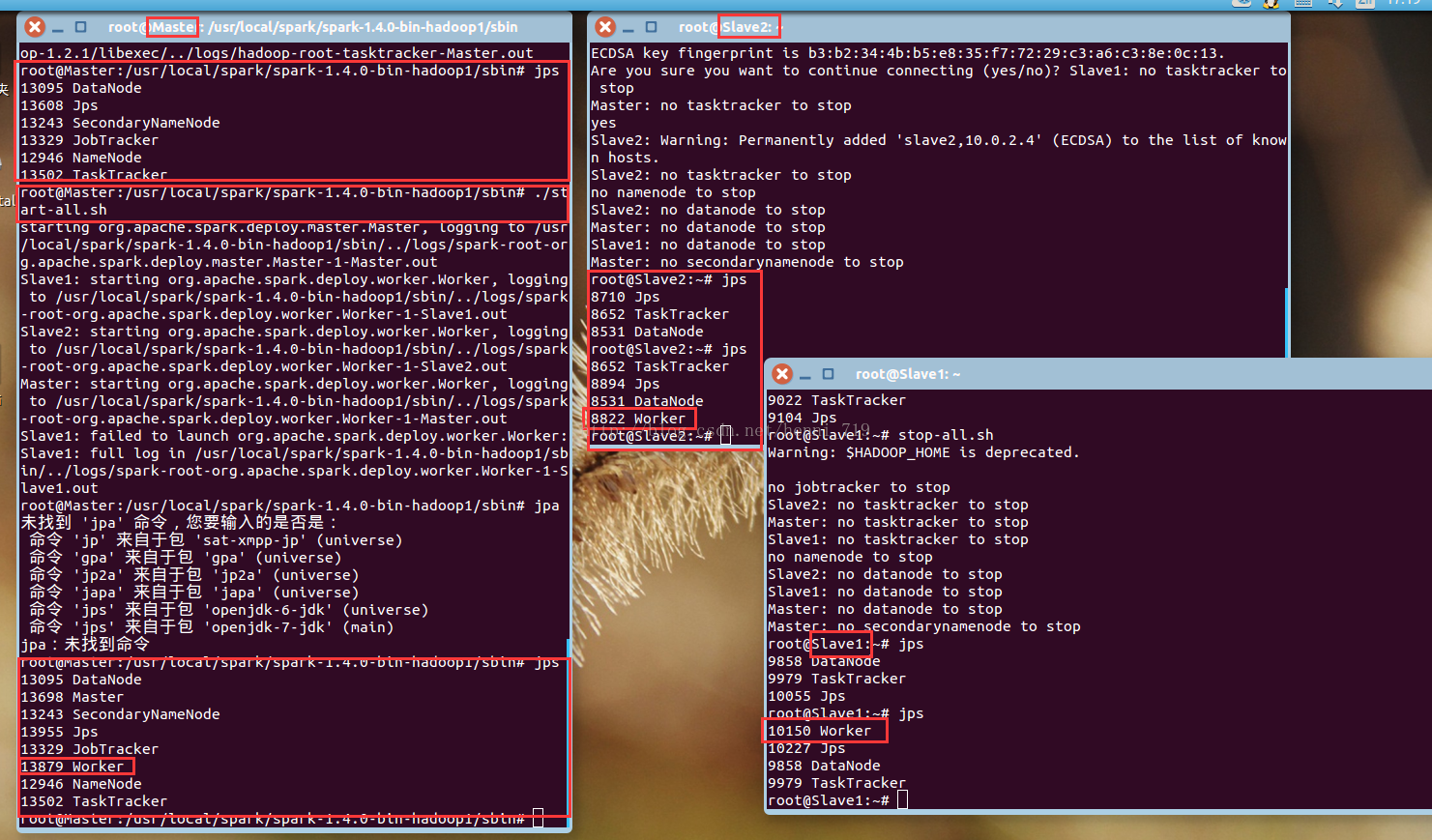
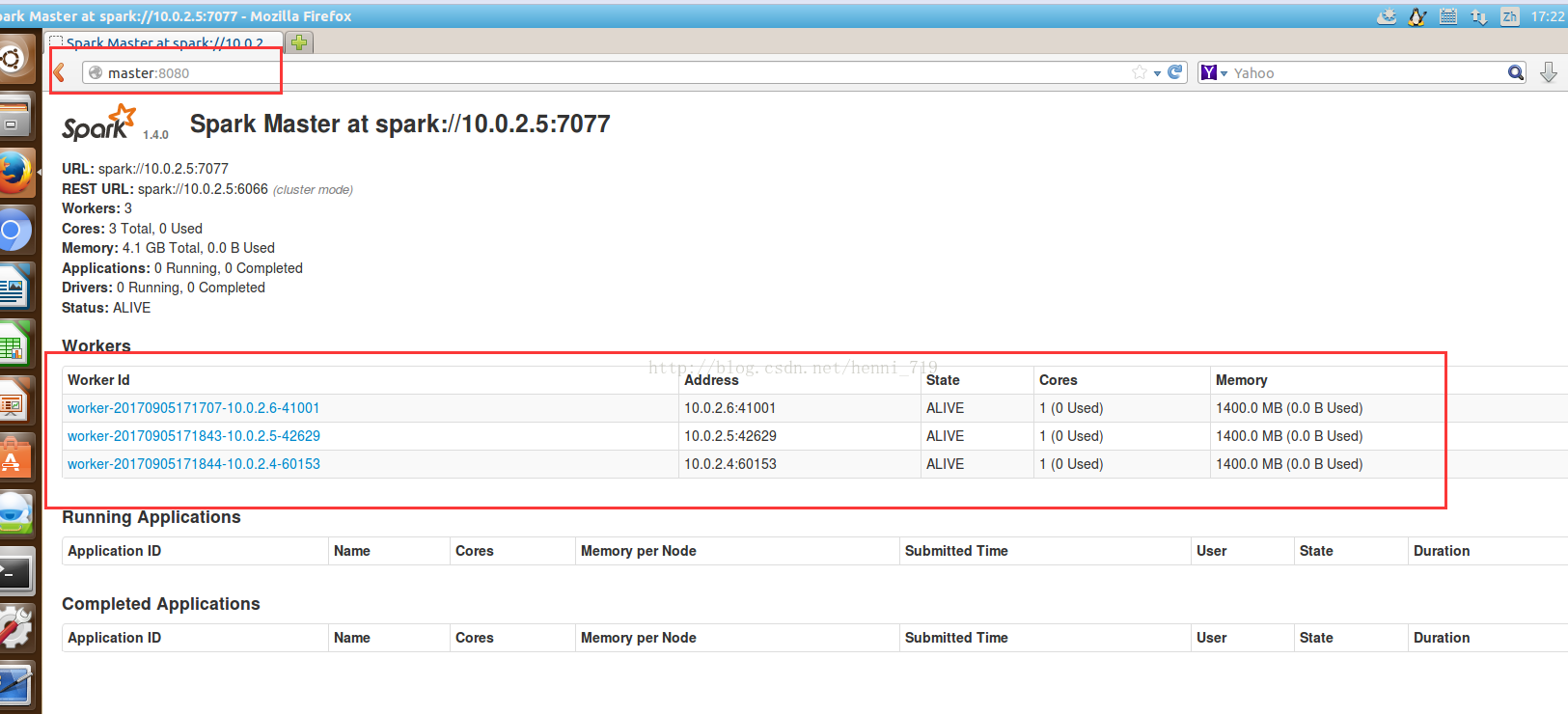
會在主節點看到Master與Worker程序,在slave1與slave2看到worker程序!進入到spark叢集的文字介面,訪問:http://master:8080,看到三個worker,截圖如下:
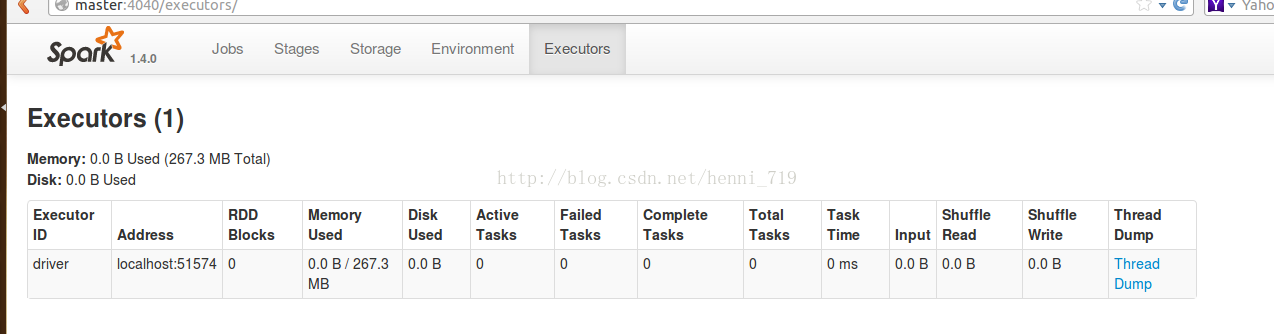
進入spark-shell,然後在http://master:4040,截圖如下: