
[NLP技術]關鍵詞提取演算法-TextRank
關鍵詞提取演算法-TextRank
今天要介紹的TextRank是一種用來做關鍵詞提取的演算法,也可以用於提取短語和自動摘要。因為TextRank是基於PageRank的,所以首先簡要介紹下PageRank演算法。
1.PageRank演算法
PageRank設計之初是用於Google的網頁排名的,以該公司創辦人拉里·佩奇(Larry Page)之姓來命名。Google用它來體現網頁的相關性和重要性,在搜尋引擎優化操作中是經常被用來評估網頁優化的成效因素之一。PageRank通過網際網路中的超連結關係來確定一個網頁的排名,其公式是通過一種投票的思想來設計的:如果我們要計算網頁A的PageRank值(以下簡稱PR值),那麼我們需要知道有哪些網頁連結到網頁A,也就是要首先得到網頁A的入鏈,然後通過入鏈給網頁A的投票來計算網頁A的PR值。這樣設計可以保證達到這樣一個效果:當某些高質量的網頁指向網頁A的時候,那麼網頁A的PR值會因為這些高質量的投票而變大,而網頁A被較少網頁指向或被一些PR值較低的網頁指向的時候,A的PR值也不會很大,這樣可以合理地反映一個網頁的質量水平。那麼根據以上思想,佩奇設計了下面的公式.
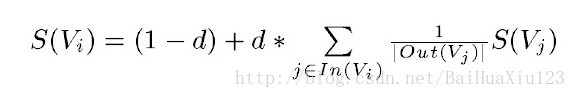
該公式中,Vi表示某個網頁,Vj表示連結到Vi的網頁(即Vi的入鏈),S(Vi)表示網頁Vi的PR值,In(Vi)表示網頁Vi的所有入鏈的集合,Out(Vj)表示網頁,d表示阻尼係數,是用來克服這個公式中“d *”後面的部分的固有缺陷用的:如果僅僅有求和的部分,那麼該公式將無法處理沒有入鏈的網頁的PR值,因為這時,根據該公式這些網頁的PR值為0,但實際情況卻不是這樣,所有加入了一個阻尼係數來確保每個網頁都有一個大於0的PR值,根據實驗的結果,在0.85的阻尼係數下,大約100多次迭代PR值就能收斂到一個穩定的值,而當阻尼係數接近1時,需要的迭代次數會陡然增加很多,且排序不穩定。公式中S(Vj)前面的分數指的是Vj所有出鏈指向的網頁應該平分Vj的PR值,這樣才算是把自己的票分給了自己連結到的網頁。
2.1 TextRank演算法提取關鍵詞
TextRank是由PageRank改進而來,其公式有頗多相似之處,這裡給出TextRank的公式:
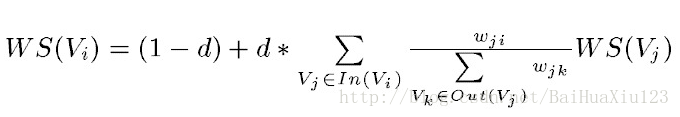
可以看出,該公式僅僅比PageRank多了一個權重項Wji,用來表示兩個節點之間的邊連線有不同的重要程度。TextRank用於關鍵詞提取的演算法如下:
1)把給定的文字T按照完整句子進行分割,即
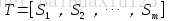
2)對於每個句子,進行分詞和詞性標註處理,並過濾掉停用詞,只保留指定詞性的單詞,如名詞、動詞、形容詞,即,其中 ti,j 是保留後的候選關鍵詞。
3)構建候選關鍵詞圖G = (V,E),其中V為節點集,由(2)生成的候選關鍵片語成,然後採用共現關係(co-occurrence)構造任兩點之間的邊,兩個節點之間存在邊僅當它們對應的詞彙在長度為K的視窗中共現,K表示視窗大小,即最多共現K個單詞。
4)根據上面公式,迭代傳播各節點的權重,直至收斂。
5)對節點權重進行倒序排序,從而得到最重要的T個單詞,作為候選關鍵詞。
6)由5得到最重要的T個單詞,在原始文字中進行標記,若形成相鄰片語,則組合成多詞關鍵詞。
2.2 TextRank演算法提取關鍵詞短語
提取關鍵詞短語的方法基於關鍵詞提取,可以簡單認為:如果提取出的若干關鍵詞在文字中相鄰,那麼構成一個被提取的關鍵短語。
2.3TextRank生成摘要
將文字中的每個句子分別看做一個節點,如果兩個句子有相似性,那麼認為這兩個句子對應的節點之間存在一條無向有權邊。考察句子相似度的方法是下面這個公式:
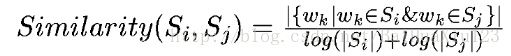
公式中,Si,Sj分別表示兩個句子,Wk表示句子中的詞,那麼分子部分的意思是同時出現在兩個句子中的同一個詞的個數,分母是對句子中詞的個數求對數之和。分母這樣設計可以遏制較長的句子在相似度計算上的優勢。
原文地址
http://www.cnblogs.com/xueyinzhe/p/7101295.html