
筆記:關鍵詞提取演算法
關鍵詞提取演算法一般也能分為有監督和無監督。
1、有監督的關鍵詞提取演算法主要是通過分類的方式進行的,通過構建一個較為豐富和完善的詞表,然後通過判斷每個文件與詞表中每個詞的匹配程度,以類似打標籤的方式,達到關鍵詞提取的效果。有監督的方法能夠獲取到較高的精度,但缺點是需要大批量的標註資料,人工成本過高。另外,會有大量的資訊出現,一個固定的詞表有時很難將資訊的內容表達出來。
2、而無監督的方法對資料要求低,受到了大家的青睞。目前較常用的是:TF-IDF演算法,TextRank演算法和主題模型演算法(包括LSA,LSI,LDA等)。
1、TF-IDF演算法
TF演算法是統計一個詞在一篇文件中出現的頻次,其基本思想是,一個詞在文件中出現的詞數越多,則其對文件的表達能力也就越強。
tf(word)=(word在文件中出現的次數)/(文件總次數)
IDF演算法則是統計一個詞在文件集的多少個文件中出現,其基本思想是,如果一個詞在越少的文件中出現,則其對文件的區分能力也就越強。
idf(word)=log((文件集中總文件數)/(1+(文件集中出現詞word的文件數量)))
分母加1是採用了拉普拉斯平滑,避免有部分新的詞沒有再語料庫中出現過而導致分母為零。
TF-IDF=TF*IDF
2、TextRank
該演算法可以脫離語料庫的背景,僅對單篇文件進行分析就可以提取該文件的關鍵詞。
該演算法最早用於文件的自動摘要,基於句子維度的分析,利用TextRank對每個句子進行打分,挑選出分數最高的n個句子作為文件的關鍵句,以達到自動摘要的效果。
TextRank起源於PageRank演算法,後者是一種網頁排名演算法,其基本思想有兩條:
(1)連結數量。一個網頁被越多的其它網頁連結,說明這個網頁越重要。
(2)連結質量。一個網頁被一個越高權值的網頁連結,也能表面這個網頁越重要。
計算每個句子給它連結句的貢獻是,不是通過平均分配的方式,而是通過計算權重佔總權重的比例來分配。在這裡,權重就是兩個句子之間的相似度,相似度的計算可以採用編輯距離、餘弦相似度等。在對一篇文件進行自動摘要是,預設每個語句和其它所以句子都是有連結關係的,也就是一個有向完全圖。
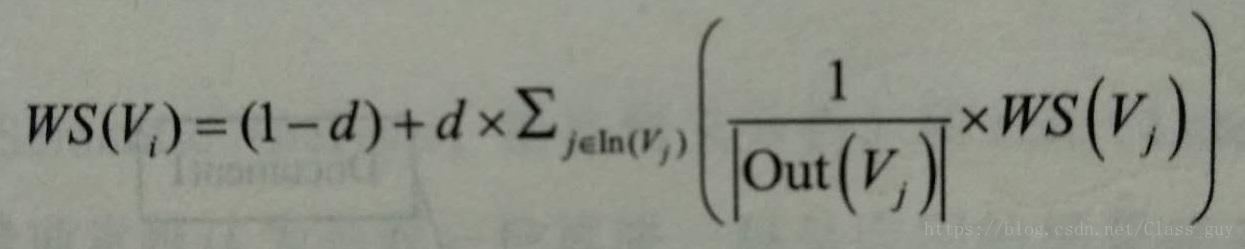
當TextRank應用到關鍵字抽取時,與應用到自動摘要中時有兩點不同:(1)詞與詞之間的關聯沒有權重,(2)每個詞不是與文件中所有詞都有連結。
當TextRank應用在關鍵詞提取中時,學者們提出了一個視窗的概念。在視窗中的詞相互間都有連結關係。得到了連結關係,就可以套用TextRank的公式,對每個詞的得分進行計算。最後選擇得分最高的n個詞作為文件的關鍵詞。
3、主題模型
如一篇講動物的文章,通篇介紹了許多的動物,但文中並沒有顯式的出現動物二字,這種情況下,前面兩種演算法顯然不能提取出動物這個隱含的主題資訊,這時就需要用到主題模型。
主題模型認為在詞與文件之間沒有直接的聯絡,它們應當還有一個維度將它們串聯起來,將這個維度稱為主題。每個文件都應該對應著一個或多個的主題,而每個主題都會有對應的詞分佈,通過主題,就可以得到每個文件的詞分佈。
P(word | doc)=P(word | topic)*P(topic | doc)
在一個已知的資料集中,每個詞和文件對應的P(word | doc)都是已知的。
3.1 LSA(潛在語義分析)/LSI(潛在語義索引)
二者通常被認為是同一種演算法,只是應用的場景越有不同,LSA是在需要構建的相關任務中的叫法。可以說,LSA和LSI都是對文件的潛在語義進行分析,但是潛在語義索引在分析後,還會利用分析的結果建立相關的索引。
LSA的主要步驟:
(1)使用BOW模型將每個文件表示為向量;
(2)將所有的文件詞向量拼接起來構成詞-文件矩陣(m*n)
(3)對詞-文件矩陣進行奇異值分解(SVD)操作([m*r].[r*r].[r*n])
(4)根據SVD結果,將詞-文件矩陣對映到一個更低維度k([m*k].[k*k].[k*n],0<k<r)的近似SVD結果,每個詞和文件都可以表示為k個主題構成的空間中的一個點。通過計算每個詞和文件的相似度。可以得到每個文件中對每個詞的相似度結果,取相似度最高的一個詞即為文件的關鍵詞。
LSA的優點:
可以對映到低維的空間,並在有限利用文字語義資訊的同時,大大降低計算的代價,提高分析質量。
缺點:
SVD的計算複雜度非常高,特徵空間維度較大,計算效率十分低下;
LSA得到的分佈資訊是基於已有資料集的,當一個新的文件進入到已有的特徵空間時,需要對整個空間重新訓練,以得到加入新文件後對應的分佈資訊;
LSA對詞的頻率分佈不敏感、物理解釋性薄弱的問題。
3.2 LDA演算法
該演算法的理論基礎是貝葉斯理論。
LDA 演算法假設文件中主題的先驗分佈和主題中詞的先驗分佈都服從狄利克雷分佈。
結合吉布斯取樣的LDA模型訓練過程:
(1)隨機初始化,對語料中每篇文件中的每個詞w,隨機的賦予一個topic編號z。
(2)重新掃描語料庫,對每個詞w按照吉布斯取樣公式重新取樣它的topic,在語料中進行更新。
(3)重複以上語料庫的重新取樣過程知道吉布斯取樣收斂。
(4)統計語料庫的topic-word共現頻率矩陣,該矩陣就是LDA的模型。
在我們得到主題對詞的分佈後,也據此得到詞對主題的分佈。接下來,就可以通過這個分佈資訊計算文件與詞的相似性,繼而得到文件最相似的詞列表,最後就可以得到文件的關鍵詞。