
Drools 規則引擎----向領域驅動進步(一)
PS:文章還在寫,目前都是一些概念性質的,想要做拓展的程式猿請過幾天再看,Drools會一致做完的~~~
1. 工欲善其事,必先利其器
Drools提供基於eclipse的IDE(這是可選的),但其核心只需要Java 1.5(Java SE)。
1.1 GEF安裝
Open the Help→Software updates…→Available Software→Add Site… from the help menu.
Location is:
http://download.eclipse.org/tools/gef/updates/releases/PS:1.需要梯子 2.官方文件給的截圖與目前版本差距太大,所以建議全安了吧。。。。 3.挺慢的
2. 簡介
2.1 模組功能
Drools被分解成幾個模組,下面是組成JBoss Drools的重要庫的描述 :
| jar | 作用 |
|---|---|
| knowledge-api.jar | 這提供了介面和工廠。它還有助於清楚地顯示什麼是使用者API,什麼是引擎API |
| knowledge-internal-api.jar | 這提供了內部介面和工廠 |
| drools-core.jar | 他是核心引擎,執行時元件。包含RETE引擎和LEAPS引擎。如果您正在預編譯規則(並通過包或RuleBase物件進行部署),這是惟一的執行時依賴性。 |
| drools-compiler.jar | 它包含編譯器/構建器元件,以獲取規則源,並構建可執行的規則庫。這通常是應用程式的執行時依賴性,但如果您預先編譯了規則,則不必如此。這取決於drools-core。 |
| drools-jsr94.jar | 這是jsr- 4相容實現,這實質上是drools編譯器元件的一個層。注意,由於jsr-94規範的性質,並不是所有特性都很容易通過這個介面公開。在某些情況下,直接使用Drools API比較容易,但是在某些環境中,jsr-94是強制執行的。 |
| drools-decisiontables.jar | 這是決策表的編譯器元件,它使用drools編譯器元件。這支援excel和CSV輸入格式。 |
2.2 依賴檔案
Maven pom.xml檔案
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-bom</artifactId>
<type>pom</type>
<version>...</version>
<scope>import</scope>
</dependency>
...
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.kie</groupId>
<artifactId>kie-api</artifactId>
</dependency>
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-compiler</artifactId>
<scope>runtime</scope>
</dependency>
...
<dependencies>3.what?
3.1 規則執行生命週期
規則引擎優化了對條件的評估,並確保了我們可以以最快的方式確定命中的規則。然而, 除非我們指定,否則規則引擎不會在條件檢測時立即執行我們的業務規則 。當我們到達一個點時,我們發現一個規則對一組資料的評估是對的,那麼規則和觸發資料被新增到列表中。這是一個明確的規則生命週期的一部分,我們在規則評估與和規則執行之間有一個清晰的劃分。規則評估將會新增規則操作和觸發的資料到一個元件之中。我們稱這個元件是Agenda(議程)。規則執行是在命令中執行的。當我們通知規則引擎的時候,它應該會觸發我們議程上的所有的規則。
如前所述,我們不控制將要被命中的規則。而是根據我們建立的業務規則和我們為引擎提供的資料來確定這一點,但這其實是引擎的責任。但是,一旦引擎決定了應該命中的業務規則,我們可以控制它們執行命中的事件。這是通過對規則引擎的方法呼叫完成的。
一旦規則被觸發,每條規則將被執行。規則的執行可能會修改我們領域資料,然後這些更改如果引發了與新資料相匹配業務規則,新的規則將會被加入進Agenda(議程)中,或者如果這些修改導致匹配結果不再正確,那麼它將被取消。這個完整的迴圈將繼續下去,直到對於可用資料沒有更多的規則在議程中可用或規則引擎執行被迫停止。下面的圖 顯示該工作流是如何執行的:
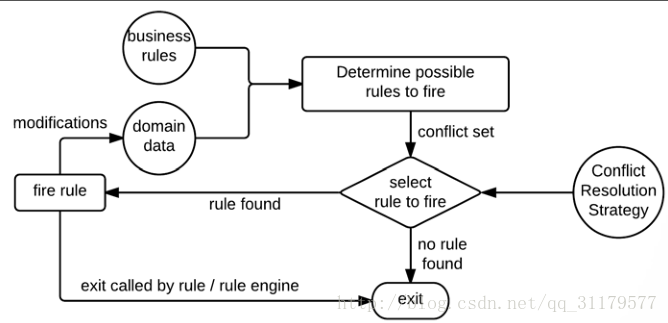
這個執行生命週期將繼續執行規則引擎根據決定根據規則的定義和域資料所決定的新增到議程中的所有的所有規則。有些規則可能不會觸發,有些規則可能會多次觸發。
3.2 why?
對於我們的業務規則的匹配而言。以傳統的命令式編碼(即我們java程式碼條件判斷等),如果業務規則發生了變化,我們需要重新從頭縷邏輯,然後在合適的地方新增/刪除、修改我們的條件判斷。這帶來就是業務邏輯的捆綁以及不可預知的Bug。而Drools提倡的是宣告式程式設計,我們只需要像做流水線一樣,單獨做自己的業務規則即可,每個業務規則均是獨立的,類似的,可以想象為if/else if/else變為了插拔式的多個if判斷。
3.3 how?
以領域驅動角度來談我們的領域層,其實最神祕的是業務邏輯與規則。比如移動的積分制度,保險的保金等等,他們都是與行業有關的知識。作為一個技術精湛的我們,也無法充分想到這些業務規則的邊邊角角。但是領域專家知道這些業務規則,可惜他們不會程式設計。
SO.BRMS(業務規則管理系統)就是以友好的方式,來使得領域專家書寫規則。
4. 規則引擎的演算法、
tell me:業務規則是如何執行的
規則引擎通過特定的演算法將我們定義的業務規則轉換為可執行決策樹。執行樹的效能 將取決於演算法生成的優化機制。是Drools6框架定義了自己的演算法,專注於更高的效能。這個演算法被稱為PHREAK,由Mark Proctor建立。它是基於一種叫做RETE的預先存在的演算法的一系列優化和重新設計的。作為開放原始碼實現,PHREAK是最高效、最有效的演算法之一。
在生成的執行樹中,規則中的每個條件都將被轉換為樹中的一個節點,以及再我們的規則中,不同的條件如何相互連線,將決定這些節點的連線方式。當我們在規則引擎中新增資料時 ,它將被批量評估,通過網路使用最優化的路徑。當資料到達代表了被觸發的規則的葉子時,執行樹完成。這些規則被新增到一個列表中,呼叫一個命令將會被要求觸發所有的規則或一組規則。
每次我們向規則引擎新增更多資料時,它都是通過執行樹的根元素引入的。執行樹的每一個優化都是根據 以下兩個主要焦點:
1.它會試圖將所有的條件分解為最小的單位 要儘可能多地重用執行樹
2.它將嘗試只進行一個操作,以達到下一個級別,直到它得到了一個false的條件評估或者執行到了頁節點上,在一個被標記為執行的規則上。
每一個數據都以可能的最有效的方式進行評估。這些評估的優化是規則引擎的主要關注點
4.1 什麼時候使用規則
什麼樣的專案適合將DFrools加入到技術站中??
1.他們定義了一個非常複雜的場景,甚至對於業務專家都很難完全定義
2.他們沒有已知的或定義明確的演算法解決方案
3.他們有揮發性的要求和需要經常更新
4.他們需要快速做出決定,通常是基於部分資料
其實你會發現,除了已經基本定型收工的專案,我們都可以將Drools加入技術棧
4.2 複雜的場景,簡單的規則
每隔一段那時間,我們會發現系統-或者是系統的一部分-元件間的小關係 開始變得越來越多,越來越重要。起先,他們可能看起來是無害的元件,只是依據兩三個資料來源來做一些業務判定。但是當以後我們再看它的時候,這些關係變得複雜了,而且也很重要。最終,我們可能 發現各部分之間的關係產生了更多的集體行為,甚至業務專家沒有意識到可能發生的事情;然而,這仍然是有意義的。這些系統被稱為複雜系統,它們是商業規則提供巨大幫助的地方之一。
複雜的場景通常由小的語句來定義。這個完整圖,涉及到完全定義場景所需的每一個組合、聚合或抽象,通常是超出我們最初的理解。因此,這類系統開始通過部分解釋來定義是很常見的。系統中的每個小關係都被定義為不同的 要求。當我們分析這些要求的每一個,把它們分開 在最基本的元素中,我們發現自己定義了業務規則。
每個業務規則有助於定義複雜場景中的每一個小元件。隨著越來越多的規則被新增到系統中,越來越多的這些關係可以以一種簡單的方式來處理。沒一個規則都變為了系統在執行復雜場景時需要執行的每一個小的決策服務的自解釋的手冊。
複雜應用程式的例子可以非常多種多樣,如下所示:
Fraud detection systems欺詐檢測系統
為客戶定製零售優惠券:
信用評分的軟體
4.3 不斷變化的場景
參與做出一個特定的決定的要素往往會發生頻繁的變化,業務規則對於管理系統行為的這種波動,可以是一個很好的解決方案。
業務規則在規則引擎中表示為資料樹。同樣地,我們可以修改列表的元素,我們可以從業務規則裡移除或者新加業務規則。這可以實現不重啟專案和重新發布部署任何元件。Drools內部機制可以自動的更新規則。Drools 6提供的工具也準備為業務規則提供來自使用者友好編輯器的更新機制。Drools 6 API的完整架構是基於儘可能的自適應的。
如果我們發現一個系統,需求可能經常發生變化,即使是在每天或每小時的頻率,業務規則可能是最適合這些需求的,由於它的更新能力,而不管系統的複雜性。
4.4 網上商店example
首先,我們將定義我們的eShop系統的模型。該模型將包含所有與我們的申請有關的決策。 其中一些物件如下所示:
| Domain | 業務知識 |
|---|---|
| Product | 我們店裡想要出售不同種類的專案.每種型別都將由一個產品物件來表示,其中包含特定專案的詳細資訊。 |
| Stock | 這是我們儲存的每一種產品的數量。 |
| Provider | 我們的產品來自不同的供應商。每一個供應商以特定的交付能力,為eShop提供特定種類的產品。 |
| Provider Request | 當我們的運行了一段時間,某些商品已經過時或者昆村不夠時候,我們需要建立請求,來讓為提供商填充我們的庫存 |
| Client | 當客戶在我們的eShop中喜歡一個或多個產品時,他們可以訂購併支付他們。訂單有不同的狀態,取決於是否客戶成功地收到了它。他們也有關於具體產品它的資訊及其數量。 |
| Discount | 網店提供不同的折扣,取決於購買的型別 |
| Sales channel | 我們將模擬的eShop可以使用多個網站,每個站點都被視為不同的銷售渠道。每個銷售渠道將有它自己的特定目標受眾,這是由使用它的客戶決定的 |
在專案中,我們需要做到的是:
1.將產品與每個銷售渠道相關聯並將其與其他銷售渠道進行比較,來為特定種類的產品定義最佳銷售渠道。依託於這些資訊,我們可以為不同渠道的穿品建立自定義的折扣
2.定義特定產品的客戶機首選項。依託於這些資訊,我們可以為他們提供適合他們特定口味的折扣票。
3.確定特定產品的平均消費,並與我們的庫存進行比較。一旦需要的話,我們可以自動的觸發供應商請求來發貨。
4.根據我們對具體供應商的訂單數量,我們可以去爭取一個價格的折扣
5.我們可以分析客戶在eShops中所購買的不同商品。 如果,在某個時候,購買超出了我們認為的正常範圍,我們可以 採取一系列行動,從一個簡單的警告,到為特定的購買提供直接的人類支援。
4.5 if not
1.在這個專案中,很少有獨立的規則:如果在需求收集中確定的業務規則非常簡單,並且最多可以跨越一個或兩個物件,我們不需要一個規則引擎來執行他們
2.業務邏輯不會經常改變:
3.對於應用程式來說,非常嚴格的執行流控制至關重要:當我們執行業務規則的時候,沒有提供一個序列流控制。如果業務規則背後的業務邏輯有很大的依賴關係,對於業務規則需要按順序執行的嚴格步驟, 那麼規則引擎可能不合適。然而,如果它經常發生變化,可能是商業過程是值得考慮的。
下一節講書寫和執行規則
5. 環境配置
1.jdk 1.8
2.maven 3.1 above
3.Git 1.9 above
5.1 建立第一個Drools專案
1.地址:
git clone https://bitbucket.org/drools-6-developer-guide/drools6-dev-guide.git2.Eclipse匯入專案二,不會的話,請關掉電腦,該幹嘛幹嘛去。。
3.首先看pom檔案,
<dependencies>
<dependency>
<groupId>org.kie</groupId>
<artifactId>kie-api</artifactId>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-compiler</artifactId>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-core</artifactId>
<type>jar</type>
</dependency>
//上面的jar功能在第二節裡都講了~~
//為了開始編寫我們自己域的規則,我們還需要新增一個依賴。下面這個依賴定義了由該域模型提供的域模型,這個在上一節我們也講過:
<dependency>
<groupId>org.drools.devguide</groupId>
<artifactId>model</artifactId>
<type>jar</type>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
</dependencies> 4./src/main/resources/META-INF/kmodule.xml
這個檔案將被用於配置如何載入規則引擎中專案中定義的規則。就目前而言, kmodule.xml的內容將非常簡單,因為我們將使用所有的預設值配置。下節我們會講解如果配置這個檔案
5.專案的阻止結果已經確定了,我們現在來書寫和執行我們的第一個規則。
①在src/main/resources檔案下建立文字,這個檔案可不是text檔案,檔案拓展名以.drl標識。這樣它就可以被當作一個規則檔案
②檔案的擡頭與java檔案相似,分別是package和import
package myfirstproject.rules
import org.drools.devguide.eshop.model.Item;
import org.drools.devguide.eshop.model.Item.Category;
rule "Classify Item - Low Range"
when
$i: Item(cost < 200)
then
$i.setCategory(Category.LOW_RANGE);
end這條規則檢查每一項成本低於200美元並自動以一個類別標記這個專案 。在這種情況下, 是將其標識以LOW_RANGE類別。對於我們的商店來說,區分不同種類的商品是有意義的,這樣我們就可以為他們應用不同的折扣和營銷策略。這個分類過程可以自動地使用規則來完成,這些規則集中了我們對LOW_RANGE、MID_RANGE或HIGH_RANGE專案的業務定義的點。
一般來說,這些檔案的結構如下:
package定義
import
(可選的)宣告的型別和事件
Rules: (1..N)/Queries (1..N)
③執行測試
public static void main( String[] args )
{
System.out.println( "Bootstrapping the Rule Engine ..." );
// Bootstrapping a Rule Engine Session
KieServices ks = KieServices.Factory.get();
KieContainer kContainer = ks.getKieClasspathContainer();
KieSession kSession = kContainer.newKieSession();
Item item = new Item("A", 123.0,234.0);
System.out.println( "Item Category: " + item.getCategory());
kSession.insert(item);
int fired = kSession.fireAllRules();
System.out.println( "Number of Rules executed = " + fired );
System.out.println( "Item Category: " + item.getCategory());
}正如您在前面的示例中看到的,有三個主要階段,如下所示以下幾點:
- 引導規則引擎會話: KieServices /KieContainer /KieSession的職責,我們會在下一節裡講。現在,我們只需要知道KieSession代表了一個具有指定配置和一系列規則的規則引擎的執行時例項。它掌握了與我們域物件的規則相匹配的評估演算法
- 讓規則引擎知道我們的資料:我們負責把所有的資訊都提供給引擎,這樣它就可以操作。為了做到這一點,我們在KieSession上使用了insert()方法。我們也可以使用delete()從規則引擎上下文刪除資訊方法或使用modify()方法更新資訊。
- 如果我們提供的資訊與一個或多個定義的規則相匹配,我們就就會得到匹配結果。呼叫fireAllRules()方法將執行這些匹配操作。在下一節,Drools執行時,我們將學習更多的匹配。
5.2 使用CDI引導規則引擎
Contexs and Dependency Injection (CDI) (網站 http://www.cdi-spec.org),是一組標準化的api,用於為我們的應用程式提供這些特性,因為它允許我們選擇我們所要的上下文和依賴注入容器。CDI現在已經成為Java SE規範的一部分,它的應用正在每年增長。由於這個原因,由於Drools專案增加了很多支援 CDI環境,本節簡要介紹如何簡化我們的Hello World 我們在上一節中所寫的例子。
為了在我們的專案中使用CDI,我們需要在我們的專案中新增一些依賴項 專案,如下:
<dependencies>
....上述的jar,不列舉了.....
<dependency>
<groupId>javax.enterprise</groupId>
<artifactId>cdi-api</artifactId>
</dependency>
<dependency>
<groupId>org.jboss.weld.se</groupId>
<artifactId>weld-se-core</artifactId>
</dependency>
</dependencies>javax.enterprise:cdi-api包含CDI規範中定義的所有介面
org.jboss.weld.se:weld-se-core包含我們將使用實現CDI介面的工具
通過添加了這兩個jar,我們可以在專案中使用@Inject註解,來注入KieSession,Weld容器將負責為我們提供規則引擎。
CDI的工作原理基於約定優於配置,它引入了新增新檔案的需要,檔案放在 src/main/resources/META-INF下的bean.xml檔案,用於配置容器如何在專案和其他配置中訪問我們的bean。請注意與我們之前介紹過的檔案kmodule. xml的相似性 。這是一個空的beans.xml的示例內容檔案,CDI容器使用該檔案瞭解需要解析的jar 將容器提供給@inject注入的bean,如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/beans_1_0.xsd">
</beans>一旦我們有了容器的依賴項和beans.xml檔案,容器可以掃描類路徑(即我們的專案及其依賴項) 尋找要注入的bean,我們可以在應用程式中使用這些特性。
下面的類表示建立預設KieSession的同一個簡單示例,然後與它互動。
下面的程式碼片段通過CDI初始化KieSession並與它互動, 如下:
public class App
{
@Inject
@KSession("") // This is not working track: https://issues.jboss.org/browse/DROOLS-755
// it should be @KSession() for the default session
KieSession kSession;
public void go(PrintStream out){
Item item = new Item("A", 123.0,234.0);
out.println( "Item Category: " + item.getCategory());
kSession.insert(item);
int fired = kSession.fireAllRules();
out.println( "Number of Rules executed = " + fired );
out.println( "Item Category: " + item.getCategory());
}
public static void main( String[] args )
{
Weld w = new Weld();
WeldContainer wc = w.initialize();
App bean = wc.instance().select(App.class).get();
bean.go(System.out);
w.shutdown();
}
}注意,main(…)方法現在正在引導Weld容器,由於這個原因,我們的bean(App)可以注入任何bean。在本例中,@ksession註釋負責引導引擎併為其建立一個新的例項 提供給我們使用。我們將看第3章中CDI擴充套件所提供的註解。
將此視為與Drools規則引擎互動的另一個非常有效的選項。 如果您正在使用一個Java EE容器,比如WildFly AS(http://www.wildfly.org/),它是建立在純粹基於CDI的核心之上的,那麼這種方式使可以使用的。
在本例中,我們使用WELD,他是CDI的參考實現。注意,您可以使用任何其他CDI實現,例如在 http://openwebbeans.apache.org中開啟Apache Open Web Beans。
現在,為了瞭解規則是如何被應用和執行的,我們應該清楚地理解我們用來寫規則的語言,我們稱呼它叫做Drools規則語言(DRL)。下面的部分將從不同角度更詳細的介紹語言。下一節將更詳細地介紹執行方面,當我們引導規則引擎會話時,以及如何為不同的目的配置它時,解釋了正在發生的事情。
5.3 規則語言
PS:參考專案為chapter-02-kjar
正如之前所屬的,規則是由條件和結果組成的
rule "name"
when
(Condition條件)--通常也叫做左手邊的規則(LHS)
then
(Actions/Consequence)--通常也叫做右手邊的規則(RHS)
end規則的LHS–條件,是根據DRL語言來編寫的(檔名都是.drl結尾。。。),為了簡單起見不會完全解釋。我們會在樣例裡看到最常用的一些DRL語言結構,我們會盡可能多地使用語言。你可以通過下面的地址來學習完整詳細的語言結構:
https://docs.jboss.org/drools/release/7.1.0.Final/drools-docs/html_single/index.html#DroolsLanguageReferenceChapter規則的LHS由條件元素組成,它們充當過濾器,定義規則來評估真正的滿足的條件。這個條件元素過濾事實(即insert方法傳入的物件資料),在我們的例子中是我們在Java中工作的物件例項。
如果你看我們第一條規則的LHS,那個條件表示式非常簡單,如下:
rule "Classify Item - Low Range"
when
$i: Item(cost < 200)
then
$i.setCategory(Category.LOW_RANGE);
endLHS可以劃分為三部分:
- Item(…)是為Item型別的物件的過濾器。這個過濾器會拿起所有我們以insert方法進session中的item物件用於進行處理。
- cost<200這個過濾器將會看一看每個item物件,確保cost屬性有一個值且小於200
- 符號來命名變數,這樣我們就能很容易地與物件欄位對比中識別出它們。這是好的做法。
綜上所述,我們基於物件及其屬性進行過濾。重要的是要理解,我們將過濾與這些條件匹配的物件例項。對於每一個對所有條件求真值的專案例項,規則引擎將建立一個匹配結果。
更復雜的規則可能是根據他們的訂單的大小來對我們的客戶進行分類。新規則和前一條規則有很大區別,現在的規則將需要評估訂單和客戶。看一下規則是:
rule "Classify Customer by order size"
when
$o: Order( orderLines.size >= 5, $customer: customer ) and
$c: Customer(this == $customer, category == Customer.Category.NA)
then
modify($c){
setCategory(Customer.Category.SILVER)
};
end 在這個規則裡,我們正在對訂單數量超過5條的訂單進行評估,即表示五個不同的物品。然後,我們查詢與這個訂單管理關聯的消費者,並設定這個消費者的類別。消費者和訂單之間的關係是通過將訂單物件中的客戶引用繫結到一個叫做customer…).條件元素的順序只由我們需要的繫結定義.在這種情況下,我們將Order.getCustomer()拿來去匹配消費者。但是,我們也可以用另一種方法來做,它會以同樣的方式工作,如下所示:
$c:Customer(category == Customer.Category.NA)
$o:Order(orderLines.size >= 5,customer == $c)在這個端點上我們需要理解的是Customer(…條件)過濾器和Order(…條件)過濾器需要是事實,換句話說,他們需要去顯式的以insert方法a插入進KieSession中.儘管Order.getcustomer()不是事實,但是它是事實中的物件。
這個規則要想評估為true,我們需要一個Order和一個Customer物件來使得所有的條件為真。在Customer(…條件)過濾器和Order(…條件)之間,有一個隱式的AND,因此,這個LHS可以這樣解讀:這裡有一個超過20條記錄的訂單,AND,一個消費者與這個訂單相關聯。
那麼,現在我們再來看RHS,即modify(