
Drools 規則引擎----向領域驅動進步(四)
阿新 • • 發佈:2019-01-03
1.複雜事件處理
到目前為止,我們已經看到如何使用規則,以基於資料(我們稱呼它為fact)來做出決定。這個資訊幾乎是任何一組Java物件,它們描述了我們正在做決策的域的狀態,但是它總是在一個特定的時間點上代表這個世界的狀態。本章我們將會去看一些列的概念,配置和規則語法元件,他們可以允許你基於事實資料之間的時間關係做出決定。這個概念也被稱為complex event processing(CEP) Drools以Drools Fusion或Drools CEP的名義提供支援, 一個概念模組完全整合到Drools的核心特性中。這只是概念上的分離,因為所有CEP特性都由提供規則引擎功能的相同模組完全支援。為了完全理解這一點,本章將涵蓋以下主題: >討論與複雜事件處理相關的不同概念,包括滑動視窗、入口點和時間操作 >將複雜的事件處理裝配為一種稱為事件驅動架構的特殊架構 >編寫規則並配置執行時以充分利用Drools CEP特性
1.1 什麼是複雜事件處理
CEP的主要關注點是在不斷變化的、不斷增長的資料雲中,將基於時間的資料關聯起來,以便發現難以發現的特殊情況,併為這些情況做些事情。為了充分理解它的工作原理,我們首先需要定義一些其他的概念。讓我們從定義事件開始。
1.1.1 什麼是事件和複雜事件??
為了瞭解事件,讓我們先談一個熟悉的概念。到目前為止,我們已經討論了插入到一個Kie session中的事實資料以及它們如何匹配一個特定的規則。事實資料與事件非常相似,除了事件有一個額外的特徵:發生的時間。事件僅僅是關於任何域(表示為Java物件)的資料,以及關於該資訊是真實的時間的資訊。 在特定的時間裡,我們記錄的任何事情都可以是一個事件,如下: >我們的eShop限時折扣 >電話呼叫有一個開始時間和一個結束事件 >任何一種感測器讀數都會告訴你它的特定讀數(溫度、溼度和運動)與特定時刻的關係 事件本身是事件處理的基本結構。我們從外界獲得的每一個輸入都可以被看作是一個事件。然而,我們將主要關注於檢測複雜事件。 一個複雜事件就是一個簡單的聚合,組合,或者其他事件的抽象。複雜事件處理的真正威力來自於能夠將簡單的傳入事件關聯起來,這樣我們就可以檢測複雜的情況,而這些情況是無法由任何裝置或個人直接檢測到的,如下所示: >我們在某一特定時刻所擁有的所有事務都可以被關聯起來,以檢測任何可能的欺詐行為(並採取先發制人的措施)。 >在呼叫中心,根據特定區域分組的所有傳入呼叫,可以確定這些區域的服務中斷情況,從而自動通知使用者。 即使是感測器讀數,在很大程度上,也可以通過簡單的事件組合來檢測複雜的情況。讓我們考慮一組感測器讀數,作為我們的輸入事件。一組地震事件可以告訴我們這座城市發生了什麼地震以及它的強度。一組火警警報可以告訴我們在城市裡哪裡有火災。 在發生大地震的情況下,結合城市基礎設施的資訊,我們可以推斷出可能發生的結構性崩潰,並派專家來評估當前的形勢。如果我們有火警警報,我們就可以派消防隊去滅火。 如果我們發現一組小地震,一個接一個,在一秒內,在同一個方向上,我們可以推斷出一個很大的大地震正朝著這個方向移動.如果我們也探測到火災,一個接一個地在同一個方向上,我們可能會把所有的地震和火災警報事件集合成一個複雜的事件,也許哥斯拉正在朝這個方向移動,如下圖所示:
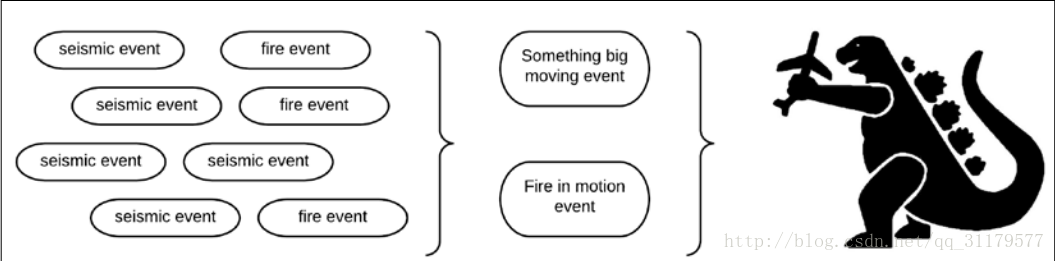
如果是這樣的話,我們可能就不希望把架構師和消防隊送到那個大方向(他們很可能會被吃掉)。相反,我們可能採取不同的行動,比如派遣軍隊。正如您所看到的,非常小的簡單事件可以使我們能夠從這些事件中推斷出更多的資訊。這是複雜事件處理的主要功能。
1.2 闡述基於CEP的規則
在此之前,我們已經討論了規則應該如何嘗試變為原子性,並一起工作以實現複雜場景的管理。這與CEP很好地結合在一起,因為每個不同的規則都可以處理聚合、組合或其他事件的抽象的一個方面。他們可以一起工作來實現非常複雜的事件的實時解決方案。我們仍然需要一些Drools的附加功能來做到這一點,如下: >如何指導Drools一個物件被視為一個事件 >如何及時的比較兩個事件的 在下一小節中,我們將看到如何使用DRL語法實現此目的。
1.2.1 事件的語義
在我們詳細討論如何定義一個事件之前,我們㤇理解事件的一些特點。第一個特徵是兩種主要型別的事件——準時和間隔事件之間的區別——如下所示:
>Punctual events(準時事件):它們是在某個特定例項中發生的事件。它們可能代表了我們的領域模型出現了變化的確切時刻,或者它們的生命週期太短而不能被考慮。準時事件的一個例子是感測器讀數,它會將感測器的特定值與讀數的特定時間相關聯。如果時間太短,事務也可以被認為是準時的事件,我們可以忽略它們的持續時間。
>間隔事件:它們是有兩個獨特時刻的事件:一是開始的時刻,二是結束的時刻。這使得間隔事件比準時事件要複雜一些;如果你有兩個準時的事件,你只能比較它們是在同一時間,還是在之前,還是在彼此之後發生的。另一方面,對於間隔事件,您可以比較一個事件在另一個事件中開始和結束的情況,只是為了命名一個場景。
另外,無論什麼是準時或間隔事件,它們都有一組概念特徵,在我們檢視程式碼之前,它們都是值得提及的。
>他們通常是不可變的:事件應該是我們的領域模型在某個特定時刻的狀態的記錄。你不能改變過去,因此,你不應該改變你的事件資訊。引擎沒有強制這個功能,但是在設計我們的活動時,它是要記住的。它們可能通過向它們新增額外的資訊來修飾,但是您不需要修改它們在Kie session中插入的內部資料。
>他們有被管理的生命週期:由於引擎將所有事件都理解為具有時間關係的物件,因此Kie session可以根據其定義的規則確定事件何時不再觸發規則,並可以從會話中自動刪除它。
1.2.2 闡述Drools的time-based-events
為了建立CEP規則,我們需要做的第一件事是指定需要將物件作為事件處理的物件的型別.也就是說,物件應該有時間元資料。這將允許Kie session對這些型別應用時間推理。有幾種方法可以用來定義特定的型別應該作為事件處理看待,但是它們都定義了相同的元資料集。要定義的屬性如下所示:
>型別的角色:這是唯一的強制元資料,用於定義一個事件的型別。它將有兩個特定型別:事實和事件
>時間戳:這是定義型別屬性的可選屬性,它將定義事件發生的時刻。如果不存在,則每個事件例項的時間戳將是插入到Kie session中的時間。
>持續時間Duration:這是一個可選屬性,用於定義指定事件持續時間的型別的屬性。如果不賦值,該活動將被視為一個準時的活動。這個屬性對於間隔事件是必需的。
>到期Expires:這是一個可選的字串,以確定在自動刪除之前,這個型別的事件應該在多長時間內出現。
現在我們瞭解了這些屬性,讓我們看看將它們應用到我們的型別的不同方法。該元資料可以直接定義為Java bean中的類級註解,如下:
@org.kie.api.definition.type.Role(Role.Type.EVENT)
@org.kie.api.definition.type.Duration("durationAttr")
@org.kie.api.definition.type.Timestamp("executionTime")
@org.kie.api.definition.type.Expires("2h30m")
public class TransactionEvent implements Serializable {
private Date executionTime;
private Long durationAttr;
/* class content skipped */
}正如您在前面的程式碼部分中看到的,我們可以為事件型別的角色、持續時間、時間戳和過期屬性定義註釋。Duration持續事件屬性應該確定一個Long型別的屬性,時間戳則是確定一個Date型別的屬性。通過這種方式,Kie session將能將插入的上述所指定的物件,看做是一個事件。
定義這些屬性的另一種方法是宣告型別。類似的註釋可用於將宣告型別定義為事件,如下:
declare PhoneCallEvent
@role(event)
@timsstamp(whenDidWeReceiveTheCall)
@expires(2h30m)
whenDidWeReceiveTheCall:LOng
callInfo:String
end
上述的程式碼段展示了我們如果建立我們的宣告型別,並且對他進行註解,使其成為一個事件。
宣告事件的另一種方法是獲取一個已存在的類,並將其宣告為DRL中的一個事件。當在不同的系統之間我們需要建立事件去共享,但是我們不能直接修改這些類,使其具有這些事件註解。這時候我們可以像下面程式碼這樣,宣告一個已經存在的java類為一個事件:
import path.to.my.shared.ExternalEvent;
...
declare ExternalEvent
@role(event)
end就像上面程式碼展示的,我們可以在DRL檔案內,重新宣告沒有被註解的java類,使其成為一個事件。正如上文所言,所有的這些註解都是可選的。將一個類宣告為一個事件所必須的註解就是@role(event)註解,你可以參考chapter-06/chapter-06-events專案的程式碼樣例。
現在我們已經瞭解瞭如何宣告事件型別,我們需要開始檢視如何比較它們。為了實現這一操作,我們將回顧現有的時間運算子。
1.2.3 運算子
一旦我們定義了我們自己的事件型別,我們需要一種能夠方式來基於這些事件的時間戳進行比較。為了這樣,我們可以在Drools裡使用13運算子。有的運算子只對比較區間事件有意義,但是給予兩個事件,他們可以將它們與以下程式碼片段進行比較:
declare MyEvent
@role(event)
@timestamp(executionTime)
End
rule "my first time operators example"
when
$e1: MyEvent()
$e2: MyEvent(this after[5m] $e1)
Then
System.out.println("We have two events" +
" 5 minutes apart");
end在上面的樣例中,我們使用了after操作符,來決定一個事件是否至少比以往的某一個事件新5分鐘以上。正如你所見,比較是在特定的事件例項上進行的。在內部,時間比較會發生在被稱為executionTime的時間戳屬性上,但是在處理事件時我們可以忽略這個事實。如果我們需要修改事件型別的時間戳特性,這就提供了一個優勢,因為我們不需要改變使用它的CEP規則。
此外,我們還可以注意到在運算子中使用引數,在方括號內傳遞。每個時間操作符將準備接收0到4個引數,以更具體的方式使用操作符。在前面的場景中,我們傳遞了一個5m引數,以指定一個事件應該在另一個事件發生後至少5分鐘。
有很多我們可以工作的時間運算子。以下是他們的一份清單和他們的意思:
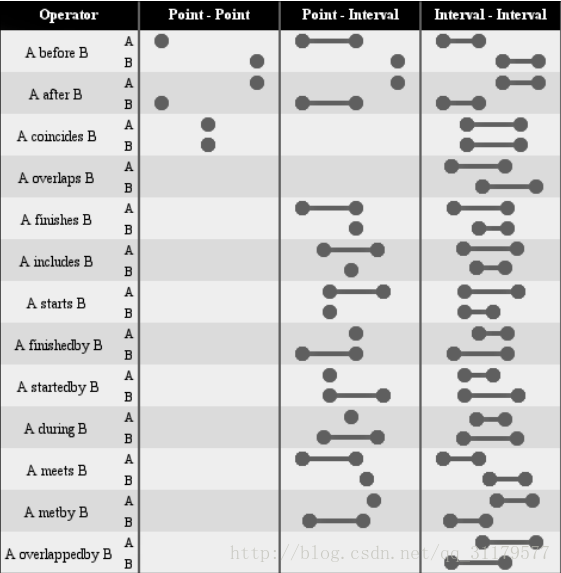
前面的圖顯示了不同的時間操作符,以及它們如何在不同的事件之間進行比較。他們都有某些特質,如下所示:
>他們都是操作兩個事件。這些操作符都準備著與另一個事件進行比較。
>它們還可以用來比較Date物件,根據定義,它是事件的最簡化的表示形式(只有時間資訊,而不需要額外的資料)。
>它們可以接收引數來指定它們的內部工作。這些引數的操作在https://docs.jboss.org/drools/release/latest/drools-docs/html/的Temporal Operators主題得到了充分的解釋。
關於事件值得一提的一點是,它們仍然是事實資料。引擎將把時間特性新增到事件型別,但是我們仍然可以比較它們的內部屬性和方法來建立規則的條件和約束,就像我們在前幾章中所做的那樣。為了熟悉CEP規則,讓我們分析一下我們在chapter-06/chapter-06-rules程式碼包中可以找到的一個規則,它的目的是檢測欺詐行為,如下:
rule "More than 10 transactions in an hour from one client"
when
$t1: TransactionEvent($cId: customerId)
Number(intValue >= 10) from accumulate(
$t2: TransactionEvent(this != $t1,
customerId == $cId, this meets[1h] $t1),
count($t2) )
not (SuspiciousCustomerEvent(customerId == $cId,
reason == "Many transactions"))
then
insert(new SuspiciousCustomerEvent($cId,
"Many transactions"));
end這個例子DRL檔案可以子在 chapter-06-rules/src/main/resources/chapter06/cep/cep-rules.drl裡找到。為了執行這個例子,我們從前面定義的TransactionEvent事件型別開始。在我們的規則中,我們將檢查兩件主要的事情:一個小時內是否有10個來自同一客戶的事務,並且我們仍然沒有一個複雜的事件來反映這種情況。
第一個條件寫在一個accumulate累積中。我們計算包含相同客戶ID的TransactionEvent物件的數量,並且使用 this meets [1h] $t1來檢查是否發生在原始參考交易的一個小時內。
這條規則的結果並不是針對外部的特別行動。相反,我們只是發現了一個複雜的事件,叫做SuspiciousCustomerEvent(是我們樣例中所宣告的一個型別)。這將表示交易事件的聚合。
第二段條件是一個簡單的not字句,我們只是通過SuspiciousCustomerEvent物件來檢查我們還沒有為特定的客戶啟動這條規則,如果還沒有新增的話,我們需要在結果中新增。
這個規則只會檢測到這種情況,因為這是我們可以將其分解為最小的責任。我們可以對可疑的客戶做很多事情,但是這條規則只負責理解一個特定的情況,即客戶行為可疑。我們需要記住始終保持我們的規則儘可能的原子化。其他規則可能通過其他方法檢測客戶的可疑活動。
一旦檢測到可疑的客戶,另一條規則可以在檢測到一些可疑的客戶事件時決定要做什麼。對於這種情況,我們將建立一個不同的規則:
rule "More than 3 suspicious cases in the day and we warn the owner"
when
SuspiciousCustomerEvent($cId: customerId)
not (AlarmTriggered(customerId == $cId))
Number(intValue >= 2) from accumulate(
$s: SuspiciousCustomerEvent(customerId == $cId),
count($s)
)
then
//warn the owner
System.out.println("WARNING: Suspicious fraud case. Client " + $cId);
insert(new AlarmTriggered($cId));
end如前所述,我們可以有多個規則來檢測可疑的客戶活動。當兩個或多個規則被相同的客戶觸發時,該規則將觸發.一旦發生這種情況,我們就向所有者發出警告。在這個例子裡,它被表示為一個簡單的系統輸出,但它也可以很容易地成為一個助手方法或全域性變數方法,用來發送電子郵件或SMS。
正如我們從前面的示例中可以看到的,我們可以將複雜的事件處理案例分解成多個規則,每個規則都通過它所消耗或產生的事件連線到CEP場景的其餘部分。這些事件的聚合為我們的系統提供了一種特殊的體系結構,事件及其與隔離的應用程式元件之間的關係使我們能夠建立非常分離的、高度可擴充套件的元件。這個體系結構稱為事件驅動體系結構,我們將在下一小節中描述它。
1.3 事件驅動架構
事件驅動的體系結構是一種非常容易與CEP結合的概念,因為它定義了一個簡單的體系結構來促進生產、檢測、消費和對事件的反應。此體系結構的概念是將應用程式元件作為四個可能的元素之一,相關的內容如下圖所示:
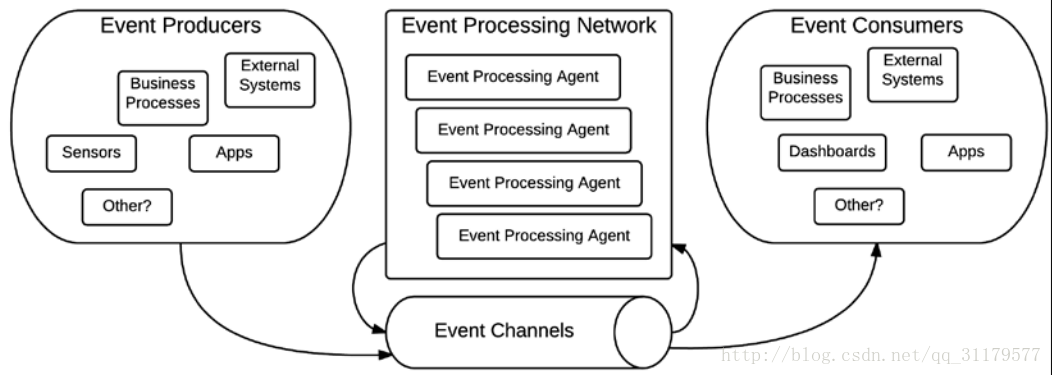
事件驅動架構(EDA)的概念是將以下四個不同類別的元件分類:
| 元件分類 | 描述 |
|---|---|
| Event Producer | 他們在EDA中的作用完全是為了創造事件,所有能產生事件的東西都被認為是生產者,無論它是基於硬體的感測器、應用程式收集請求、業務流程,或者任何其他形式的應用程式,可以將一個新事件引入到我們的體系結構中。 |
| Event Consumer | 他們在EDA中的角色是傾聽其他元件產生的事件。它們還可以從各種各樣的元件,從應用程式的簡單監聽器到複雜的儀表板。它們通常表示該體系結構的最終輸出,並將生成的值指向外部世界。 |
| Event Channels | 它們是所有其他元件之間的通訊協議。事件通道封裝了用於將事件從一個元件傳輸到另一個元件,從一個傳輸感測器讀數的武力電線傳輸到邏輯元件的任何元件,例如一個Java訊息服務佇列。 |
| Event Processing Agents | 這些是組織事件來檢測和處理複雜事件的核心元件。在Drools裡,處理CEP的每一條規則都被認為是事件處理代理。對更復雜的情況進行檢測和反應的分組稱為事件處理網路。 |
在設計一個圍繞複雜事件處理的系統時,這個體系結構是一個非常有用的概念。它可以很容易地整合到任何其他型別的體系結構中,因為它只關心事件如何與元件互連,從而為各種其他特性留出空間。
大多數開始使用CEP的應用程式需要考慮,在設計階段,有一個概念類似於EDA提出的一個概念,即多個事件生產者連線到一個事件處理代理(即我們的規則)的網路,並將資料生成給多個事件使用者。Drools通過稱為入口點的元件提供了源多元化的概念,我們將在下一小節中討論它。
1.3.1 將事件源與入口點分開
在Drools中提供入口點作為分割槽工作記憶體的一種方法。每一個Kie session可以有多個入口點,它可以用來確定傳入資料的來源。對於複雜的事件處理,入口點是為事件定義多個源的一個很好的方法。
為了將任何型別的物件插入到一個入口點,我們所需要做的就是使用以下的API:
KieSession ksession = …; //kie session initialization
ksession.getEntryPoint("some entry point").
insert(new Object());前面的程式碼部分只有在我們在DRL檔案中宣告一個入口點時才會起作用;否則,它將丟擲一個異常。宣告和使用入口點可以直接在任何規則中發生。它們可以在規則的條件或結果中使用,如下面的例子所示:
rule "Routing transactions from small resellers"
when
t: TransactionEvent() from
entry-point "small resellers"
then
entryPoints["Stream Y"].insert(t);
end在前面的規則,我們過濾從 small resellers這個入口點傳入的TransactionEvent物件。然後,在結果中,我們將把每一個匹配事件插入到另一個叫做Stream Y的入口點。正如您可以看到的,我們可以建立儘可能多的入口點來分割我們資訊的來源。
插入一個入口點的事件永遠不會失去對它的引用。這意味著,Kie session將把不同的入口點作為完全不同的事件組對待。在您的規則中,您需要指定您想要過濾資料的入口點,以及您想要修改資料的入口點。但是,您可以在一個規則中交叉引用來自多個入口點的資訊,也可以在入口點和常規工作記憶體之間交叉引用。
您可以在CEPEntryPointsTest類上看到一個在不同入口點工作的規則示例。它在 chapter-06-tests專案下。在這個例子裡,我們使用兩個入口點去將傳入的事務分為“big client”和“small client”.每個人都會有不同數量的交易他們會認為是可疑的,因此,每個人用不同的規則來處理這個案例.
1.3.2 滑動視窗
Drools CEP特性的另一個非常有用的概念是使用滑動視窗。因為事件有一個時間戳,它們也有一個固有的順序。我們可以通過這個特殊的順序過濾來自工作記憶體或任何入口點的事件。我們有兩種滑動視窗,如下:
>Length-based滑動視窗
>Time-based滑動視窗
1.3.2.1 Length-based滑動視窗
最簡單的滑動視窗是基於長度的滑動視窗。您可以使用它來指定插入到流中的最後N個元素。每當將一個新事件新增到流中,視窗的最後一個元素就會被一個新的元素所取代。使用基於長度的滑動視窗是很容易的。下面的規則顯示了一個簡單的方法來宣告一個滑動視窗來從工作記憶體中獲取TransactionEvent型別的最後6個事件:
rule "last 6 transactions are more than 100 dollars"
when
Number(doubleValue > 100.00) from accumulate(
TransactionEvent($amount: totalAmount)
over window:length(6),
sum($amount)
)
then
//... TBD
end在前面的規則中,我們將彙總最後6個事務的所有金額,並在這個金額超過100美元的情況下觸發規則。為了得到最後的6個事務,我們使用一個滑動視窗。
如果在TransactionEvent型別的工作記憶體中有6個或更少的元素,那麼這個視窗將包含所有元素。當我們新增第七個TransactionEvent物件時,我們只會得到這個滑動視窗返回的最後6個物件。這就是為什麼它被稱為滑動視窗。您將只看到一個特定的事件組,每次您新增一個新事件時,視窗將會移動來檢視符合條件的最後一個元素。
1.3.2.2 Time-based滑動視窗
可以建立一個類似的視窗,它將返回從現在開始的特定時間內發生的任何元素。這是通過一個基於時間的滑動視窗完成的。讓我們來看看下面這個例子:
rule "obtain last five hours of operations"
when
$n: Number() from accumulate(
TransactionEvent($a: totalAmount)
over window:time(5h),sum($a)
)
Then
System.out.println("total = " + $n);
end在前面的示例中,我們會得到在從現在到過去5小時前之內的交易。如果一筆交易發生在5個小時1秒只前,它將不再活躍在這裡。在這段時間內,無論我們是有一個交易還是有500個交易,時間視窗將包含所有這些事務。
PS:請注意,這個視窗將隨著Kie session的內部時鐘而滑動,我們將在本章後面的《使用會話時鐘進行測試》這一部分中看到如何在測試中進行配置。
1.3.2.3 宣告滑動視窗
滑動視窗通常在使用它們的規則中定義。這是一個很常見的做法,因為它本來是使用滑動視窗的唯一方法。 然而,這就導致了需要從同一個視窗中過濾元素的規則,在每個規則中都必須重新定義它。如果我們這樣定義滑動視窗,並且以後需要改變我們使用的視窗的性質,例如 將一個基於長度的滑動視窗轉換為基於時間的滑動視窗,我們必將編輯所有使用它的規則。為了避免這樣做,Drools有一個特性 被稱為視窗宣告。
視窗宣告允許我們去定義一個視窗作為一個預建立元件,並通過名字,被任意數量的規則呼叫。這樣就允許我們在宣告視窗內進行改變,這個視窗僅僅在此處宣告一次,被多個規則之間共享。其語法如下:
declare window Beats
@doc("last 10 seconds heart beats")
HeartBeat() over window:time( 10s )
from entry-point "heart beat monitor"
end然後,規則可以通過引用這個名稱來使用宣告的視窗,如下面的例子所示:
rule "beats in the window"
when
accumulate(
HeartBeat() from window Beats,
$cnt : count(1)
)
then
// there has been $cnt beats over the last 10s
end如你所見,視窗宣告允許簡單的重用窗戶,甚至是為特定入口點宣告初始公共過濾器。這可以避免重寫許多規則,這些規則可能共享一個邏輯上相同的滑動視窗。
1.4 執行CEP-based場景
現在我們已經看到了CEP規則的主要元件,我們需要開始關注在Drools中成功執行CEP場景所需的一些配置步驟。執行CEP案例的KieBase和session都需要特殊的管理,我們將在下一小節中看到,如下所示:
>如何配置基基以支援複雜事件處理
>連續和離散規則執行的區別
>Kie session內部時鐘如何計算時間事件
1.4.1 流處理配置
為了建立CEP Drools執行環境,我們需要從預設的初始化中提供一些額外的配置。我們需要新增的第一個是我們將要使用的Kie base的事件處理模式。
事件處理模式將決定在執行時中插入的新資料的處理方式。預設的事件處理模式稱為CLOUD模式,基本上以相同的方式處理任何傳入的資料,而不考慮事件還是簡單的事實資料。這意味著運在行時將不去理解事件的概念,因此我們不能將其用於CEP。
我們需要配置我們的Kie base以使用STREAM事件處理模式。該配置將通知執行時,它應該管理事件,並根據時間戳將其內部排序。由於這一排序,我們能夠對事件執行時間操作,並在其中使用滑動視窗。有許多方法可以在Kie Base中配置STREAM事件處理模式。最簡單的方法是直接在kmodule.xml中作為kbase標籤的一個屬性來配置:
<kbase name="cepKbase" eventProcessingMode="stream"
packages="chapter06.cep">
<ksession name="cepKsession"/>
</kbase>通過這種方式,我們稍後可以直接從對應的Kie Container中使用Kie Base或Kie session,而其執行時的配置將使用流事件處理模式。我們可以看到這個配置的一個例子,位置在chapter-06/chapter-06-rules/src/main/resources/META-INF/kmodule.xml。
配置此事件處理模式的另一種方法是程式設計方式。這樣做的話,我們將會使用到 KieBaseConfiguration這個實體Bean以及他的setOption方法,如下:
KieServices ks = KieServices.Factory.get();
KieContainer kc = ks.getKieClasspathContainer();
KieBaseConfiguration kbconf = ks.newKieBaseConfiguration();
kbconf.setOption(EventProcessingOption.STREAM);
KieBase kbase = kc.newKieBase(kbconf, null);在上一個例子中,我們使用了Kie的類路徑容器來簡化,但我們可以使用任何Kie Container來建立KieBase。它在定義動態知識模組時非常有用。
一旦我們定義了一個基於STREAM處理模式的Kie base,我們就需要了解不同的選項,我們將需要執行一個Kie session並管理我們的CEP場景。
1.4.2 連續的和離散的規則觸發
當執行我們的CEP規則時,我們首先需要理解的是,我們是否需要以連續或離散的方式執行它們。兩者之間的主要區別如下:
>離散規則觸發將在特定時間點觸發規則。我們的應用將會新增事件和事實資料進Kie session,在一個特定的點,它將會使用 fireAllRules方法觸發任何與工作記憶體相匹配的規則
>連續規則觸發將有一個特定的執行緒,用於在某些資料與規則匹配時觸發規則。它將使用Kiesession的 fireUntilHalt方法來實現這一點,而一個或多個其他執行緒將把事件和事實插入到Kie session中。
這兩種觸發規則的方式完全取決於我們的情況和可能觸發規則的情況。如果我們有一個場景,沒有事件會觸發一個規則,或者換句話說,沒有事件可以被抽象成另一個事件,那麼您應該使用連續規則觸發。另一方面,如果能觸發新規則的唯一因素是將新事件插入到Kie session中,那麼對於我們的情況來說,離散規則的觸發就足夠了。
讓我們來討論幾個例子來理解這兩個場景。
首先,讓我們討論一下離散規則觸發的常見情況:欺詐檢測。大多數欺詐檢測系統將根據來自交易的累積資訊工作。基本上,如果我們有特定數量的具有特定引數的交易,我們可能會考慮欺詐的可能性。在這種情況下,我們觸發規則的唯一方法是插入一個新交易來匹配規則的條件。對於這種情況,我們可以在每次交易或交易批插入到我們的Kie session時呼叫fireAllRules。如果在新增最新資料後不立即執行規則,就不需要觸發任何規則。
在另一個場景中,讓我們想象一個心臟監視器正在向我們的CEP引擎傳送事件。大約每隔一秒,我們就會從示波器上獲得心跳。如果我們獲取事件的時間靠的過近或者不規律,我們可能會發現中風或者心律不齊的複雜事件。如果我們想檢測心臟停止跳動會發生什麼?這將是一個心臟驟停事件。如果我們想發現它,我們的系統將需要在沒有事件發生時觸發規則的能力。這種型別的場景是連續規則觸發案例的典型特徵。
1.4.3 使用會話時鐘進行測試
當建立Kie Sessions來執行基於cep的場景時,一個更有用的配置是配置其內部時鐘。預設方式,Kie Session將會用其執行所在的機器的時鐘來理解時間的流逝。然而,這只是兩個可用配置中的一個,稱為執行時時鐘。另一個允許我們定義一個受應用控制的始終的配置,叫做配置虛擬時鐘。
執行時和虛擬時鐘都 只向一個方向移動(往前走)。但是,如果您呼叫一個特定的稱為advanceTime的方法,那麼偽時鐘就會這樣做。這裡有一個小的例子,說明如何在KIe session中使用虛擬時鐘:
SessionPseudoClock clock = ksession.
getSessionClock();
clock.advanceTime(2, TimeUnit.HOURS);
clock.advanceTime(5, TimeUnit.MINUTES);在前面的例子中,我們告訴時鐘要提前2小時5分鐘。這兩個呼叫只需要幾毫秒的時間,這使得這個時鐘成為測試CEP場景的一個極好的選擇如果您必須檢查兩個事件(它們被插入到Kie session中),其中兩個事件的預設時間戳間隔兩個小時,那麼虛擬時鐘會讓您幾乎立即執行這個案例,執行時時鐘至少需要兩個小時。
為了在我們的基會話中使用偽時鐘,我們需要通過kmodule.xml檔案為它提供一個特定的配置:
<kbase name="cepKbase" eventProcessingMode="stream"
packages="chapter06.cep">
<ksession name="cepKsession" clockType="pseudo"/>
</kbase>我們甚至可以通過KieSessionConfiguration bean來使用它:
KieServices ks = KieServices.Factory.get();
KieContainer kc = ks.getKieClasspathContainer();
KieSessionConfiguration ksconf = ks.
newKieSessionConfiguration();
ksconf.setOption(ClockTypeOption.get(
ClockType.PSEUDO_CLOCK.getId()));
KieSession ksession = kc.newKieSession(ksconf);樣例程式碼在 chapter-06-test專案下。
即使虛擬時鐘最常見的用途是測試,但它通常使用的另一種情況是分散式生產環境。這樣做的原因是,在大型環境中,CEP場景可能在多個伺服器中執行,而虛擬時鐘通常用於在不同的伺服器中輕鬆地同步所有會話的時鐘。一個額外的執行緒或伺服器可以在幾乎相同的時間內呼叫每個伺服器上的定時的機制,並且每個伺服器都有一個Kie session可以提前確保它們都在幾乎相同的時鐘值上執行。這通常比讓多個伺服器的內部時鐘同步更簡單,這是規則負責實時決策時的一個要求。
1.5 Drools CEP的侷限性
Drools CEP的功能非常強大,並且能夠像其他型別的基於Drools的規則一樣快速地解決決策問題。但是,它有一些我們需要注意的架構元素,以便充分利用它。
首先,所有的Kie session都在記憶體中執行。這意味著所有的生存在Kie session中的事件都在記憶體中,而它們仍然與Kie Base中的至少一個規則相關。這可以通過一個事件型別的@expires註釋來克服,但是它仍然需要預先規劃定義Drools CEP服務所需的記憶體數量。一個快速逇方式來確定在一個服務端執行一個Drools CEP需要有多少記憶體:
>確定每個事件例項在Kie SESSION中應該存在多長時間(因為它可能仍然用於觸發規則)。我們稱這個值為a。
>確定在特定時間段內可以接收到多少事件。我們稱其為B
>確定事件例項的大小.我們稱其為C
A * B * C = X,一個非常粗略的估計所需的最少的記憶體Kie session保持所有生活事件的參考。我們還需要小心,因為我們還沒有考慮到儲存在規則條件和Beta網路之間的事件之間的儲存的記憶體消耗。我們將在之後的PHREAK介紹中,提及這個知識點。
另一個需要考慮的限制是在任何永續性機制中儲存Kie session的可能性。當它的內部表示發生變化時,無論它是工作記憶體或者是它的匹配agenda,Kie session通常是持久化了的。對於常規的CEP場景,這可能意味著在每次規則觸發或插入新事件時都要儲存所有的工作記憶體資料。使用基於CEP的Kie session進行這樣的操作,可能意味著每秒儲存數gb的資料。因此,需要在另一個系統中複製一個Kie session的其他機制。
目前,唯一可以複製一種基於CEP的KIE session的方法是在Kie session之間複製小的增量(不需要複製整個工作記憶體)以及制定規則的協調策略(因此,只有一個複製的Kie session實際上會為複製的匹配資料觸發規則)。這些都是定製的機制,每個使用者都應該根據自己的風險來實現自己的功能,因此,建議的替代方案是按域分解CEP場景,並讓不同的伺服器只處理一組案例。
為此,通常第一步是根據資料中的型別或特定元件對事件進行過濾,並將其轉發給特定的Kie session,以便在特定的情況下管理特定的場景。
舉例來說,在伺服器中處理來自小型提供商的所有欺詐檢測案例,並在兩個專用伺服器上進行欺詐檢測。即使是過濾也可以是一個無狀態的會話,建立了將每個事件重定向到相應的Kie Stateful session,如下圖所示
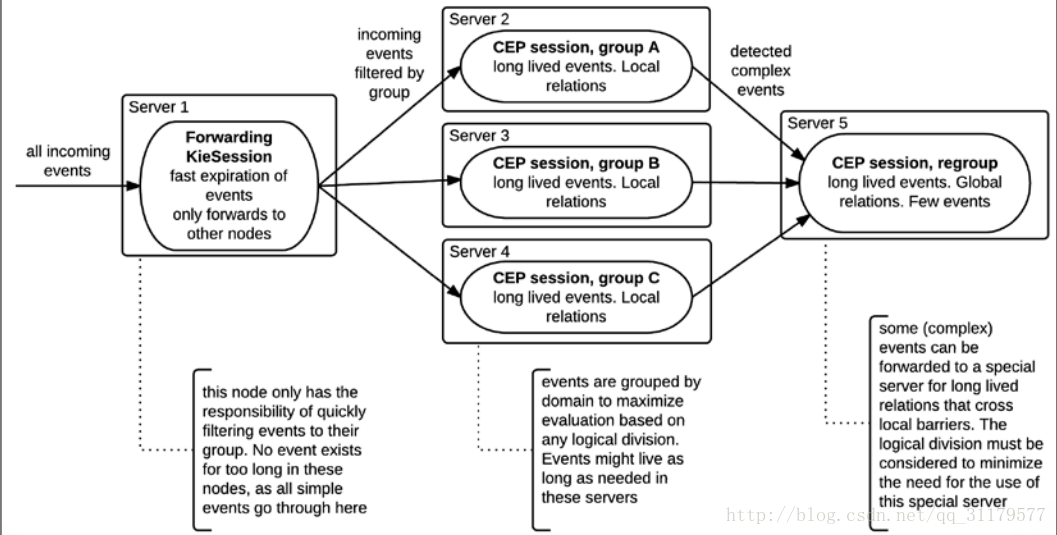
通過這種方式,可以在Drools CEP會話中實現事件吞吐量的增加,並通過新增額外的伺服器來處理(至少在某種程度上)。