
谷歌DataFlow程式設計模型以及Spark/Flink/StreamCQL的相關實現
流式計算框架程式設計介面的標準化,傻瓜化,SQL化,自打穀歌發表Dataflow程式設計模型的Paper起,就有走上臺面的趨勢。各家計算框架都開始認真考慮相關的問題,儼然成為大家競爭的熱點方向。在過去一年多的時間裡,Beam/Flink/Spark在這方面的努力和相關工作也逐漸落地成熟,實際線上成熟應用的日子看起來指日可待了。 所以,翻出一年多前閱讀DataFlow Paper的舊文,更新一下部分過時資訊,重新發表一次。
本文主要闡述DataFlow程式設計模型的思想,基本上可以認為,這是當前各種流式計算的上層程式設計模型背後的理論原型基礎,篇尾再簡單對比一下 Spark Structured Streaming的程式設計模型實現,以及 Flink/Beam/StreamCQL在這方面的相關進展情況。
DataFlow是什麼東西
谷歌的Dataflow首先是一個服務 https://cloud.google.com/dataflow, 為使用者提供以流式或批量模式處理海量資料的能力,該服務的程式設計介面模型(或者說計算框架)也就是下面要討論的Dataflow模型
流式計算處理框架很多,也有大量的模型/框架號稱能夠同時較好的處理流式和批量計算場景,比如Lambda模型,比如Spark小批量模型等等,那麼Dataflow模型有什麼特別的呢?
這就要從流式(streaming) 和批量( batch) 這兩個詞的語意說起,簡單的說,谷歌的同學認為目前的各種計算框架模型以及使用者在一定程度上對這兩個詞的語意的使用姿勢不夠恰當,或者說用這兩個詞來區分應用場景,進而給計算框架分類並不合適。而這種分類給框架的應用甚至設計帶來了一定的認識的誤解和偏差。
谷歌的同學認為,當大家談論到流式計算,或者流式資料時,內心想表達的場景,實際上更準確的說法應該是unbounded data(processing),也就是無邊界的連續的資料(的處理);對應的批量(計算),更準確的說法是bounded data(processing),亦即有明確邊界的資料的處理。而streaming和batch實際上只是這兩種資料集歷史上傳統使用的處理方式而已,這兩者並不完全等價。而隨著技術的發展,繼續用這種方式來分類和看待問題就顯得不夠高大上了。
而Dataflow模型則是谷歌的同學在處理無邊界資料的實踐中,總結的一套SDK級別的解決方案,其目標是做到在非有序的,無邊界的海量資料上,基於事件時間進行運算,並能根據資料自身的屬性進行window操作,同時資料處理過程的正確性,延遲,代價可根據需求進行靈活的調整配置。
DataFlow的底層計算引擎依託於 Millwheel 實時計算框架和FlumeJava批處理框架,在谷歌開源了相關SDK以後,發起了beam專案: http://beam.incubator.apache.org/ , 為了拉攏開源社群的同學,其底層計算引擎也可以替換適配成Spark/Flink等開源計算框架(適配工作持續進行中)
核心思想
先來看看Lambda模型被挑戰的點:用一個流式+批量的拼湊方案去解決海量無限資料的實時統計問題,看起來很美,但是出發點立意有些Low(亦即,認定了這種問題只能通過兩套截然不同的框架模型去協同處理),而維護兩套計算框架模型和處理邏輯的代價始終是這個模型無法克服的痛點。
雖然有各種上層封裝抽象,統一SDK程式設計介面方案的存在,企圖通過一套程式碼,翻譯執行的方式,降低在兩套計算框架模型上開發和維護程式碼的代價,但實際效果往往並不如意,翻譯執行層的存在,並不能抹平兩種計算框架在模型根源上的差異,到頭來真正能複用的程式碼邏輯並不多,簡單的說就是Lambda框架本身並不解決使用者真正的痛點,而只是一種沒有出路的情況下的無奈之舉。
而Dataflow計算模型,則是希望從程式設計模型的源頭上,統一解決傳統的流式和批量這兩種計算語意所希望處理的問題。
和Spark通過micro batch模型來處理Streaming場景(如前,更準確的說法是無邊界資料集)的出發點不同,Dataflow認為batch的處理模式只是streaming處理模式的一個子集。在無邊界資料集的處理過程中,要及時產出資料結果,無限等待顯然是不可能的,所以必然需要對要處理的資料劃定一個視窗區間,從而對資料及時的進行分段處理和產出,而各種處理模式(stream,micro batch,session,batch),本質上,只是視窗的大小不同,視窗的劃分方式不同而已。
比如,Batch的處理模式就只是一個視窗區間涵蓋了整個有邊界的資料集這樣的一種特例場景而已。一個設計良好的能處理無邊界資料集的系統,完全能在準確性和正確性上做到和“Batch”系統一樣甚至應該更好。而不是傳統的認為batch框架的正確性更好,streaming框架顧及了實時性,正確性天然就做不好,必須和batch框架配合走Lambda模型來補足。
那麼無邊界資料集的處理過程中,大家認為天然做不好的點,或者說最難處理的點在哪裡,Dataflow模型是怎麼解決的呢。
這裡又要先說一下在Dataflow模型裡強調的兩個時間概念:Event time和 Process time:
Event time 事件時間就是資料真正發生的時間,比如使用者瀏覽了一個頁面,或者下了一個訂單等等,這時候通常就會有一些資料會被生產出來,比如前者可能會產生一條使用者的瀏覽日誌
而Process time則是這條日誌資料真正到達計算框架中被處理的時間點,簡單的說,就是你的程式是什麼時候讀到這條日誌的
現實情況下,由於各種原因,資料採集,傳輸到達處理系統的時間可能會有長短不同的延遲,在分散式應用場景環境下,不僅是延遲,資料亂序到達往往也是常態。這些問題,在有邊界資料集的處理過程中往往並不存在,或者無關緊要。
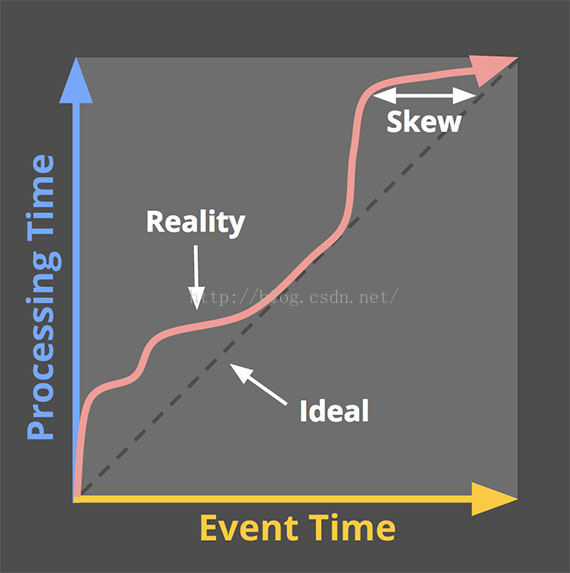
基於這種無邊界資料集的特性,在Dataflow模型中,資料的處理過程中需要解決的問題,被概括為以下4個方面:
- What results are being computed. : 計算邏輯是什麼
- Where in event time they are being computed. : 計算什麼時候(事件時間)的資料
- When in processing time they are materialized. : 在什麼時候(處理時間)進行計算/輸出
- How earlier results relate to later refinements. : 後續資料如何影響(修正)之前的計算結果
清晰的定義這些問題,並針對性的在模型框架層面加以解決,正是Dataflow模型區別於其它流式計算模型的核心關鍵所在。通常的流式計算框架往往模糊或者無法有效的區別對待資料的事件時間和處理時間,對於第4個問題,如何修正資料,也可能缺乏直接的支援。這些問題通常需要開發人員在業務程式碼邏輯層面,自行想辦法解決,因而也就加大了這類資料處理業務的開發難度,甚至讓這種業務的開發成為一個不可能完成的任務。
而更重要的是,針對同一或類似資料集,各種資料處理需求,其核心計算邏輯往往可能是一致的,但是根據應用目標場景,統計口徑可能各有不同。
比如計算活躍使用者數,核心計算邏輯就是一個去重計數邏輯。具體實施時,可能要求計算過去一個小時的活躍使用者,也可能是計算全天的累計的活躍使用者,可能基於實際時間計算也可能基於資料採集時間計算,可能要求更新歷史資料(有資料晚到),也可能出於效率,效能考慮,直接放棄晚到的資料。
Dataflow計算模型的目標是把上述4方面的問題,用明確的語意,清晰的拆分出來,更好的模組化,從而實現在模型層面調整區域性設定,就能快速適應各種業務邏輯的開發需求。
當然,Spark 2.0開始啟動的Structure Streaming API也引入了和Dataflow類似的模型思想,那篇文章裡的很多比較已經不成立了。
理論模型
那麼Dataflow是如何解決上面四個方面的問題呢,基本上,是通過構建以下三個核心功能模型來做到的:
- 一個支援基於事件時間的視窗(window)模型,並提供簡易的API介面:支援固定視窗/滑動視窗/Session(以Key為維度,基於事件時間連續性進行劃分)等視窗模式
- 一個和資料自身特性繫結的計算結果輸出觸發模型,並提供靈活可描述的API介面
- 一個增量更新模型,可以將資料增量更新的能力融合進上述視窗和結果觸發模型中。
視窗模型
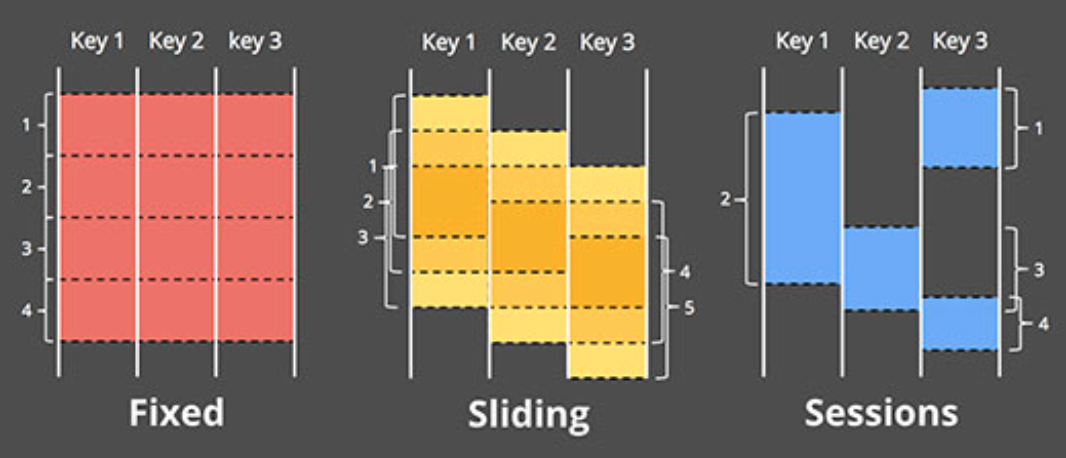
為了在計算框架級別實現基於事件時間的視窗模型,Dataflow系統中,將常見的流式計算框架中的[key,value]兩元組tuple形式的資訊資料,變換成了[key,value, event time, window ]這樣的四元組模型
Event time的引入原因顯而易見,必須要有相關載體承載這個資訊,否則只能基於Process time/Batch time 來劃分視窗
而window視窗標識資訊的引入,個人認為,很重要的一個原因是要支援Session型別的視窗模型,而同時,要將流式和增量更新的支援融合進視窗的概念中,也勢必需要在資料中引入這樣一個顯式的視窗資訊(否則,通常的做法就只能是用micro batch分組資料的方式,隱式的標識資料的視窗屬性)
在訊息的四元組資料結構基礎上,Dataflow通過提供對訊息進行視窗賦值,視窗合併,按key分組,按視窗分組等原子功能操作,來實現各種視窗模型。
視窗觸發模型
多數基於Process time定義的固定視窗或滑動視窗模型,並沒有特別強調視窗觸發這樣一個概念,因為在這類模型中,視窗的邊界時間點,也就是觸發計算結果輸出的時間點,並不需要特別加以區分。
而對於Dataflow這樣的基於事件時間的模型來說,由於事件時間和處理時間之間存在非固定的延遲,而框架又需要正確的處理亂序的資料,這使得判斷視窗的邊界位置,進而觸發計算和結果輸出變得困難起來。
在這一點上,Dataflow部分借用了底層Millwheel提供的Low watermark低水位這樣一個概念來解決視窗邊界的判斷問題,當低水位對應的時間點超過設定的時間視窗邊界時間點時,觸發視窗的計算和結果輸出。但是,低水位的概念在理論上雖然是OK的,在實際場景中,通常是一個概率模型,並不能完全保證準確的判斷事件時間的延遲情況,而且有很多場合對視窗邊界的判斷,使用者自己有自己的需求。
因此,Dataflow提供了可自定義的視窗觸發模型,可以使用低水位做觸發,也可以使用比如:定時觸發,計數觸發,計量觸發,模式匹配觸發或其它外部觸發源,甚至各種觸發條件的邏輯運算組合等機制來應對可能的需求。
增量更新模型
當一個特定時間視窗被觸發以後,後續晚到的資料如何處理,如何對之前觸發結算的結果進行修正,Dataflow在框架層面也提供了直接的支援,基本上包括三種策略:
- 丟棄:一旦特定視窗觸發過,對應視窗的資料就丟棄,晚到的資料也丟棄
- 累計:觸發過的視窗對應的資料保留(保留時間策略也可調整),晚到的資料更新對應視窗的輸出結果
- 累計並更正:和累積模式類似,區別在於會先對上一次視窗觸發的結果傳送一個反相修正的資訊,再輸出新的結果,便於有需要的下游更正之前收到的資訊
通常來說,丟棄策略實現起來最簡單,既沒有歷史資料負擔,對下游計算也不產生影響。但是前提條件是,資料亂序或者晚到的情況不嚴重或者不重要或者不影響最後的統計結果的精度
累計策略,從視窗自身的角度來說,實現起來也不復雜,除了記憶體代價會高一些,因為要保留歷史視窗的資料,但是存在的問題是有些下游運算邏輯是基於上游運算結果計算的,下游計算邏輯能否正確處理重複輸出的視窗結果,正確的進行去重或者累加,往往是個問題。
累計並更正策略,就視窗自身邏輯來說,實現上會更加複雜一點,但是下游計算邏輯的編寫複雜性其實才是最難的。反相修正資訊,是為了給下游提供更多的資訊來解決上述視窗運算結果重複輸出問題,增加了下游鏈路去重資料的能力,但實際上,這個邏輯需要下游計算邏輯的深度配合才能實現,個人覺得,除了部分計算拓撲邏輯相對簡單的程式能夠正確處理好這種情況,依賴關係稍微複雜一點的計算鏈路,靠反相修正資訊,要做到正確的累加或去重還是很困難的。
舉個例子,實際情況下,如果你自己寫程式,比如在storm中計算當日UV資訊,如果手工程式設計,你很可能採取的辦法是:加大時間視窗(一個視窗一天),在一定時間段內保留多個視窗(比如今天和昨天的兩個視窗),累計,定時覆蓋輸出全量結果。這種方式來解決正確累計和處理晚到資料。倘若這個UV資訊要再進一步傳導到下游計算任務,那下游計算任務最好也能處理全量覆蓋這種場景,靠反向資訊修正幾乎是不可能的(因為UV資訊通常不具備簡單累加特性)。
相關研究,專案等
Spark Structured streaming
Spark 2.x版本,新增的structured streaming API,針對原先的streaming程式設計介面DStream的問題進行了改進,Dstream的問題包括:
- 框架自身只能針對Batch time進行處理,很難處理event time,很難處理延遲,亂序的資料
- 流式和批量處理的API還是不完全一致,兩種使用場景中,程式程式碼還是需要一定的轉換
- 端到端的資料容錯保障邏輯需要使用者自己小心構建,增量更新和持久化儲存等一致性問題處理難度較大
這些問題其實也就是Dataflow中明確定位需要解決的問題。
通過Structured Streaming API,Spark計劃支援和Dataflow類似的概念,如Event time based的視窗策略,自定義的觸發邏輯,對輸出(sink)模組的更新模式(追加,全量覆蓋,更新)的built-in支援,更加統一的處理無邊界資料和有邊界資料等。
總體看來,Spark 2.x的structured streaming 模型和Dataflow有異曲同工之處,設計的目標看起來很遠大,甚至給出了一份功能比較表格來證明其優越性
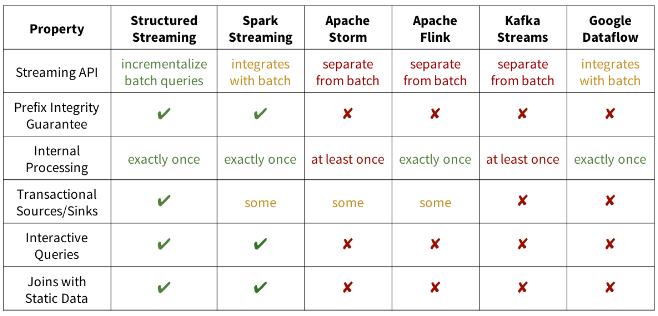
但上面的表格明顯的是有“揚長避短”的偏向性的。比如在2.1的版本中,Structured Streaming還是Alpha版的,所支援的類Dataflow模型的功能還相對簡單。2.2版本中,號稱production了,不過,應該還是從穩定性的角度來說的,功能完整性方面還有一定差距。
比如還不支援session window,追加模式更新只能支援無聚合操作的場景,還有各種功能還停留在設想階段,對於join等操作還有各種各樣的限制等等,這些部分和dataflow業已實現的功能還有較大的差距。
對於exactly once傳送的保障,Structured Streaming要求外部資料來源具備offset定位的能力,再加上snapshot等機制來實現,而dataflow是通過對訊息在框架內部進行持久化來實現replay,不依賴外部資料來源的能力。
另外,個人理解像 prefix integrity, Transactional sink等概念,實際上是對上下游讀寫介面的一個封裝,幫使用者實現了一些業務邏輯(比如prefix integrity 的實現依託于于per key有序性的保證,這是由外部source源提供的保障,比如 file/kafka等;而Transactional sinks等則是比如對jdbc介面邏輯的封裝),整體上偏外圍功能一點,用這些特性來和其它框架比較不一定客觀,因為設計理念不太不一樣。
而在Dataflow的模型設計中,使用者能更加細化的定義每個環節的步驟和設定,所以沒有把一些邏輯替使用者實現,更多的是以模組化的方式,留給使用者去自己選擇,而Structured steaming則把很多事情包辦了,定製的餘地較小,靈活性應該會差一些,不過這也給程式的自動優化帶來了一些便利
Beam
Beam https://github.com/apache/beam 是由谷歌發起的apache 專案,基本來說就是實現dataflow程式設計模型的SDK專案,目標是提供一個high level的統一API程式設計介面,後端的執行引擎支援對接 APEX/Spark/Flink/Cloud dataflow
目前的程式語言支援Java和Python,2017年5月釋出了第一個穩定版本2.0.0。
這個專案的前景如何,不太好說,單就適配各個後端的角度來說,就Spark後端來說,在spark 1.x時代,這種high level的程式設計模型抽象是對spark程式設計模型的一種add on,有一定的附加價值,但是按照spark 2.x structured streaming的發展路線來說,這一層抽象就稍微顯得有些多餘了。而基於Java的語法,在表達的簡潔性上,相比scala也會帶來一些額外的代價。
Flink
Dataflow的核心就是視窗和觸發模型,而Flink在這兩方面的實現,最接近Dataflow的理論原型,事件時間驅動,各種視窗模型,自定義觸發和亂序/晚到資料的處理等等。
Flink的Data Streaming API通過定義window方法,和window內的資料需要使用的聚合函式比如:reduce,fold,window(前兩者增量,後者全量),以及視窗觸發(Trigger)和視窗內資料的淘汰(Evictor)方法,讓使用者可以實現對Dataflow模型中定義的場景的靈活處置,比如:需要在大資料量,大視窗尺度內實現實時連續輸出結果的目的。通過allow late資料的時間範圍來處理晚到資料。
不過晚到資料會觸發聚合結果的再次輸出,這個和Dataflow的模型不同的是,Flink本身是不提供反向資訊輸出的,需要業務邏輯自行做必要的去重處理。
對於Flink的實現,個人比較贊同的一點,是對資料的聚合和淘汰方式,給使用者留下了足夠靈活的選擇,畢竟在工程實踐中,長時間,大視窗,連續結果輸出這種場景很常見,比如實時統計一天之類各個小時段的PV/UV,5秒更新一次結果。這種情況下,要避免OOM,還要正確處理晚到資料,追資料等問題,預聚合和提前觸發的能力就必不可少了。
至於SQL化這條路,Flink的SQL語法解析和優化是依賴Apache Calcite實現的,而Calcite對window語法的支援才剛剛開始,所以FlinkSQL目前還不支援Streaming模型
整體感覺Flink目前在Dataflow模型思想方面實現的成熟度比Spark Structured Streaming要好
華為的StreamCQL on Storm
華為的StreamCQL方案,是構建在Storm之上的,簡單的說就是提供了一個流式SQL的程式設計介面,執行時,底層翻譯成Storm的拓撲邏輯提交執行。
整體上,StreamCQL做的好的地方是,SQL的支援比較完整,其它框架,在Stream這個場景,SQL的支援,或多或少還在開發完善中。
但StreamCQL最大的問題,是它的程式設計模型,和Dataflow的模型還有很大的差距。
整體上來說,StreamCQL的框架邏輯,就是使用視窗來buffer一部分資料,然後當視窗結束條件滿足時,釋放出這批資料給下游觸發一次計算流程。
粗看和Dataflow沒有太大的區別,但實際上,最主要的差距,是StreamCQL對視窗模型的定義,其次是觸發和資料更新模型的缺失。
StreamCQL的視窗模型,支援Batch(也就是固定間隔視窗)和Slide,但是視窗的劃分預設是基於處理時間Process Time的!!!而且,雖然視窗內的資料可以再細分Partition,但視窗只有一個。。。
不能同時處理幾個視窗,意味著無法處理資料亂序或者晚到的情況。而Slide視窗的定義,也和主流的Slide視窗定義不同,每次對下游更新離開視窗範圍的資料,看起來更像一個FIFO Queue的實現。
儘管可以使用Trigger關鍵字,將Batch視窗的觸發條件改為訊息中的某一個欄位或者表示式,從而通過指定事件時間欄位,近似的達到基於事件時間的視窗劃分。
但是,實際上,因為單一的視窗機制,這樣做,也只能處理事件源嚴格遞增的場景。而現實情況中,來自不同客戶端的事件,時間必然是亂序的,實時流計算的來源也主要是分散式訊息佇列(如kafka),進一步導致全域性的無序,所以現實中,基本是不可能存在訊息中事件時間嚴格遞增的場景。
此外,由於缺乏靈活的資料更新和淘汰方式的定義,StreamCQL的主流程基本上是Buffer一堆資料,然後計算加淘汰這批資料,所以,缺乏資料預聚合的能力,這就導致視窗範圍內所有的資料在視窗關閉之前,都必須儲存在記憶體中。
因此即使是事件時間嚴格遞增或者只關心Process Time的場景,Window的範圍也不能太大,否則很容易超過記憶體限制,造成OOM,而實際上,多數場景,只需要保留增量聚合後的結果資料就足夠了。
總體來說,StreamCQL的SQL語法比較完善,但計算模型在理論和架構實現方面存在較大的不足,所以如果不加改造,在實際工程應用中很難有大的做為。
參考資料
常按掃描下面的二維碼,關注“大資料務虛雜談”,務虛,我是認真的 ;)
