
谷歌Dataflow程式設計模型和spark 2.0 structured streaming
作者:劉旭暉 Raymond 轉載請註明出處
主要介紹一下Dataflow程式設計模型的基本思想,最後面再簡單比較一下spark 2.0 structured streaming的程式設計模型== 是什麼 ==谷歌Dataflow首先是一個服務https://cloud.google.com/dataflow,為使用者提供以流式或批量模式處理海量資料的能力,該服務的程式設計介面模型(或者說計算框架)也就是下面要討論的dataflow model流式計算框架處理框架很多,也有大量的模型/框架號稱能較好的處理流式和批量計算場景,比如Lambda模型,比如Spark等等,那麼dataflow模型有什麼特別的呢?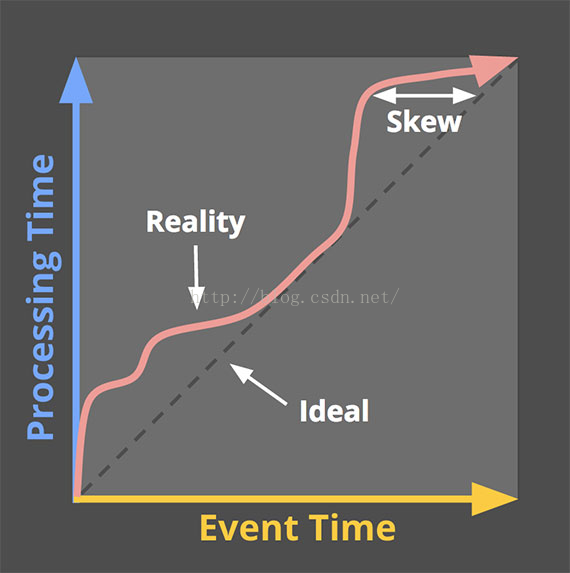
基於這種無邊界資料集的特性,在Dataflow模型中,資料的處理過程被概括為以下4個方面的問題的解決:
– What results are being computed.:計算邏輯是什麼
– Where in event time they are being computed. :計算什麼時候(事件時間)的資料
– When in processing time they are materialized.:在什麼時候(處理時間)進行計算
– How earlier results relateto later refinements. :後續資料的處理結果如何影響之前的處理結果
清晰的定義這些問題,並針對性的在模型框架層面加以解決,正是Dataflow區別於其它流式計算模型的核心關鍵所在。通常的流式計算框架往往模糊或者無法有效的區別對待資料的事件時間和處理時間,對於第4個問題,也可能缺乏直接的支援。這些問題通常需要開發人員自行在程式碼業務邏輯上想辦法解決,因而也就加大了這類資料處理業務的開發難度,甚至成為一個不可能完成的任務。
而更重要的是,針對同一或類似資料集,各種資料處理需求,其核心計算邏輯往往可能是一致的,比如計算活躍使用者數,核心計算邏輯就是一個去重邏輯。但是根據應用目標場景,統計口徑可能各有不同,比如可能要求計算過去一個小時的活躍使用者,也可能是計算全天的累計的活躍使用者,可能基於實際時間計算也可能基於資料採集時間計算,可能要求更新歷史資料(有資料晚到),也可能處於效率,效能考慮,直接放棄晚到的資料。Dataflow計算模型的目標是把上述4方面的問題,用明確的語意清晰的拆分出來,更好的模組化,快速適應各種業務邏輯開發需求。
例如在https://cloud.google.com/dataflow/blog/dataflow-beam-and-spark-comparison一文中,就用實際的例子比較了dataflow和spark在處理這類資料業務邏輯時,所需要進行的開發工作,總體的意思就是用dataflow模型開發,程式碼更簡潔更容易理解,開發效率更高,維護成本更低。不過,需要注意的是,spark2.0的structurestreamingAPI也引入了和Dataflow類似的模型思想,這篇文章裡的很多比較已經不成立。
== 實現 ==
那麼Dataflow是如何解決上面4方面的問題的呢,基本上,是通過構建以下三個核心功能模型來做到的:
- 一個支援基於事件時間的視窗(window)模型,並提供簡易的API介面:支援固定視窗/滑動視窗/Session(以Key為維度,基於事件時間連續性進行劃分)等視窗模式
- 一個和資料自身特性繫結的計算結果輸出觸發模型,並提供靈活可描述的API介面
- 一個增量更新模型,可以將資料增量更新的能力融合進上述視窗和結果觸發模型中。
=== 視窗模型 ===
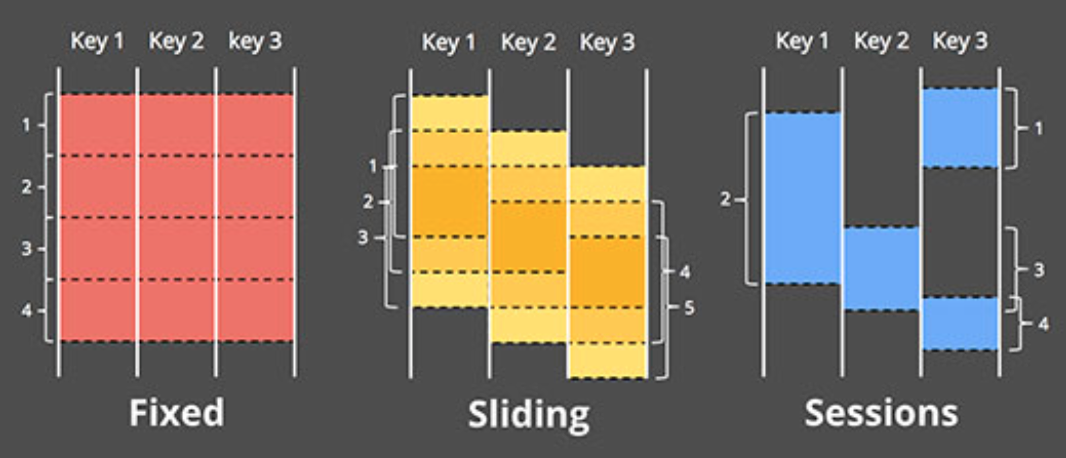
為了在計算框架級別實現基於事件時間的視窗模型,Dataflow系統中,將常見的流式計算框架中的[key,value]兩元組tuple形式的資訊資料,變換成了[key,value, event time, window ]這樣的四元組模型,eventtime的引入原因顯而易見,必須要有相關載體承載這個資訊(否則只能基於processtime/batchtime劃分視窗),而window視窗標識資訊的引入,個人認為,很重要的一個原因是要支援Session型別的視窗模型,而同時,要將流式和增量更新的支援融合進視窗的概念中,也勢必需要在資料中引入這樣一個顯示的視窗資訊(否則,通常的做法就只能是用microbatch分組資料的方式,隱式的標識資料的視窗屬性)
在訊息的四元組資料結構基礎上,Dataflow通過提供對訊息進行視窗賦值,視窗合併,按key分組,按視窗分組等原子功能操作,來實現各種視窗模型。
=== 觸發模型 ===
多數的基於Processtime的固定或滑動視窗模型,並沒有顯示的視窗計算結果觸發這樣一個概念的定義,因為不太需要,視窗的邊界時間點,也就是觸發結果輸出的時間點。而對於Dataflow來說,因為事件時間和處理時間的延遲,以及框架需要正確處理無序資料的需求,使得判斷視窗的邊界,觸發計算和結果的輸出變得困難起來。在這一點上,Dataflow部分借用了底層Millwheel提供的Lowwatermark低水位這樣一個概念來解決視窗邊界的判斷問題,當低水位對應的時間點超過設定的時間視窗邊界時間點時,完成視窗的計算和結果輸出。但是,低水位的概念理論上雖然是OK的,在實際場景中,通常是一個概率模型,並不能完全保證準確的判斷事件時間的延遲情況,而且有很多場合對視窗邊界的判斷,使用者自己有自己的需求。
因此,Dataflow提供了可自定義的視窗觸發模型,可以使用低水位做觸發,也可以使用比如:定時觸發,計數觸發,計量觸發,模式匹配觸發或其它外部觸發源,甚至各種觸發條件的邏輯運算組合等不同等機制來應對可能的需求。
=== 增量更新 ===
當視窗被觸發以後,對於後續晚到的資料,對已經觸發過的視窗,如何處理,Dataflow在框架層面也提供了直接的支援,基本上包括三種策略:
- 丟棄:一旦特定視窗觸發過,對應視窗的資料就丟棄,晚到的資料也丟棄。
- 累積:觸發過的視窗對應的資料保留(保留時間策略也可調整),晚到的資料更新對應視窗的輸出結果
- 累計並更正:和累積模式類似,區別在於會先對上一次視窗觸發的結果傳送一個反相修正的資訊,再輸出新的結果,便於有需要的下游更正之前收到的資訊。
== 相關研究,專案等 ==
=== spark 2.0 ===
Spark 2.0版本,新增的structuredstreamingAPI,針對原先的streaming程式設計介面DStream的問題進行了改進,Dstream的問題包括:
- 框架自身只能針對Batch time進行處理,很難處理eventtime,很難處理延遲,亂序的資料
- 流式和批量處理的API還是不完全一致,兩種使用場景中,程式程式碼還是需要一定的轉換
- 端到端的資料容錯保障邏輯需要使用者自己小心構建,增量更新和持久化儲存等一致性問題處理難度較大
通過StructuredStreamingAPI,Spark一方面支援了和Dataflow類似的概念,如Eventtimebased的視窗策略,自定義的觸發邏輯,對輸出(sink)模組的更新模式(追加,全量覆蓋,更新)的builtin支援,更加統一的處理無邊界資料和有邊界資料等。
總體看來,Spark 2.0的structuredstreaming模型和Dataflow有異曲同工之處,設計的目標看起來很遠大,甚至給出了一份功能比較表格來證明其優越性
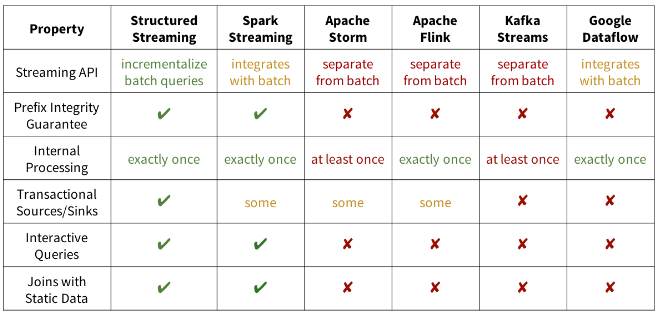
不過在2.0的版本所支援的類Dataflow模型的功能還相對簡單,比如sessionwindow,waterflow等概念都還需要在2.1或者後續的版本中保證,也還不支援輸出的更新模式,追加模式更新只能支援無聚合操作的場景,還有各種功能還停留在設想階段,對於join等操作還有各種各樣的限制等等,這些部分和dataflow業已實現的功能還有較大的差距。
對於exactlyonce傳送的保障,spark2.0要求外部資料來源具備offset定位的能力,再加上snapshot等機制來實現,而dataflow是通過對訊息在框架內部進行持久化來實現replay,不依賴外部資料來源的能力。
另外,個人理解像prefixintegrity,Transactionalsink等概念,實際上是對上下游讀寫介面的一個封裝,幫使用者實現了一些業務邏輯(比如prefixintegrity的實現依託于于perkey有序性的保證,這是由外部source源提供的保障,比如file/kafka等;而Transactionalsinks等則是比如對jdbc介面邏輯的封裝),整體上偏外圍功能一點,用這些特性來和其它框架比較不一定客觀,因為設計理念不太不一樣。Dataflow的模型設計中,使用者能更加細化的定義每個環節的步驟和設定,所以不會把一些邏輯替使用者實現,更多的是以模組化的方式,留給使用者去自己選擇,而Structuredsteaming則把很多事情包辦了,定製的餘地較小,靈活性應該會差一些,不過這也給程式的自動優化帶來了一些便利。當然,這是我個人初步粗淺的理解,不見得準確。
=== beam ===
Beam http://beam.incubator.apache.org/是一個由谷歌發起的apache專案,目前還處於incubator狀態,基本來說就是實現dataflow程式設計模型的SDK專案,目標是提供一個highlevel的統一API程式設計介面,後端的執行引擎計劃對接spark/flink/clouddataflow。目前的程式語言支援Java,計劃加入python。這個專案的前景如何,不太好說,單就適配各個後端的角度來說,就spark後端來說,在spark 1.x時代,這種highlevel的程式設計模型抽象是對spark程式設計模型的一種addon,有一定的附加價值,但是按照spark 2.0 structuredstreaming的發展路線來說,這一層抽象就稍微顯得有些多餘了。而基於Java的語法,在表達的簡潔性上,相比scala也會帶來一些額外的代價。
== 參考資料 ==