
Inception-V1到Inception-V4
GoogLeNet主要思想為Inception結構
主要參考了http://caffecn.cn/?/question/255
一、
題外話;吳恩達老師的深度學習課程講的非常的明白。
1.對影象進行卷積是壓縮提取影象特徵資訊的一個過程,構造不同的卷積核提取出的就是不同的特徵。卷積神經網路厲害的地方是將濾波核當做引數去進行訓練,找到各種各樣的奇怪特徵,這是計算機視覺中最為有效的思想之一。
2.關於步長的總結:如果我們有一個n*n的影象,用f*f的過濾器做卷積,輸出維度就是(n-f+1)*(n-f+1)。每次影象縮小有兩個缺點:第一個缺點是每次做卷積操作,你的影象就會縮小。第二個缺點是那些在角落或者邊緣區域的畫素點在輸出中採用較少,意味著丟掉了影象邊緣位置的許多資訊。
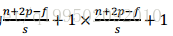 ,商不是整數,則向下取整。還解答了我的一個疑惑。雖然叫做卷積,但是實際上並不是數學意義上的卷積操作(沒有進行濾波核的翻轉),正確叫法應該是互相關。
,商不是整數,則向下取整。還解答了我的一個疑惑。雖然叫做卷積,但是實際上並不是數學意義上的卷積操作(沒有進行濾波核的翻轉),正確叫法應該是互相關。3.神經網路是什麼,無論是預測還是分類問題,都是找到一條可以很好擬合現有資料的 線 的問題。而得到這條線的過程就是神經網路訓練的過程。也就是通過特徵找到結論的過程。找到結論的過程是使用啟用函式對資料進行處理。多個線性啟用函式可以合成一個。所以我們大多使用非線性啟用函式。然後通過損失函式最終得到合適的 線 ,也就是結論。
4.卷積神經網路:將卷積特性同神經網路相結合,具有3個基本思想:感受野,權值共享,降取樣。
1*1卷積:在網路中添加了一個非線性函式,非常方便的進行升維或者降維,減少了引數。將資訊進行了整合。
二、
四篇論文:
[v1] Going Deeper with Convolutions, 6.67% test error, http://arxiv.org/abs/1409.4842
[v2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error, http://arxiv.org/abs/1502.03167
V1:找到最優的區域性稀疏結構並將其覆蓋為近似的稠密元件。Inception層作用就是代替人工來確定卷積層中的過濾器型別。將通過不同大小卷積核後得到的維度影象做拼接。這樣就是不同尺度上的融合。增加了兩個輔助用的softmax層用於前向傳導梯度,避免梯度消失。通過上面所述對神經網路的理解,從這也就不難看出:Inception層將多種卷積核相融合,神經網路訓練後會得到需要的權值,而這就是對過濾器的選擇。
大量使用1*1卷積層來減少運算數量並將維度保持一致。合理的構建瓶頸層既可以顯著縮小表示層的規模,又不會降低網路效能,從而節省了計算。

在構建Inception模組時可以發現一般遵從以下規則:卷積層前使用1*1卷積減少引數數量。後層卷積核數一般為前層1*1卷積的2倍,1*1卷積直接拼接。如果使用pooling層,後接1*1卷積調整維度,縮小通道數。例項如下:
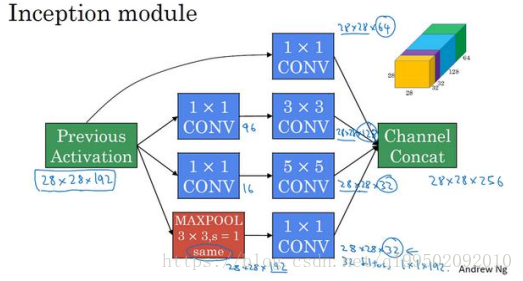
整個網路就是有多個inception模組連線所構成的。
V2:加入BN層,用2個3*3代替5*5
V3:7*7分解為1*7,7*1,精細了設計。
V4:丟下了V3的包袱,改寫了部分結構,更加有利於模組化的使用。結合ResNet得到Inception-ResNet-v1和v2。
論文翻譯網址如下:https://ask.julyedu.com/question/7711
看到的一些結論:
1.單個框架效能的提升不會引起組合效能大幅的提高。
2.使用殘差連線能夠極大的提高訓練速度
3.在傳統層的頂部而非所有層的頂部中使用batch-normalization。
4.對殘差網路進行縮放有益於訓練的穩定性。
總的來說,到目前來看,inception的結構已經不是最優的網路模型。不過,在inception進化過程中的小tricks都是現在很常用的技巧。這個學習過程是很有必要的。模組化的思想也越來越受到大家的重視。