
谷歌Inception網路中的Inception-V3到Inception-V4具體作了哪些優化?
- [v1] Going Deeper with Convolutions, 6.67% test error, http://arxiv.org/abs/1409.4842
- [v2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error, http://arxiv.org/abs/1502.03167
- [v3] Rethinking the Inception Architecture for Computer Vision, 3.5% test error, http://arxiv.org/abs/1512.00567
- [v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error, http://arxiv.org/abs/1602.07261
CNN結構演化圖:
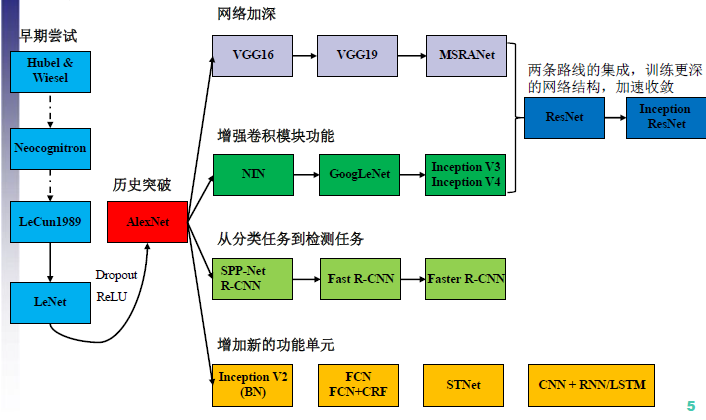
2012年AlexNet做出歷史突破以來,直到GoogLeNet出來之前,主流的網路結構突破大致是網路更深(層數),網路更寬(神經元數)。所以大家調侃深度學習為“深度調參”。
那麼解決上述問題的方法當然就是增加網路深度和寬度的同時減少引數,Inception就是在這樣的情況下應運而生。Inception v1模型
Inception v1的網路將1x1,3x3,5x5的conv和3x3的pooling,堆疊在一起,一方面增加了網路的width,另一方面增加了網路對尺度的適應性;
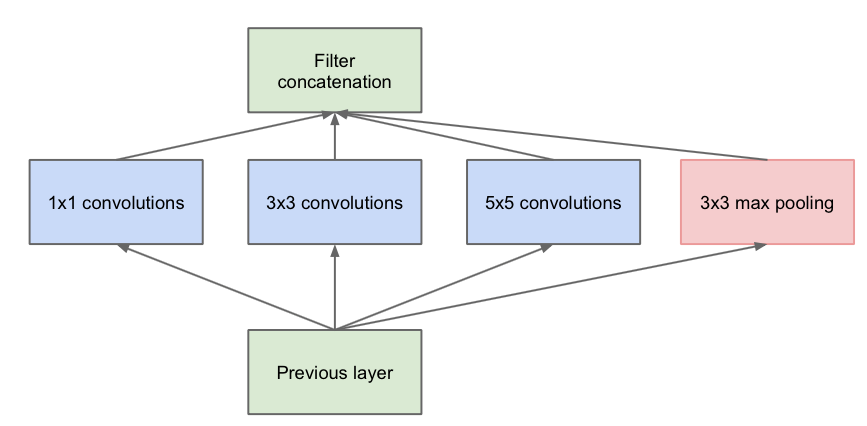
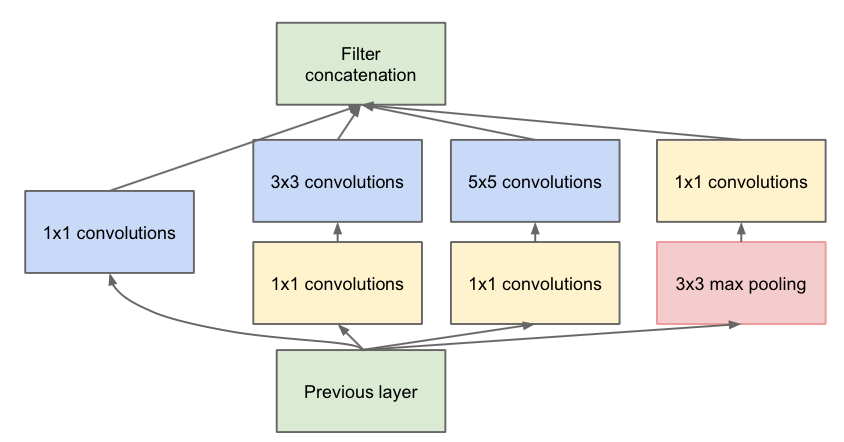
第一張圖是論文中提出的最原始的版本,所有的卷積核都在上一層的所有輸出上來做,那5×5的卷積核所需的計算量就太大了,造成了特徵圖厚度很大。為了避免這一現象提出的inception具有如下結構,在3x3前,5x5前,max pooling後分別加上了1x1的卷積核起到了降低特徵圖厚度的作用,也就是Inception v1的網路結構。
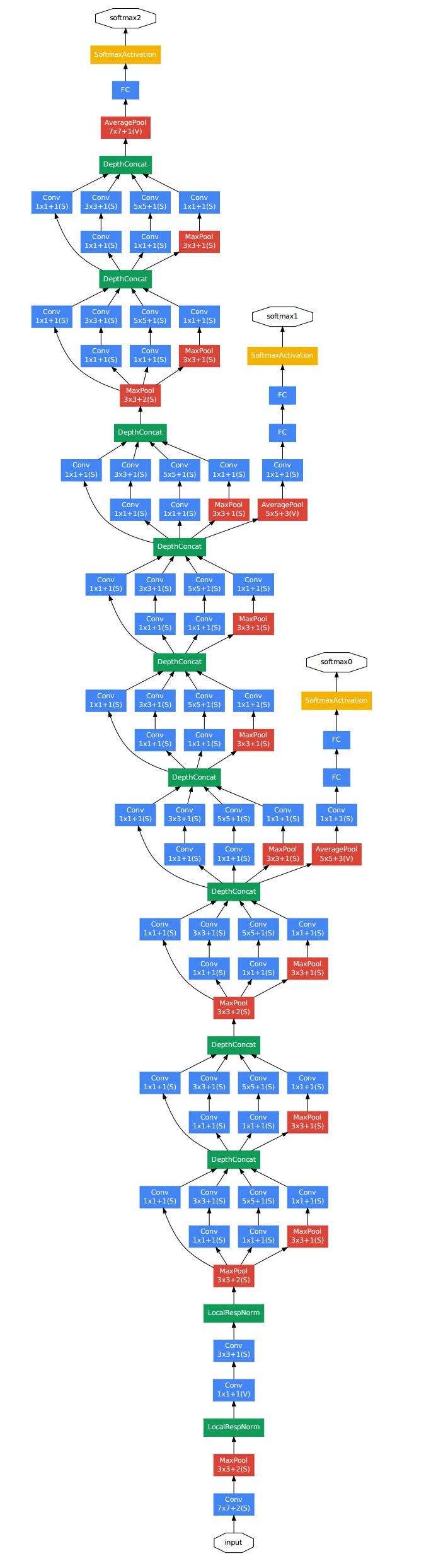
下面給出GoogLeNet的結構圖:
Inception v2模型
使用3×3的已經很小了,那麼更小的2×2呢?2×2雖然能使得引數進一步降低,但是不如另一種方式更加有效,那就是Asymmetric方式,即使用1×3和3×1兩種來代替3×3的卷積核。這種結構在前幾層效果不太好,但對特徵圖大小為12~20的中間層效果明顯。
Inception v3模型
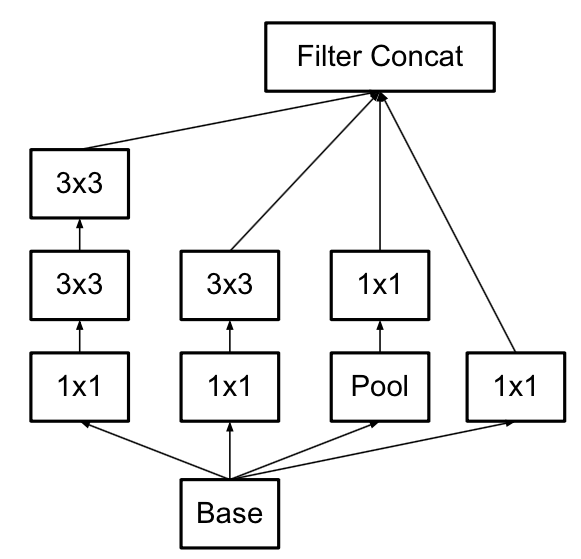
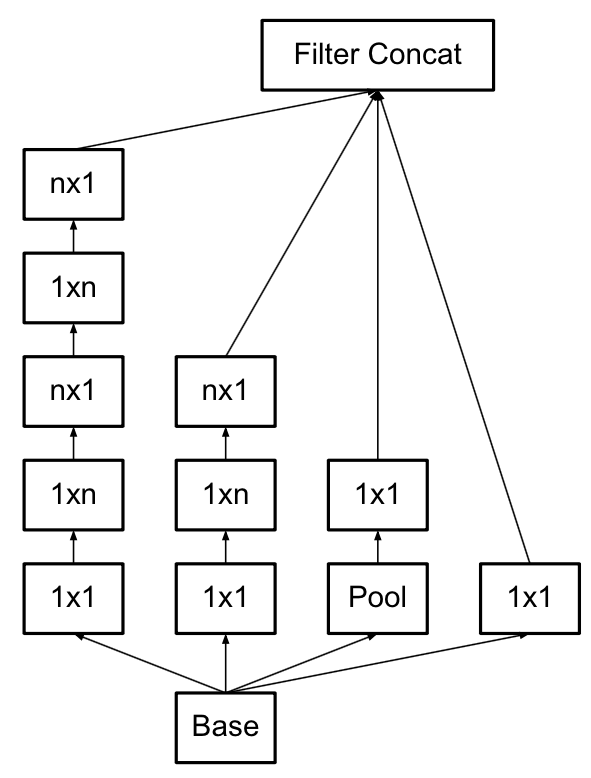
v3一個最重要的改進是分解(Factorization),將7x7分解成兩個一維的卷積(1x7,7x1),3x3也是一樣(1x3,3x1),這樣的好處,既可以加速計算(多餘的計算能力可以用來加深網路),又可以將1個conv拆成2個conv,使得網路深度進一步增加,增加了網路的非線性,還有值得注意的地方是網路輸入從224x224變為了299x299,更加精細設計了35x35/17x17/8x8的模組。
Inception v4模型
v4研究了Inception模組結合Residual Connection能不能有改進?發現ResNet的結構可以極大地加速訓練,同時效能也有提升,得到一個Inception-ResNet v2網路,同時還設計了一個更深更優化的Inception v4模型,能達到與Inception-ResNet v2相媲美的效能。
轉自:http://blog.csdn.net/u014114990/article/details/52583912