
物體檢測演算法SSD簡述
其實SSD的論文是在YOLOv2之前看的,但由於那時本人初識機器學習,還不瞭解基本概念,所以只是囫圇吞棗,沒能理解得很透徹,於是今天重新拾起SSD,並編輯出一篇學習記錄,希望對大家有所幫助。
如果本文中某些表述或理解有誤,歡迎各位大神批評指正。
下面進入正題。
論文原文中提到,作者提出的SSD演算法比之前的YOLO演算法更快、更精確,精確度可以媲美之前的Faster R-CNN。
為了理解方便,本文將原論文中涉及到的概念重新排序,以便看起來邏輯通順。
【Multi-scale feature maps for detection】
SSD最大的亮點之一就是利用多尺度的feature map進行分類檢測。
如果有朋友不是很清楚feature map是什麼,暫時可以將其理解成網路中每個卷積層的輸出。
詳情可以參看本人的另外一篇部落格:
或自行百度。
在SSD中,不同層級的卷積層輸出的feature map尺度不同。
像這樣:
(這張圖很重要,本文將多處使用到這張圖)
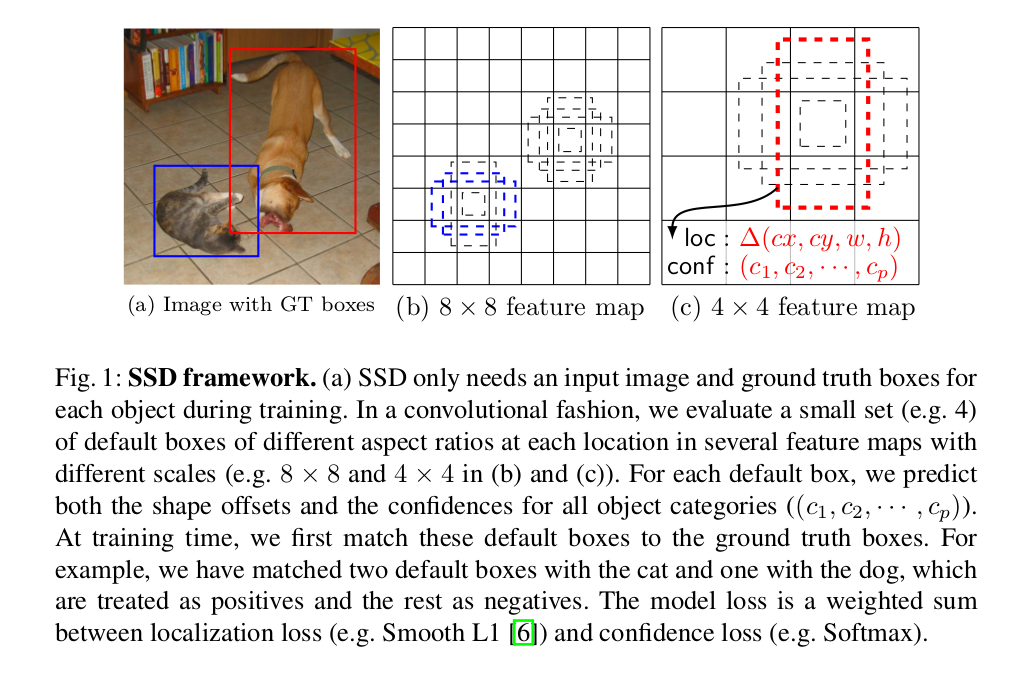
其中,8*8的feature map和4*4的feature map對應不同layer的卷積層輸出。
在網路架構上,層級的大小不同(例如,第二層卷積輸出8*8的feature map,第三層卷積輸出4*4的feature map,第四層卷積輸出2*2的feature map),這對多尺度物體的檢測提供了便利——2*2的feature map對大尺度的物體進行檢測,而8*8的feature map對小尺度的物體進行檢測(具體例子可以參見上圖中的對貓和狗的檢測)。
【注:大小尺度對應feature map的劃分與default boxes的生成有關,這裡先不對其進行詳細說明,下文中會提到。】
【Default boxes and aspect ratios】
(這裡的default boxes給我的感覺有點像YOLOv2中的anchor boxes)
對於feature map中每個的location(作者在論文中將其稱為feature map location,個人將其理解為feature map中的cell,為了方便表述,下文這樣的location稱為cell),都會生成一組default boxes,用YOLOv2論文中的話說,這些default boxes是根據人類經驗事先選擇的。所以,這些default boxes相對於每個cell的位置是固定的。於是,在每個feature map中,我們(事實上是網路)可以瞭解到ground truth boxes與default boxes之間的位置關係,進而預測座標偏移。不僅如此,網路還可以預測boxes中的物體類別,對每個類別的劃分進行score。
現在讓我們來做一個計算:
假設每個cell會生成k個default boxes,網路中一共有c個分類類別,位置資訊利用四個屬性來表述(如上圖所示,分別為default boxes的x偏移量、y偏移量、寬度w、高度h)。
那麼每個cell中就會使用(c+4)*k個卷積核(filter)進行運算(每個屬性對應一個卷積核);
對應的m*n的feature map中就會使用到一共(c+4)*k*m*n個卷積核。
說到這裡,讓我們看看SSD的網路架構(原文中將其與YOLO進行對比):
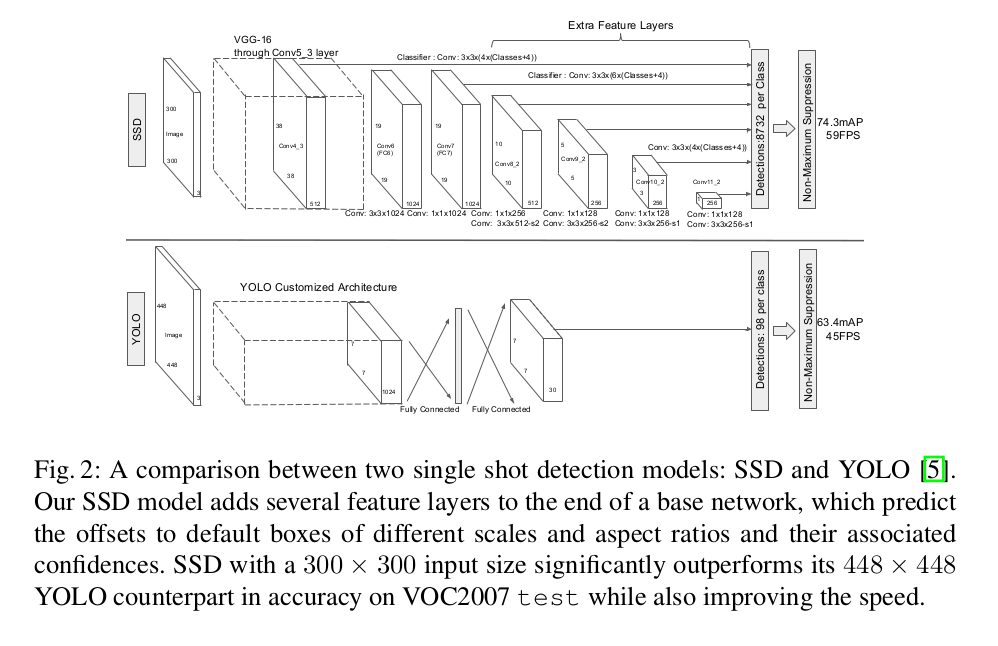
對於p通道為m*n的feature layer,利用3*3卷積核在m*n的每個位置,產生表明類別score(確定分類),或者座標偏移(確定位置)的輸出值。
bounding box的座標偏移是其相對於一個feature map中default box位置而測量的。
【Choosing scales and aspect ratios for default boxes】
前面有提到,SSD中的default boxes是根據經驗事先選擇的,那麼,SSD是如何對其進行選擇的呢?
由於SSD利用不同尺度(lower and upper)的feature maps進行檢測,不同卷積層所對應的feature maps尺度不同,所以default boxes的生成也與feature maps所在的層級有關。
在SSD中,假設想要利用m個feature map進行預測,那麼default boxes的尺度計算公式如下:
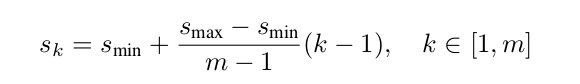
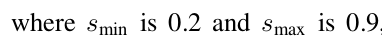
其中,最低層(lowest layer)default boxes的尺度為0.2,最高層(highest layer)default boxes的尺度為0.9,k表示feature map所處的層數。
此外,由於一個cell要生成多個default boxes,default boxes的寬高比(aspect ratios)也有所不同,論文中使用了:1,2,3,1/3,1/2五個值作為寬高比(ar)。
以此經過一點小小的計算,我們可以算出每個default boxes寬和高(w代表寬、h代表高)的大小:
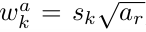
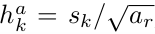
經過運算,我們可以發現,論文中的尺度表述方式 s 是default boxes面積的開平方。
為了增加default boxes的個數(或者只是因為作者喜歡偶數對稱性),作者對於寬高比為1的情況另外生成了一個新的default box,它的大小(s)是這樣的(會比其他default boxes的面積大一點):
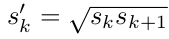
至此,作者對每個feature map中的每個cell生成了6個default boxes。
實驗表明,default boxes的個數越多,模型的效能會越好,但是開銷也會越大。
具體原因在本人的一篇介紹YOLOv2的部落格中有所分析:
然後,將每個default box的中心放置於這個座標處:
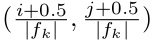
其中,分母表示feature map的大小(4*4 feature map所對應的分母就是4),分子中的i,j取值範圍為[0,|fk|)。
經過與feature map簡單的比較,我們可以看到,將所有可能的i,j值帶入座標之後,對應的座標剛好鋪滿整個feature map的所有cell(這也是為什麼i,j的取值範圍為左閉右開)。
本節過後,我們就可以回答第一節所提出的那個有關待檢測物體尺度的問題了:
由於低層feature map劃分較細(例如,8*8),較高層feature map劃分較粗(例如,2*2),所以feature map中的default boxes大小也不同。很明顯可以看出的是,2*2feature map中的default boxes面積要比8*8feature map中的default boxes面積大,所以高層feature map中對應檢測的物體尺度較大,低層feature map中對應檢測的物體尺度較小。
【Matching strategy】
在訓練期間,網路需要決定哪個default box匹配對應的ground truth box(網路的輸入)並據此訓練網路。
在本節以及後面的描述中,經常會出現jaccard overlap這個高階大氣上檔次的詞語,原文中使用的是這個詞,本文未對其進行修改,但其實jaccard overlap就是我們平時所說的交併比:IoU。
對IoU不瞭解的朋友們可以參看本人另外一篇部落格:
機器學習中的一些基本概念(未完待續)
匹配策略分為兩步:
1.用MultiBox中的最佳jaccard overlap(即,IoU最大)匹配每一個ground truth box與default box,用以保證每個ground truth box至少有一個default box相對應。
2.如果default box與ground truth box的jaccard overlap超過某閾值(例如,0.5),那麼就把該default box與該ground truth box進行匹配。
這個策略允許為一個ground truth box匹配多個有所重疊的default boxes,而不是要求ground truth box只選擇與其有最大重疊的某一個default box。
我們將第一步和第二步中所有匹配到ground truth box的default box稱為正樣本(positive sample);
將所有沒有匹配到ground truth box的default box稱為負樣本(negative sample)。
【Hard negative mining】
匹配過後,我們會發現,只有少數default boxes是正樣本,而絕大多數是負樣本。
所以,作者將負樣本進行篩選:以confidence loss由高到低對負樣本進行排序,將排序靠後的負樣本剔除掉,直到正樣本和負樣本的比例約為1:3。
那麼,confidence loss是什麼?
【Training objective】
神經網路訓練的目標往往是將一個loss值最小化,我們可以將這個loss值看作模型預測結果與我們期望得到的真實結果的偏差。
有了這樣一個概念,對confidence loss的理解就很簡單了。
在SSD中,模型需要預測的東西一共分兩大類:位置、分類。SSD將對應於分類的loss稱為confidence loss(conf),對應於位置的分類稱為localization loss(loc),模型的總loss可以簡單看做conf和loc的加權平均值(但事實上可能會比加權平均值複雜一些)。
公式部分由於排版等問題不在本文中進行講解,有興趣的朋友們可以參看論文原文進行研究。
【Data augmentation】
這部分其實可以看做作者為了防止過擬合、增多訓練資料、提高魯棒性而使用到的一個小技巧——資料增廣。
對於每一張圖片,訓練的時候隨機進行如下操作:
1.使用原始影象
2.取樣一個patch,與物體的最小jaccard overlap為0.1,0.3,0.5,0.7或0.9
3.隨機取樣一個patch
且在上述取樣操作過後,得到的patch被resize到一個固定的尺寸。接著,對圖片進行概率為0.5的水平翻轉。
經過如上這麼一折騰,就增加了資料多樣性。
【Experimental Results】
費了這麼多的周折,SSD在一些資料集上的測試結果如下:
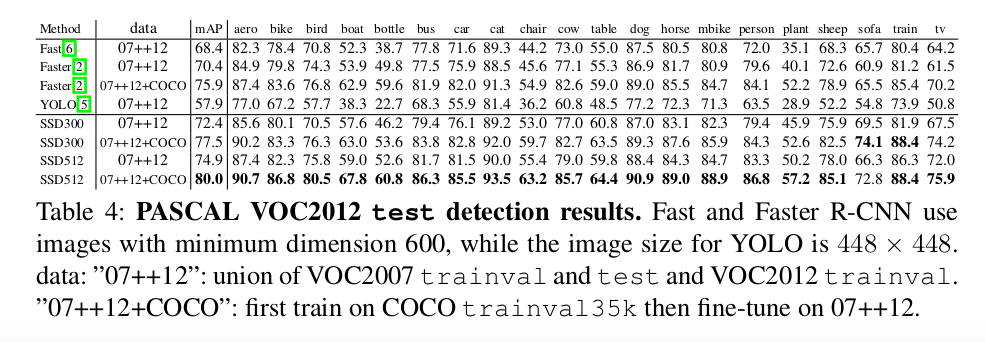
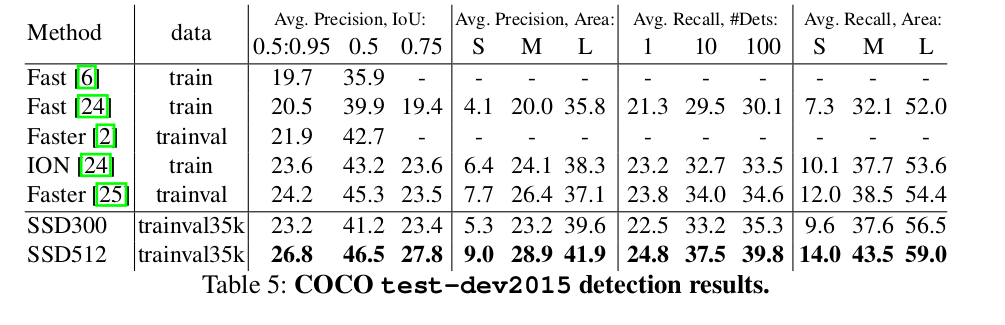
兩個字,優秀!
更多的實驗過程、實驗資料等資料在論文原文中都有詳細列出,本文就不再贅述。
【寫在後面】
如果對本文哪裡有不理解的地方,多看看第一張圖,相信對理解SSD會有很大幫助。
論文原文地址:
SSD: Single Shot MultiBox Detector