
Lucene學習之拼寫檢查
阿新 • • 發佈:2019-01-02
在搜尋引擎中,我們往往會遇見下面的情景

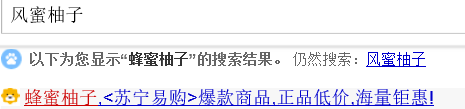
這其實就是拼寫檢查的應用,lucene的suggest模組就是為此而設的。
首先需要的是一個有效的拼寫檢查的源詞典。
private static String dicpath = "G:\\downloads\\LJParser_release\\dictionary.dic";
//初始化字典目錄
//最後一個fullMerge引數表示拼寫檢查索引是否需要全部合併
// 一句話總結:indexDictionary就是將字典檔案裡的詞進行ngram操作後得到多個詞然後分別寫入索引。
spellchecker.indexDictionary(new 使用ngram來標識類似的單詞,ngram簡單的來說就是表示一個單詞中一定長度的所有鄰接字母組合,比如lucene當ngram=3時,那麼字母組合包括:luc|uce|cen|ene所以ngram的選擇必定會影響到檢查匹配的效率。
那麼直接來看一下程式碼(程式碼借鑑自益達)
import java.io.IOException;
import 一、SpellChecker的建構函式需要傳入需要被檢查的文件索引;

二、為字典建立索引(當然ngram分詞的過程被封裝了)
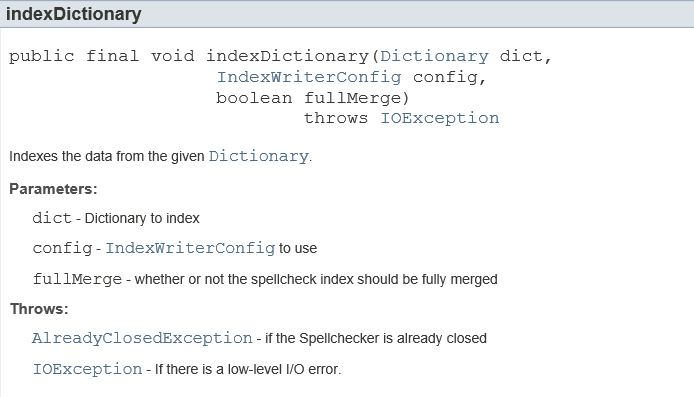
三、計算並返回相似的詞:
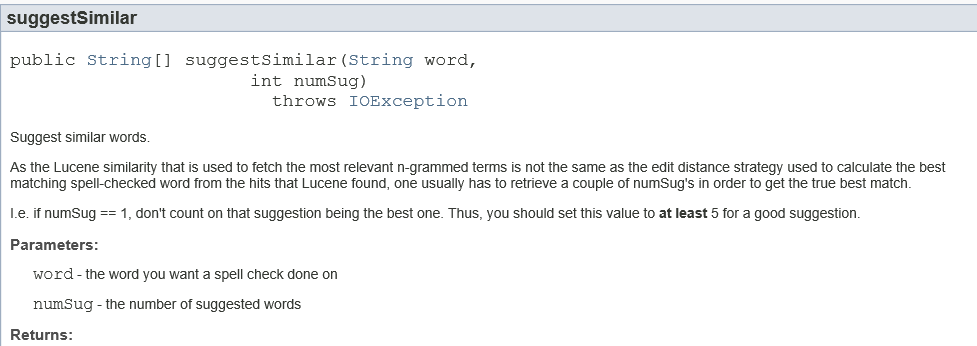
計算兩個詞相似度的實現採用LevensteinDistance進行字串相似度計算。LevensteinDistance就是edit distance(編輯距離)。編輯距離,又稱Levenshtein距離(也叫做Edit Distance),是指兩個字串之間,由一個轉成另一個所需的最少編輯操作次數。許可的編輯操作包括將一個字元替換成另一個字元,插入一個字元,刪除一個字元。
例如將kitten一字轉成sitting:
sitten (k→s)
sittin (e→i)
sitting (→g)
俄羅斯科學家Vladimir Levenshtein在1965年提出這個概念。
以上就是簡單拼寫檢查的基本過程。
接下來看下選取不同ngram的結果:
這是字典檔案:

ngram = 4時(編輯距離看作4)

ngram = 1時(編輯距離看作1)
