
lucene學習之針對多索引的搜尋
阿新 • • 發佈:2019-01-02
在實際應用中,很多應用程式保持多個分離的Lucene索引,但有需要在搜尋過程中能夠將結果合併輸出,比如新聞網站每天都會建立不同索引,但是搜尋一個月的新聞時就需要合併輸出結果。這時可以使用如下方式:
mreader = new MultiReader(readera,readern);
searcher = new IndexSearcher(mreader);//4.0以後的MultiSearcher替換成這樣可以看到我們需要使用MultiReader這個類,將讀不同索引的reader封裝在一塊。
下面是實現程式碼
import java.io.IOException TermRangeQuery類查詢包含從h到t開頭的動物名稱,匹配的文件來自於兩個不同的索引。結果如下:
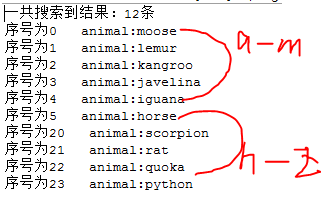
當然上面程式是一個searcher單執行緒操作,也可以使用多執行緒的辦法,lucene5中提供了ParalleLeafReader類。