
基於GAN的人臉光照處理
原文連結:Face Image Illumination Processing Based on Generative Adversarial Nets
摘要:眾所周知,光照的變化會嚴重影響二維人臉分析演算法的效能,如人臉標記和人臉識別。不幸的是,在大多數實際應用中,照明條件通常是不受控制和不可預測的。為了解決這個問題,已經有很多方法被開發出來,但是效果很差,特別是對於光線條件極端的影象。此外,傳統的光照處理方法大多隻在灰度影象上顯示,對人臉影象的對齊要求非常嚴格,在實際應用中應用有限。本文提出了一種基於生成對抗性網路(GAN)的人臉影象光照處理問題,並將其作為一種風格轉換任務進行重構。關鍵的見解是在不知道它們的真實分佈的情況下,使用GAN在兩個域之間的強大對映能力。在這種新視野下,我們開發了一種新的多尺度對偶判別網路,並利用多尺度對偶學習來進行視覺逼真的光照處理。我們提倡利用傳統方法的洞見,在影象質量評價中加入重構學習和兩項新的損失項,以加強除生成影象細節外的所有其他光照的保護。在CMU Multi-PIE和FRGC資料集上的實驗表明,該方法可以獲得良好的光照歸一化結果,並保持了良好的視覺質量。
網路架構:
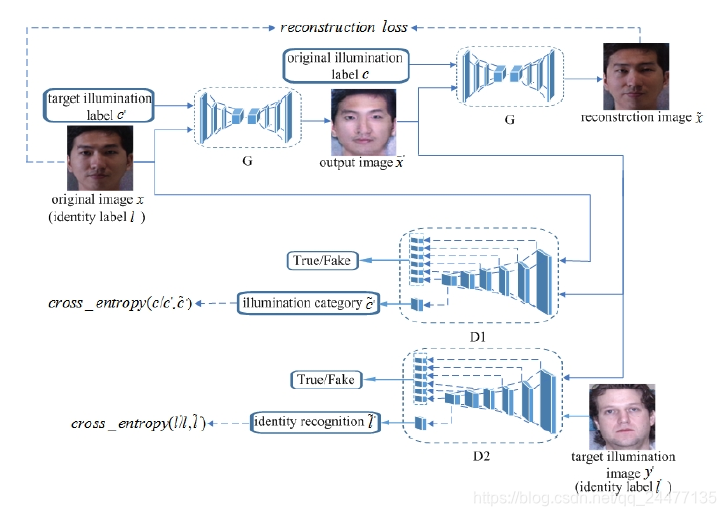
對於該網路架構的理解:首先,有一個生成器G和兩個判別器D。生成器的輸入是原始人臉影象x,以及目標的光照強度c',通過G生成一張目標光照的人臉影象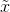
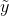
和'之間的損失為重構損失,後面會有提到。我們期望的目的是D1能將'的光照識別為c',D2能將'的身份識別為l。
損失函式:
1、判別器損失函式
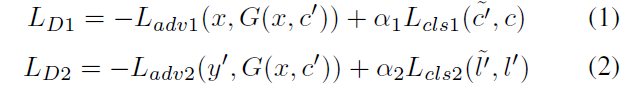
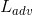
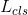
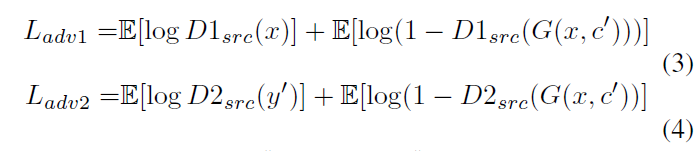

其中,α1和α2是權重引數。為判別器輸出的為真實影象的概率。G希望式(3)、(4)最小化,而D1和D2希望他們最大化。在式(5)、(6)中,
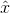
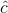
2、生成器損失函式
基礎損失:

將',身份判別為
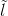
重構損失:

為了進一步保證翻譯後的影象在只改變輸入中與光照相關的部分的同時保留輸入影象的內容,彌補訓練資料的不足,論文對生成器應用了迴圈一致性損失,定義為式(8)。可以看出該損失計算的就是網路架構圖最上面的那部分。作者們說他們首先採用了L1正則化作為重構損失。
SSIM(結構相似度)損失:

其中ux、uy分別表示影象X和Y的均值,σX、σY分別表示影象X和Y的方差,σXY表示影象X和Y的協方差,即
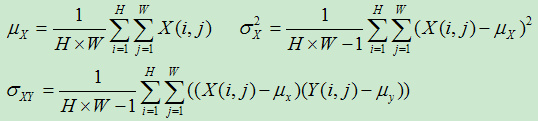
(圖片來自:https://www.cnblogs.com/vincent2012/archive/2012/10/13/2723152.html)
c1、c2、c3為常數,為了避免分母為0的情況,通常取c1=(k1*L)^2, c2=(k2*L)^2, c3=c2/2, 一般地k1=0.01, k2=0.03, L 是畫素值範圍,論文中為1.式(9)、(10)、(11)組合在一起有:
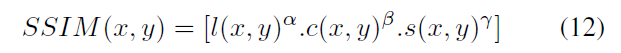
取α, β, γ為1,則
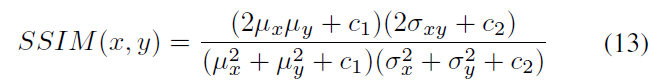
SSIM越接近1,兩個影象之間越相似。最終用於訓練的SSIM損失為:

PSNR(Peak signal-to-noise ratio)峰值信噪比損失:
首先彩色影象3通道的的均方誤差為:

PSNR為:
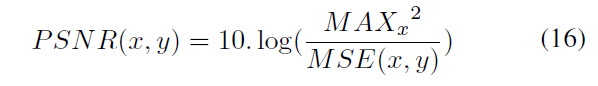
其中MAXx為x中畫素的最大值,論文中為1.最終的PSNR損失為:
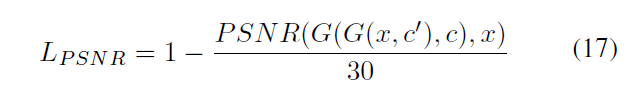
30為作者們的經驗值,取正則化PSNR的值。
最終,G的損失函式為:

其中,α3=10和α4=5
訓練演算法:

其中Kd = 5, Kg = 1, T= 1000。 在前500次迭代中,G和D的學習率都是0.0001,後面逐漸線性衰減至0.λgp = 10。另外,為了效能更優,作者們把式(3)、(4)利用WGAN的改進方法替換為:

因為沒有原始碼,所以更多的細節無法知道。
實驗效果圖:




想說的:
國內的論文都很少提供程式碼,所以不能學到更細節的東西。而且論文裡面的網路架構給的並不是很明確,生成網路如何實現、判別器網路如何實現?和CycleGAN或者patchsGAN有什麼區別都不得而知。
感覺這個就是CycleGAN的一個擴充套件與應用,不同域之間的轉換對映,這個是多個域到一個域,還可以一個域到多個域。