
簡單搜尋(dfs與bfs我的個人理解)
- 因為搜尋是建立樹的這種結構上的。無論是深度優先搜尋還是廣度優先搜尋,都是從樹根開始依次向下搜尋。
- 這個時候深度優先和廣度優先的區別就出來了。
- 很顯然,深度優先是從一個樹根一直搜尋到最底層的子節點然後再回到根進行另外一個子節點的搜尋
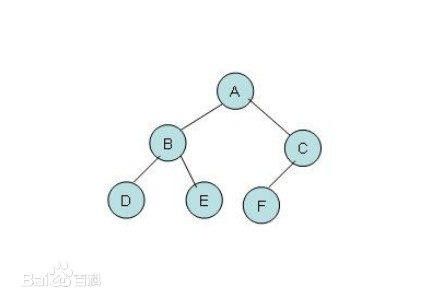 比如針對與這個樹我們的深度搜索是從A->B->D然後返回B->E然後返回A->C->F。
比如針對與這個樹我們的深度搜索是從A->B->D然後返回B->E然後返回A->C->F。- 我們可以通過棧的思想來進行搜尋,A入棧,B入棧,D入棧然後搜尋,D出棧,E入棧,進行搜尋,E出棧,B出棧,C入棧,F入棧進行搜尋,然後全部出棧。
- 當然實際上是通過遞迴的操作來實現棧上的搜尋。
- 接下來說說廣度優先搜尋
- 廣度優先搜尋顧名思義,以橫向優先,所以我們的搜尋是逐層搜尋。
- 搜尋順序是A,B->C,D->E->F.
- 首先,將A入隊,進行搜尋判斷。
- 將B,C入隊,A出隊,進行搜尋判斷。
- 將D,E,F入隊,B,C出隊進行搜尋判斷。
- 清空佇列。
為了避免重複搜尋,我們可以開一個布林陣列,進行判斷是否搜尋。
相關推薦
簡單搜尋(dfs與bfs我的個人理解)
說到簡單搜尋,主要就是將以深度優先搜尋和廣度優先搜尋。為什麼要叫深度優先和廣度優先的搜尋呢?因為搜尋是建立樹的這種結構上的。無論是深度優先搜尋還是廣度優先搜尋,都是從樹根開始依次向下搜尋。這個時候深度優先和廣度優先的區別就出來了。很顯然,深度優先是從一個樹根一直搜尋到最底層的
DFS與BFS——理解簡單搜尋(中文虛擬碼+例題)
新的方法和概念,常常比解決問題本身更重要。————華羅庚 引子 深度優先搜尋(Deep First Search) 廣度優先搜尋(Breath First Search) 當菜鳥們(比如我)初步接觸演算法的時候,會接觸這兩種簡單的盲目搜尋演算法,相較與其他眾多
深度優先搜尋(DFS)與廣度優先搜尋(BFS)
深度優先搜尋的基本模型 void dfs(int step) { 判斷邊界 嘗試每一種可能 for(int i=0; i<n; i++) { 繼續下一步 dfs(step+1); } 返回 } 輸出一個
HDU 2102 A計劃 DFS與BFS兩種寫法
blog ons bsp 求解 stream eof node 耗時 {} 1.題意:一位公主被困在迷宮裏,一位勇士前去營救,迷宮為兩層,規模為N*M,迷宮入口為(0,0,0),公主的位置用‘P‘標記;迷宮內,‘.‘表示空地,‘*‘表示墻,特殊的,‘#‘表示時空傳輸機,走到
圖論算法之DFS與BFS
nod pty pop 直觀 遍歷 必須掌握 取出 二分 最短 概述(總) DFS是算法中圖論部分中最基本的算法之一。對於算法入門者而言,這是一個必須掌握的基本算法。它的算法思想可以運用在很多地方,利用它可以解決很多實際問題,但是深入掌握其原理是我們靈活運用它的關鍵所在
數據結構之DFS與BFS
存儲 reat pac name 無向圖 using style 頂點 分享 深度搜索(DFS) and 廣度搜索(BFS) 代碼如下: 1 #include "stdafx.h" 2 #include<iostream> 3
關於JS中原型鏈中的prototype與_proto_的個人理解與詳細總結
轉載自:https://www.cnblogs.com/az96/p/6014621.html 一直認為原型鏈太過複雜,尤其看過某圖後被繞暈了一整子,今天清理硬碟空間(渣電腦),偶然又看到這圖,勾起了點回憶,於是索性複習一下原型鏈相關的內容,表達能力欠缺邏輯混亂別見怪(為了防止新人__(此處指我)__被在此
@dynamic 與 @synthesize 關鍵詞個人理解
@synthesize的語義是如果你沒有手動實現setter方法和getter方法,那麼編譯器會自動為你加上這兩個方法。 @dynamic告訴編譯器,屬性的setter與getter方法由使用者自己實現,不自動生成。 (當然對於readonly的屬性只需提供getter即
圖的遍歷之DFS與BFS
圖的遍歷 圖的遍歷指的是從圖中的任一頂點出發,對圖中的所有頂點訪問一次且只訪問一次。圖的遍歷操作和樹的遍歷操作功能相似。圖的遍歷是圖的一種基本操作,圖的許多其它操作都是建立在遍歷操作的基礎之上。 根據訪問節點的順序,我們可以分成兩種方法來對圖進行遍歷。分別是深度
poj 1426 Find The Multiple (簡單搜尋dfs)
題目: Given a positive integer n, write a program to find out a nonzero multiple m of n whose decimal representation contains only the digits 0 and 1.
演算法導論--圖的遍歷(DFS與BFS)
圖的遍歷就是從圖中的某個頂點出發,按某種方法對圖中的所有頂點訪問且僅訪問一次。為了保證圖中的頂點在遍歷過程中僅訪問一次,要為每一個頂點設定一個訪問標誌。通常有兩種方法:深度優先搜尋(DFS)和廣度優先搜尋(BFS).這兩種演算法對有向圖與無向圖均適用。
DFS與BFS遍歷
深度優先遍歷 1.深度優先遍歷的遞迴定義 假設給定圖G的初態是所有頂點均未曾訪問過。在G中任選一頂點v為初始出發點(源點),則深度優先遍歷可定義如下:首先訪問出發點v,並將其標記為已訪問過;然後依次從v出發搜尋v的每個鄰接點w。若w未曾訪問過,則以w為新的出發點繼續進
DFS與BFS的區別、用法、詳解?
寫在最前的三點: 1、所謂圖的遍歷就是按照某種次序訪問圖的每一頂點一次僅且一次。 2、實現bfs和dfs都需要解決的一個問題就是如何儲存圖。一般有兩種方法:鄰接矩陣和鄰接表。這裡為簡單起 見,均採用鄰接矩陣儲存,說白了也就是二維陣列。 3、本文章的小測試部分的測試
圖的儲存與遍歷(鏈式前向星中的DFS與BFS)
圖的儲存方式:1.圖的陣列(鄰接矩陣)儲存表示,其中無向圖的儲存方式為對稱矩陣陣列,有向圖的儲存方式為非對稱矩陣陣列。求最短路徑時常常採用陣列儲存表示各點間的路徑。2.邊集方法 邊的定義: stuct edge_set{
資料結構之——用C++實現鄰接表的DFS與BFS
首先我們要知道鄰接表的基本思想: 鄰接表儲存的基本思想:對於圖的每個頂點vi,將所有鄰接於vi的頂點鏈成一個單鏈表,稱為頂點vertex的邊表(對於有向圖則稱為出邊表),所有邊表的頭指標和儲存頂點資訊的一維陣列構成了頂點表。 在這裡我打算將一個無向圖的鄰接表的建立,以及相
DFS與BFS的總結
BFS與DFS的討論:BFS:這是一種基於佇列這種資料結構的搜尋方式,它的特點是由每一個狀態可以擴展出許多狀態,然後再以此擴充套件,直到找到目標狀態或者佇列中頭尾指標相遇,即佇列中所有狀態都已處理完畢。 DFS:基於遞迴的搜尋方式,它的特點是由一個狀態拓展一個狀態,然後
基於鄰接表儲存的圖的DFS與BFS遍歷
#include <iostream> #include <stdio.h> #include <stdlib.h> #include <queue> using namespace std; #define MAXNODE
資料結構:圖之DFS與BFS的複雜度分析
BFS的複雜度分析。 BFS是一種借用佇列來儲存的過程,分層查詢,優先考慮距離出發點近的點。無論是在鄰接表還是鄰接矩陣中儲存,都需要藉助一個輔助佇列,v個頂點均需入隊,最壞的情況下,空間複雜度為O(v)。 鄰接表形式儲存時,每個頂點均需搜尋一次,時間
DFS與BFS詳解(很不錯的)
有需要關注微信公眾號:演算法那些事兒 --------------------- 咱們由BFS開始: 首先,看下演算法導論一書關於 此BFS 廣度優先搜尋演算法的概述。 演算法導論第二版,中譯本,第324頁。 廣度優先搜尋(BFS) 在Prime最小生成樹演算法,
學習圖論(一)——DFS與BFS
一、圖的基本要素 1.頂點/節點(vertex); 2.邊(edge),連線兩個點,可以為無向邊也可以為有向邊,可以為有權邊也可以為無權邊; 3.連通圖:圖上的任意兩個點之間都是連通的。 即是任意兩個點都有一條或者多條邊連線著。 4.連通分量:最大連通子