
《Online Video Object Segmentation via Convolutional Trident Network》論文筆記
基於三端卷積網路的線上視訊目標分割
針對半監督視訊目標分割任務,作者採取了和MaskTrace類似的思路,以光流為主。 本文亮點在於: 1.使用共享主幹,三輸出的自編碼器。 2.對一些視訊中確定性畫素建模,分割前後景。 3.對被遮擋又重新出現的物體使用前後景GMMs損失建模識別,增加正確率。 |
Abstract
我們可以使用光流量向量傳遞前面幀的分割效果到後續幀,但是這樣會產生錯誤。因此作者提出了一個三端網路(CTN) - 輸出分割概率,確定性前景概率和確定性後景概率,然後使用馬爾科夫隨機場優化得到最終結果。本文提出了一種半監督的線上視訊物件分割演算法,該演算法接受使用者在第一幀處對目標物件的註釋。我們使用光流向量將前一幀的分割標籤傳播到當前幀
Proposed Algorithm

演算法流程如下:
1.首先輸入當前幀t和前一幀t-1的分割掩模,前一幀的分割掩模在optcal flow的指導下預測出t幀的大致樣子。
2.同時對t幀和傳播後的掩碼進行裁剪擷取路徑。經過前景後景抽取的掩碼和裁剪後的 t 幀輸入到網路得到三張概率圖。
3.對概率圖進行MRF優化得到第t幀的分割效果。
Propagation of Segmentation Labels
對於畫素點p = [x,y] T,從I (t-1)到I (t)的標籤傳播為:

其中S (t-1)為前一幀的分割標籤圖。[u,v]為I (t)到I (t-1)的後向光流向量。

Inference via Convolutional Trident Network
編碼結構採用VGG-16,224x224x3為輸入,由13個卷積層,3個全連結層和5個池化層組成。

分割概率需要精準風格邊界,所以需要快捷結構獲取低層特徵資訊。確定性前景或後景只判斷最可能確定的畫素點,所以不需要細節資訊。前景後景的輸入大小調整到14×14和VGG輸出對齊,因為只是估計確定性畫素點,所以相當於低通濾波的大小調整可以這麼設計。卷積層加BN + RELU。

Train Strategy
介紹完網路結構,接下來要說怎麼訓練,因為原始資料集一般都只帶有標籤掩碼。
給定輸入圖片(a)中,根據邊距進行裁剪,與圖片的形狀大小成正比。然後對掩模降質(降解),對掩蔽區域填充[0.5)的隨機強度,然後遮蓋部分或圓形噪聲點(e)。對降質後的圖片進行高斯smoothing和閾值化得到兩個Ground truth。
推理階段,擷取圖片和傳播後的ħ輸入網路,H需要多擷取50畫素點然後調整大小。
Markov Random Field Optimization
優化目標函式: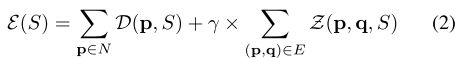
其中前景後景的作用點在於一元能量函式:

Reappearing Object Detection
如何定義不連續的畫素點來檢測重新出現的目標,作者定義了畫素點的不連續性
假設前一幀的畫素點為p_head,當前幀為p,大於某閾值即為不連續。
對第一幀和第(T-1)幀使用前景和後景的的GMM。那麼一個屬於重新出現部分的不連續點的前景高斯損失就會低於後景高斯損失。高斯損失定義在公式(3 )。
Result



作者又提出了一個快速的版本。

實驗結果圖:

Conclusions
提出了一種半監督的線上視訊物件分割演算法。首先,分割標籤對映從前一幀傳播到當前幀。 然後,CTN產生三個概率圖,針對二元標籤問題量身定製。 為了描繪目標物件,我們通過採用定製的概率圖來執行MRF優化。 實驗結果表明,所提出的演算法明顯優於DAVIS基準資料集[36]中的最新傳統演算法。