
人群計數:Single-Image Crowd Counting via Multi-Column Convolutional Neural Network(CVPR2016)
本博文主要是CVPR2016的《Single-Image Crowd Counting via Multi-Column Convolutional Neural Network》這篇文章的閱讀筆記,以及對人群計數領域做一個簡要介紹。
Abstract
這篇論文開發了一種可以從一個單幅的影象中準確地估計任意人群密度和任意角度的人群數目。文章提出了一種簡單有效的的多列卷積神經網路結構(MCNN)將影象對映到其人群密度圖上。該方法允許輸入任意尺寸或解析度的影象,每列CNN學習得到的特徵可以自適應由於透視或影象解析度引起的人/頭大小的變化,並能在不需要輸入圖的透視先驗情況下通過幾何自適應的核來精確計算人群密度圖。作者提到他們訓練得到的MCNN模型要優於現有的其他方法。
Introduction
公共場合中通過攝像機實現人數計數具有重要的研究價值。比如: 候車大廳中人群計數的結果,可優化公共交通的排程; 某區域中人數的急劇變化既可能會導致意外事件的發生, 又可能是意外事件發生的結果。公共場合中採用攝像機實現人群計數在智慧安防領域具有重要價值。因此, 人群計數(Crowd Counting)或者人群密度估計(Crowd Density Estimation)是計算機視覺和智慧視訊監控領域的重要研究內容。
人群計數的通常的方法大致可以分為三種:
1 )行人檢測 : 這種方法比較直接,在人群較稀疏的場景中,通過檢測視訊中的每一個行人,進而得到人群計數的結果,一般是用基於外觀和運動特徵的boosting,貝葉斯模型為基礎的分割,或整合的自頂向下和自底向上的處理,這種方法在人群擁擠情況下不大奏效,需要運用到基於部件模型(如DPM)的檢測器來克服人群擁擠遮擋的問題。
2)視覺特徵軌跡聚類
3)基於特徵的迴歸: 建立影象特徵和影象人數的迴歸模型, 通過測量影象特徵從而估計場景中的人數。由於擁擠情況下采用直接法容易受到遮擋等難點問題的影響,而間接法從人群的整體特徵出發,具有大規模人群計數的能力。
Related work
1、監控視訊中人群計數演算法
這邊就介紹下視覺特徵軌跡聚類和基於特徵的迴歸兩種方法。
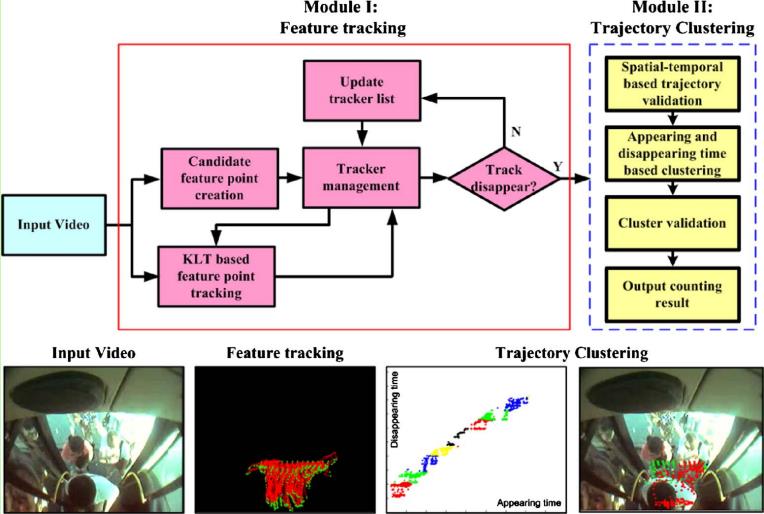
視覺特徵軌跡聚類一般是針對視訊影象序列,用KLT跟蹤器和聚類的方法,通過軌跡聚類得到的數目來估計人數。比如Clustering method for counting passengers getting in a bus with single camera[5]這篇文章是研究公交車車門視訊的乘客計數,採用的就是視覺特徵軌跡聚類方法。如下圖所示為該文章的單目攝像頭乘客計數系統流程圖。
基於特徵的迴歸一般分為以下3個步驟:
1)前景分割:前景(行人或人群)分割的目的是將人群從影象中分割出來便於後面的特徵提取,分割效能的好壞直接關係的最終的計數精度,因此這是限制傳統演算法效能的一個重要因素。常用的分割演算法有:光流法、混合動態紋理、小波分析 、背景差分等。
2)特徵提取:從分割得到的前景提取各種不同的底層特徵,常用的特徵有:人群面積和周長、邊緣資訊、紋理特徵、閔可夫斯基維度等。
3)人數迴歸:將提取到的特徵迴歸到影象中的人數。常用的迴歸方法有:線性迴歸、分段線性迴歸、脊迴歸、高斯過程迴歸等[1]。
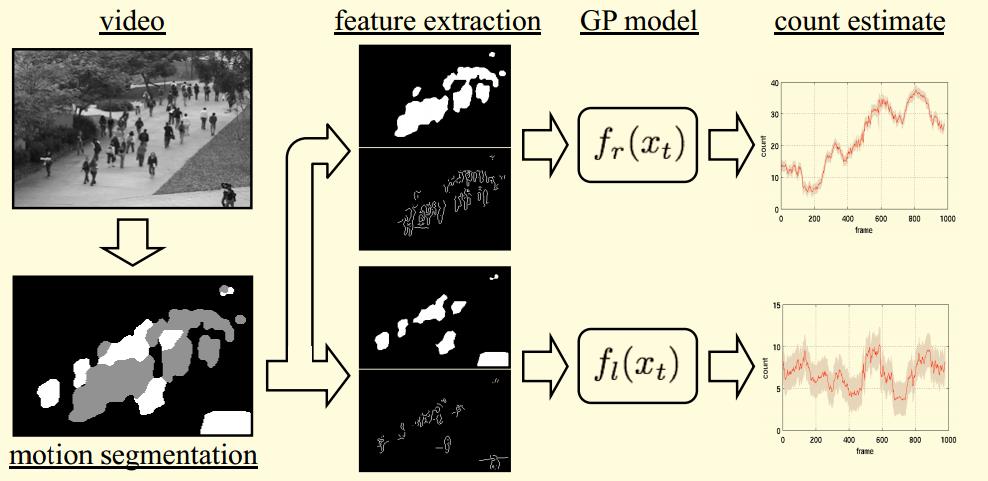
可以通過發表於CVPR08的Privacy Preserving Crowd Monitoring: Counting People without People Models or Tracking[2]來了解以下整個演算法流程。首先用動態紋理的方法分割出運動的人群,之後做視角歸一化,在歸一化後的人群塊上提取特徵,用高斯過程迴歸將提取的特徵迴歸到影象中人群數量。系統框圖如下:
2、單幅影象人群計數演算法
對於單幅影象而言沒有運動資訊,那麼人群分割就顯得非常困難,因此此類演算法一般直接從整張影象或者將影象分塊從其子區域提取特徵,然後再計算影象中人群數量。影象分塊可以理解為是一種離散化透視效果的方法。

3、基於深度學習的人群計數演算法
在監控視訊的人群計數演算法中,前景分割是不可或缺的步驟,然而前景分割本事就是一個比較困難的任務,演算法效能很大程度地受其影響。最近深度學習比較熱門,在各種傳統領域內取得了驚人的進展。卷積神經網路實現了端對端訓練,無需進行前景分割以及人工設計和提取特徵,經過多層卷積之後得到高層的語義特徵。CVPR2015的Cross-scene Crowd Counting via Deep Convolutional Neural Networks[3]提出了一個適用人群計數的深度卷積神經網路模型如下圖所示,相比於人工特徵對人群有更好的表述能力,交替迴歸該影象塊的人群密度和人群總數來實現人數估計。此外,提出了一種資料驅動的方法從訓練資料中選擇樣本來微調的預訓練好的CNN模型,以適應未知的應用場景。
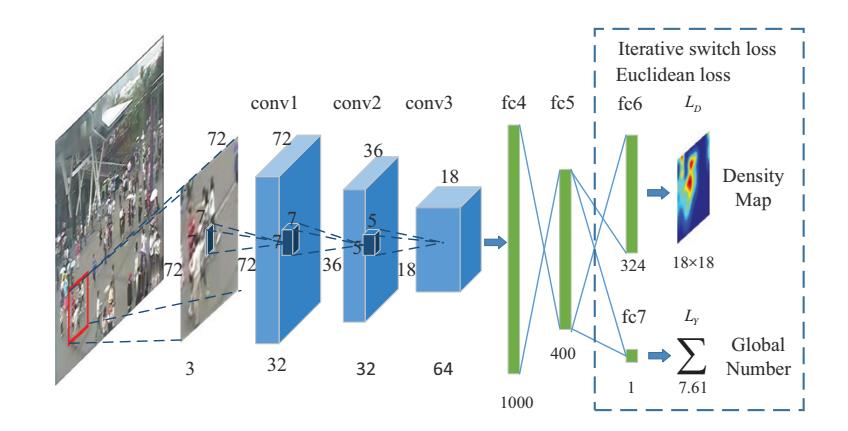
上圖中,conv1是32 7*7*3filters,conv2是32 7*7*32filters,conv3是64 5*5*32filters。conv1和conv2之後都是一個2*2的最大值pooling。
想了解更多人群計數的發展狀況請具體參考[1]以及閱讀相關代表性論文。下面的內容主要是CVPR2016的這篇人群計數論文的閱讀筆記。
Multi-column CNN
1、Contributions of this paper
當前階段人群計數的主要問題有以下幾點:
在大多數現有的工作中,前景分割是必不可少的,但前景分割是項艱鉅任務;人群的密度和分佈會有顯著變化,因此傳統的基於目標檢測的模型很難work well;需要一種有效的特徵來針對影象中人群規模可能有顯著變化的情況。
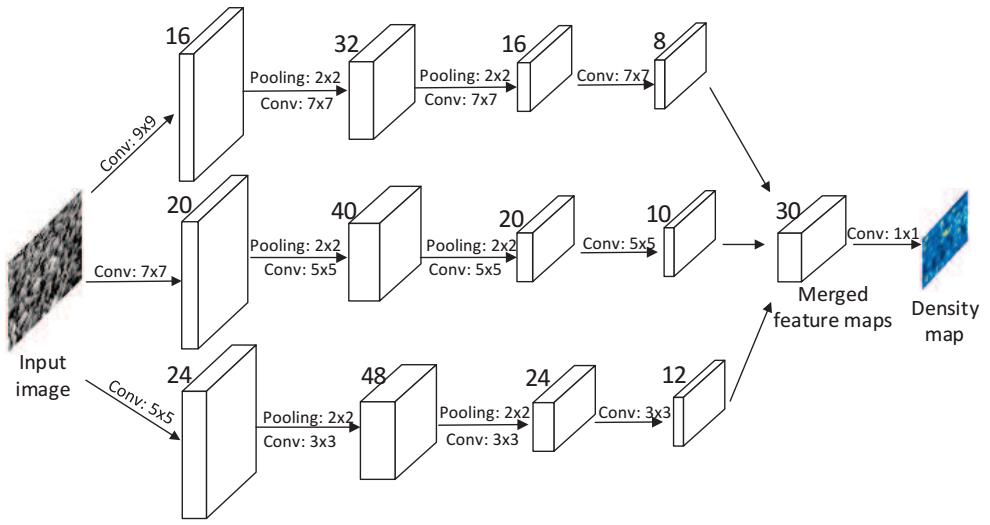
基於以上問題,作者提出了一個基於CNN的新框架用於任意單幅影象上的人群計數。MCNN包含了三列具有不同濾波器大小的卷積神經網路。所做貢獻如下:
1)多列架構的原因是:三列對應於不同大小的感受野(大,中,小),使每個列卷積神經網路的功能對由於透視或不同的影象解析度造成的人/頭大小變化是自適應的(因此,整體網路是強大的)。
2)用一個1*1濾波器的卷積層代替了完全連線的層,因此模型的輸入影象可以是任意大小的,避免了失真。網路的直接輸出是一個人群密度估計圖,從中可以得到的整體計數。
3)收集了一個新的資料集用於人群計數方法的評價。比現有的資料集包含更復雜的情況,能更好地測試方法效能,1198張圖,330,165精確標定的人頭。資料集分A和B兩個部分,A是從網際網路上隨機找的圖,B是上海的鬧市擷取圖,如圖5所示為A、B部分圖。

2、Density map based crowd counting
給定一張影象,用CNNs來估計人數,一般有兩種方案:一是輸入影象,輸出估計的人頭數目;二是輸出的時人群密度圖(每平方米多少人),然後再通過積分求總人數。作者支援第二種,有以下兩點原因:
1)密度圖保留更多的資訊。與人群的總數相比,密度圖給出了在給定影象中人群的空間分佈,這樣的分佈資訊在許多應用中是有用的。例如,如果一個小區域的密度比其他區域的密度高得多,它可能表明一些異常發生在那裡。
2)在通過一個CNN模型學習密度圖時,學習到的濾波器更適應於不同大小的頭,因此更適合於有透視效果顯著變化的任意輸入。所以這些濾波器具有更多的語義,提高了人群計數的準確性。
3、Density map via geometry-adaptive kernels
訓練資料中的人群密度的標定質量決定了CNN模型的效能。這裡介紹下如何將帶有標籤的人頭影象轉換為人群密度圖。
一幅有
為了使得密度圖能夠更好地與不同視角(不同人頭大小)且人群很密的影象對應起來,作者對傳統的基於高斯核的密度圖做了改進,提出了基於幾何適應高斯核的密度圖,由下式表示:

4、Multi-column CNN for density map estimation
MCNN主要是受到MDNNs[6] 在影象分類上取得成功的啟發而提出來的。MCNN網路的每一列並行的子網路深度相同,但是濾波器的大小不同(大,中,小),因此每一列子網路的感受野不同,能夠抓住不同大小人頭的特徵,最後將三列子網路的特徵圖做線性加權(由1x1的卷積完成)得到該影象的人群密度圖,類似模型融合的思想。採用了2*2的max-pooling和ReLU啟用函式。(注意,因為這裡用到了兩次max-pooling,所以需要先對訓練樣本也縮小到1/4,再生成對應的密度圖ground truth)
作者採用優化歐式損失的方式讓網路輸出的密度圖迴歸到標準的密度圖,損失函式如下式:
這裡的