
正則項:把控擬合方向的馬車伕
導語
在模型訓練過程中,我們通常會遇到過擬合與欠擬合問題。其中欠擬合是指模型未考慮足夠的樣本資訊而無法對真實情況精確建模的現象。比如一個小孩第一次見到天鵝後認為鴨子也是天鵝。反之,過擬合指的則是模型過度考慮樣本資訊而無法對真實情況精確建模的現象。我們還舉剛才的例子,小孩看到的有:天鵝有翅膀和黃色的嘴巴,天鵝脖子是長長的且有點曲度,天鵝的整個體型略大於鴨子,而且恰巧這些天鵝的羽毛全都是白色的。這導致他以後看到羽毛是黑色的天鵝就會認為那不是天鵝。誠然,這兩個問題都將導致模型的泛化能力弱,要如何才能防止這類問題的發生呢?對於欠擬合問題,通常只需增大訓練樣本數以及適量增加特徵即可解決;而對於過擬合問題,應對方法除了常規的特徵選擇與資料集擴增以外,我們通常還會給損失函式加上一個正則項進行權重抑制。那麼,這個正則項具體是什麼?又是如何起作用的呢?
把控擬合方向的馬車伕
機模型訓練,說到底都是引數估計問題。比如我們要擬合一條直線,模型是
目前正則項一共有三種:L0範數、L1範數和L2範數。這三種正則項接下來我將分別講解其作用和原理。
L0範數
L0範數表示向量中非零元素的個數
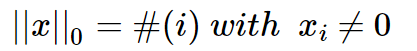
直觀上看,降低非零權重引數的個數可以很好地剔除區域性特徵(比如上面例子裡天鵝的羽毛顏色),實現特徵稀疏(原因可見上篇文章 ),使模型擁有較強的泛化能力。但是,由於L0範數很難求解,我們通常放棄這個方法。直觀上我是這樣理解這個問題得難解性的:L0的目標是特徵權重非0即1,也正因為它的取值非0即1,導致其本身無法計算梯度,使得在訓練過程中每一步迭代後得到的基本都是非0結果,從而無法最優化。
L1範數
L1範數表示向量中每個引數絕對值的和,其有個美稱叫“稀疏規則運算元”(Lasso regularization),數學形式如下:
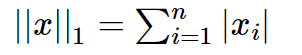
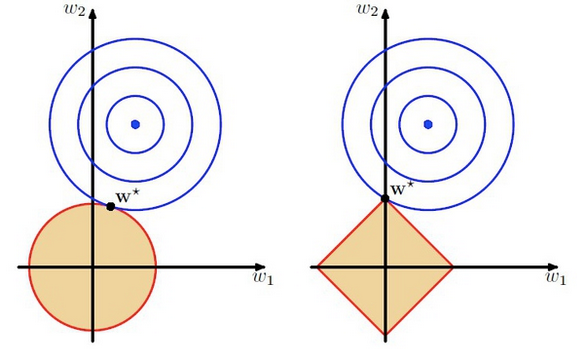
L1正則是如何實現特徵稀疏的呢?我們不妨舉個簡單的栗子:
L2範數
L2範數就是我們常說的歐氏距離,其也有個美稱,叫“嶺迴歸”(Ridge regularization),數學形式如下:
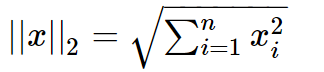
可知,L2範數越小,使得
結語
以上便是我對機器學習中正則項的理解。此外,防止過擬合的方法還有很多,諸如減少特徵、權值衰減、Early stopping、資料驗證、擴增資料集和Dropout等方法都大有學問,以後有機會再補上。在此感謝各位的耐心閱讀,不足之處希望多多指教。後續內容將會不定期奉上,歡迎大家關注小鬥公眾號 對半獨白!
