
為什麼正則化能夠降低過擬合
我們通過實驗發現正則化能幫助減少過擬合。這是令人高興的事,然而不幸的是,我們沒有明顯的證據證明為什麼正則化可以起到這個效果!一個大家經常說起的解釋是:在某種程度上,越小的權重複雜度越低,因此能夠更簡單且更有效地描繪資料,所以我們傾向於選擇這樣的權重。儘管這是個很簡短的解釋,卻也包含了一些疑點。讓我們來更加仔細地探討一下這個解釋。假設我們要對一個簡單的資料集建立模型:
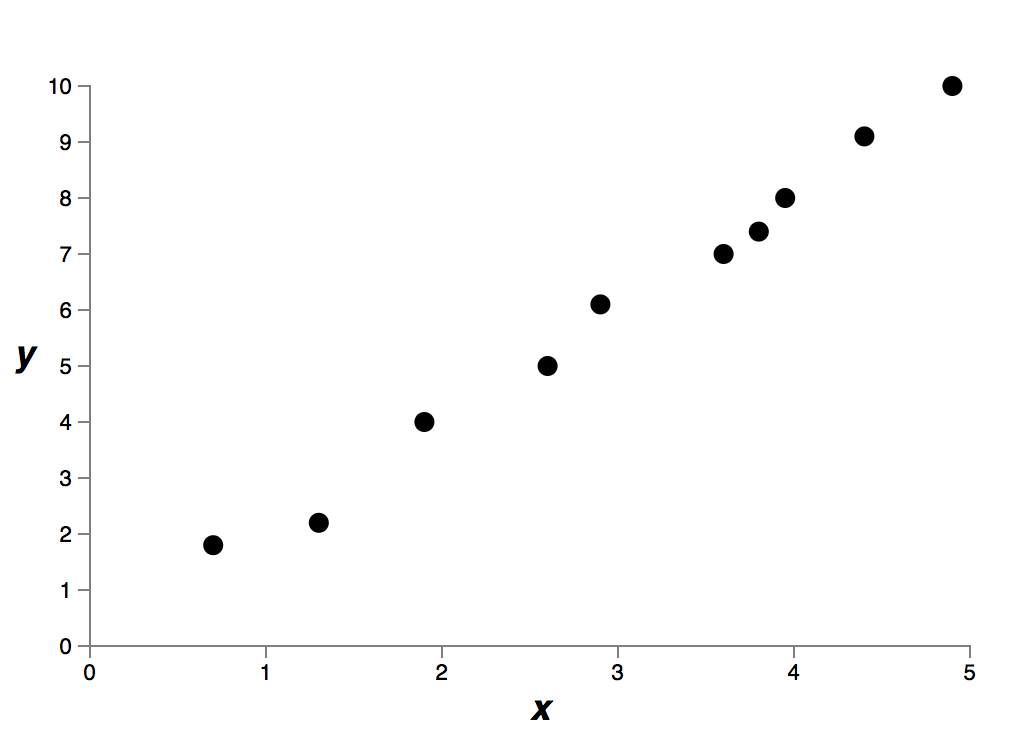
這個資料是現實世界某個問題提取得到的 x 和 y。我們的目標是構建一個模型,得到基於 x 的能預測 y 的函式。我們可以嘗試使用神經網路來構建模型,但是我將使用更簡單的方法:我將把 y 建模為關於 x 的多項式。我們將使用這種方法來代替神經網路,因為多項式模型十分透明。一旦我們理解了多項式的情況,我們就可以把它遷移到神經網路上。現在,在上圖中有十個點,這意味著我們可以找到一個 9
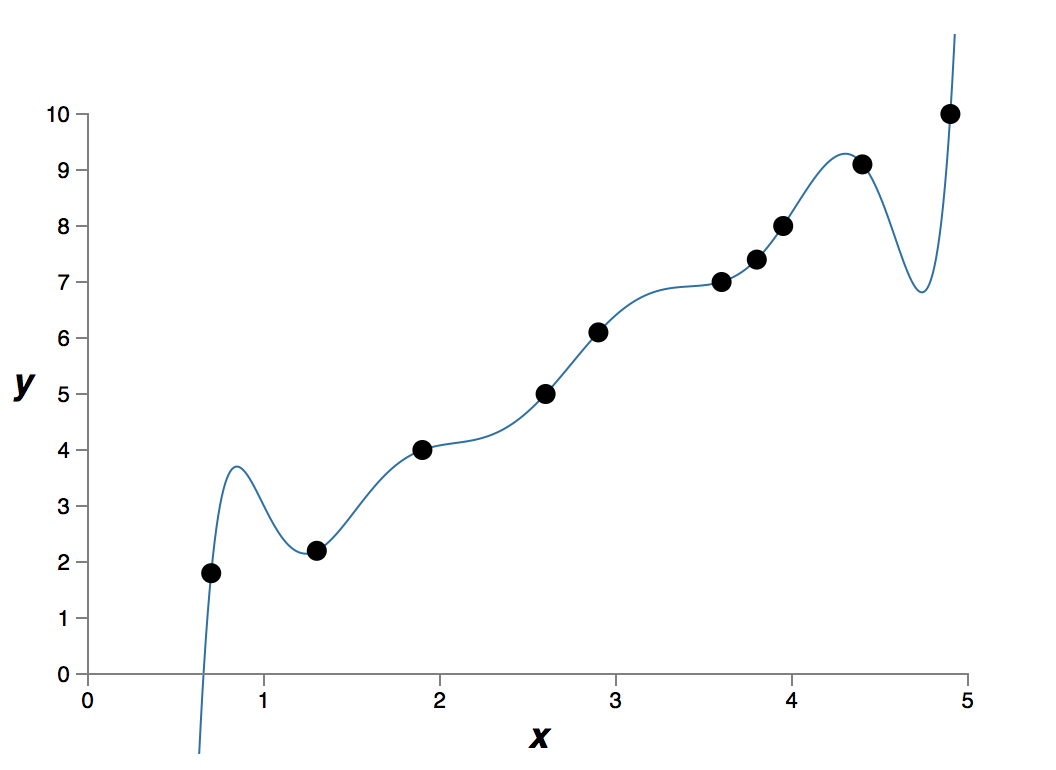
它精確擬合了資料。但是我們也可以使用線性模型 y=2x 來得到一個較好的擬合:
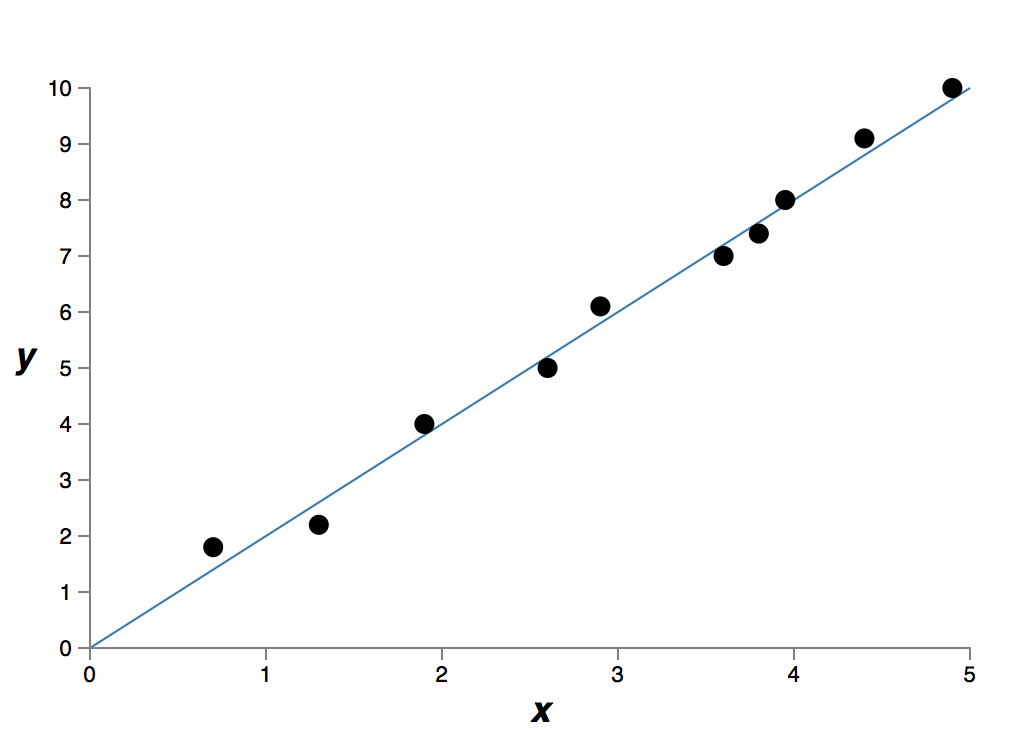
這兩個哪個才是更好的模型呢?哪個更貼近真實情況?另外哪個模型能更好地泛化該問題的其它資料呢?
這些問題很難回答。事實上,如果沒有足夠多關於現實情況的資訊時,我們很難回答任何一個問題。但是讓我們考慮兩種可能性:(1)9 次多項式事實上真正描述了現實情況,因此這個模型可以完美泛化;(2)正確的模型是 y=2x,但是實驗中有一些因為測量誤差引入的額外的噪聲,也因此這個模型沒有完美擬合。
確定這兩種可能(可能還有第三種可能存在)哪一個正確的是不能先驗
有一種看法是,在科學上,除非迫不得已,我們都應該用更簡單的解釋。當我們找到一個看起來能解釋很多資料點的簡單的模型的時候我們會忍不住大喊「找到啦!」。畢竟一個簡單的解釋的出現似乎不可能僅僅是因為巧合,我們猜測這個模型一定表達了關於這個現象的一些潛在真理。在我們的情況中,模型 y=2x+nois
我們來看看這種觀點對神經網路來說意味著什麼。設想我們的網路大部分都有較小的權重,正如在正則化網路中常出現的那樣。小權重意味著網路的行為不會因為我們隨意更改了一些輸入而改變太多。這使得它不容易學習到資料中區域性噪聲。可以把它想象成一種能使孤立的資料不會過多影響網路輸出的方法,相反地,一個正則化的網路會學習去響應一些經常出現在整個訓練集中的例項。與之相對的是,如果輸入有一些小的變化,一個擁有大權重的網路會大幅改變其行為來響應變化。因此一個未正則化的網路可以利用大權重來學習得到訓練集中包含了大量噪聲資訊的複雜模型。概括來說,正則化網路能夠限制在對訓練資料中常見資料構建出相對簡單的模型,並且對訓練資料中的各種各樣的噪聲有較好的抵抗能力。所以我們希望它能使我們的網路真正學習到問題中的現象的本質,並且能更好的進行泛化。
按照這種說法,你可能會對這種更傾向簡單模型的想法感到緊張。人們有時把這種想法稱作「奧卡姆剃刀」,並且就好像它是科學原理一樣,熱情地應用它。然而,它並不是一個普遍成立的科學原理。並不存在一個先驗的符合邏輯的理由傾向於簡單的模型,而不是複雜的模型。實際上,有時候更復雜的模型反而是正確的。
讓我介紹兩個正確結果是複雜模型的例子吧。在 1940 年代物理學家馬塞爾施恩(Marcel Schein)宣佈發現了一個新的自然粒子。他工作所在的通用電氣公司欣喜若狂並廣泛地宣傳了這一發現。但是物理學家漢斯貝特(Hans Bethe)卻懷疑這一發現。貝特拜訪了施恩,並且查看了新粒子的軌跡圖表。施恩向貝特一張一張地展示,但是貝特在每一張圖表上都發現了一些問題,這些問題暗示著資料應該被丟棄。最後,施恩向貝特展示了一張看起來不錯的圖表。貝特說它可能只是一個統計學上的巧合。施恩說「是的,但是這種統計學巧合的機率,即便是按照你自己的公式,也只有五分之一。」貝特說「但是我們已經看過了五個圖表。」最後,施恩說道「但是在我的圖表上,每一個較好的圖表,你都用不同的理論來解釋,然而我有一個假設可以解釋所有的圖表,就是它們是新粒子。」貝特迴應道「你我的學說的唯一區別在於你的是錯誤的而我的都是正確的。你簡單的解釋是錯的,而我複雜的解釋是正確的。」隨後的研究證實了大自然是贊同貝特的學說的,之後也沒有什麼施恩的粒子了1。
另一個例子是,1859 年天文學家勒維耶(Urbain Le Verrier)發現水星軌道沒有按照牛頓的引力理論,形成應有的形狀。它跟牛頓的理論有一個很小很小的偏差,一些當時被接受的解釋是,牛頓的理論或多或少是正確的,但是需要一些小小的調整。1916 年,愛因斯坦表明這一偏差可以很好地通過他的廣義相對論來解釋,這一理論從根本上不同於牛頓引力理論,並且基於更復雜的數學。儘管有額外的複雜性,但我們今天已經接受了愛因斯坦的解釋,而牛頓的引力理論,即便是調整過的形式,也是錯誤的。這某種程度上是因為我們現在知道了愛因斯坦的理論解釋了許多牛頓的理論難以解釋的現象。此外,更令人印象深刻的是,愛因斯坦的理論準確的預測了一些牛頓的理論完全沒有預測的現象。但這些令人印象深刻的優點在早期並不是顯而易見的。如果一個人僅僅是以樸素這一理由來判斷,那麼更好的理論就會是某種調整後的牛頓理論。
這些故事有三個意義。第一,判斷兩個解釋哪個才是真正的「簡單」是一個非常微妙的事情。第二,即便我們能做出這樣的判斷,簡單是一個必須非常謹慎使用的指標。第三,真正測試一個模型的不是簡單與否,更重要在於它在預測新的情況時表現如何。
謹慎來說,經驗表明正則化的神經網路通常要比未正則化的網路泛化能力更好。因此本書的剩餘部分我們將頻繁地使用正則化。我舉出上面的故事僅僅是為了幫助解釋為什麼還沒有人研究出一個完全令人信服的理論來解釋為什麼正則化會幫助網路泛化。事實上,研究人員仍然在研究正則化的不同方法,對比哪種效果更好,並且嘗試去解釋為什麼不同的方法有更好或更差的效果。所以你可以看到正則化是作為一種「雜牌軍」存在的。雖然它經常有幫助,但我們並沒有一套令人滿意的系統理解為什麼它有幫助,我們有的僅僅是沒有科學依據的經驗法則。
這存在一個更深層的問題,一個科學的核心問題。就是我們怎麼去泛化這一問題。正則化可以給我們一個計算魔法棒來幫助我們的網路更好的泛化,但是它並沒有給我們一個原則性的解釋泛化是如何工作的,也沒有告訴我們最好的方法是什麼。
這尤其令人煩惱,因為在日常生活中,我們人類有很好的泛化現象的能力。給一個孩子看幾張大象的圖片,他就能很快地學習並辨認出其它大象。當然,他們偶爾也會犯錯,也許會無法區分一個犀牛和一個大象,但是總體來說這個過程非常的準確。因此我們有一個系統——人的大腦——擁有大量的自由變數。對這個系統展示一張或幾張訓練圖片之後,這個系統就可以學習並泛化其它的圖片。我們的大腦在某種程度上,正則化得非常好!我們是怎麼做到的?目前我們還不知道。我預計未來幾年人工神經網路領域將開發出更強大的正則化技術,這些技術能使神經網路能更好地泛化,即使資料集非常小。
事實上,我們的網路已先天地泛化得很好。一個具有 100 個隱層神經元的網路有近 80,000 個引數。而我們的訓練資料中只有 50,000 個影象。這就好比試圖將一個 80,000 次多項式擬合為 50,000 個數據點。按理來說,我們的網路應該退化得非常嚴重。然而,正如我們所見,這樣一個網路事實上泛化得非常好。為什麼會是這樣?這不太好理解。據推測2說「多層網路中的梯度下降學習的過程中有一個『自我正則化』效應」。這是非常意外的好處,但是這也某種程度上讓人不安,因為我們不知道它是怎麼工作的。與此同時,我們將採用一些更務實的方法並儘可能地應用正則化。我們的神經網路將會因此變得更好。
最後,讓我說明一個之前沒有解釋到的細節:我們的 L2 正則化沒有約束偏置(biases)。當然,通過修改正則化過程來正則化偏置會很容易。但根據經驗,這樣做往往不能較明顯地改變結果。所以在一定程度上,是否正則化偏置僅僅是一個習慣問題。然而值得注意的是,有一個較大的偏置並不會使得神經元對它的輸入像有大權重那樣敏感。所以我們不用擔心較大的偏置會使我們的網路學習訓練資料中的噪聲。同時,允許大規模的偏置使我們的網路在效能上更為靈活——特別是較大的偏置使得神經元更容易飽和,這通常是我們期望的。由於這些原因,我們通常不對偏置做正則化。