python 中文文字分類
寫這篇博文用了很多時間和精力,如果這篇博文對你有幫助,希望您可以打賞給博主相國大人。哪怕只捐1毛錢,也是一種心意。通過這樣的方式,也可以培養整個行業的智慧財產權意識。我可以和您建立更多的聯絡,並且在相關領域提供給您更多的資料和技術支援。
賞金將用於拉薩兒童圖書公益募捐
手機掃一掃,即可:
目標讀者:初級入門學生。本文假定,你對python已經有了最基本的掌握。
如果你希望能夠對python有更多的掌握,可以參考博主的系列博文:
本文提供了python2.7和python3.6的程式碼,部落格內容的講解使用的是python2.7,在部落格後面給出的原始碼github連結中,我們給出了python2.7和python3.6的程式碼。其中github的master分支是python3.6,github的python2.7分支是python2.7.
一,中文文字分類流程:
- 預處理
- 中文分詞
- 結構化表示--構建詞向量空間
- 權重策略--TF-IDF
- 分類器
- 評價
二,具體細節
1,預處理
1.1得到訓練集語料庫
即已經分好類的文字資料(例如:語料庫裡是一系列txt文章,這些文章按照主題歸入到不同分類的目錄中,如 .\art\21.txt)將下載的語料庫解壓後,請自己修改檔名和路徑,例如路徑可以設定為 ./train_corpus/,
其下則是各個類別目錄如:./train_corpus/C3-Art,……,\train_corpus\C39-Sports
1.2得到測試語料庫
也是已經分好類的文字資料,與1.1型別相同,只是裡面的文件不同,用於檢測演算法的實際效果。測試預料可以從1.1中的訓練預料中隨機抽取,也可以下載獨立的測試語料庫,復旦中文文字分類語料庫測試集連結:
路徑修改參考1.1,例如可以設定為 ./test_corpus/
1.3其他
你可能希望從自己爬取到的網頁等內容中獲取新文字,用本節內容進行實際的文字分類,這時候,你可能需要將html標籤去除來獲取文字格式的文件,這裡提供一個基於python 和lxml的樣例程式碼:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
@version: python2.7.8
@author: XiangguoSun
@contact: [email protected] 2,中文分詞
2.1概述
第1小節預處理中的語料庫都是沒有分詞的原始語料(即連續的句子,而後面的工作需要我們把文字分為一個個單詞),現在需要對這些文字進行分詞,只有這樣,才能在 基於單詞的基礎上,對文件進行結構化表示。中文分詞有其特有的難點(相對於英文而言),最終完全解決中文分詞的演算法是基於概率圖模型的條件隨機場(CRF)。(可以參考博主的另一篇博文)
當然,在實際操作中,即使你對於相關演算法不甚瞭解,也不影響你的操作,中文分詞的工具有很多。但是比較著名的幾個都是基於java的,這裡推薦python的第三方庫jieba(所採用的演算法就是條件隨機場)。對於非專業文件綽綽有餘。如果你有強迫症,希望得到更高精度的分詞工具,可以使用開源專案Anjs(基於java),你可以將這個開源專案與python整合。
關於分詞庫的更多討論可以參考這篇文章:https://www.zhihu.com/question/19651613
你可以通過pip安裝jieba:開啟cmd,切換到目錄 .../python/scripts/,執行命令:pip install jieba
或者你也可以在整合開發平臺上安裝jieba,例如,如果你用的是pycharm,可以點選file-settings-project:xxx-Projuect Interpreter.其他平臺也都有類似的安裝方法。
2.2分詞操作
不要擔心下面的程式碼你看不懂,我會非常詳細的進行講解,確保python入門級別水平的人都可以看懂:2.2.1
首先講解jieba分詞使用方法(詳細的和更進一步的,可以參考這個連結):
jieba.cut 方法接受三個輸入引數: 需要分詞的字串;cut_all 引數用來控制是否採用全模式;HMM 引數用來控制是否使用 HMM 模型
jieba.cut_for_search 方法接受兩個引數:需要分詞的字串;是否使用 HMM 模型。該方法適合用於搜尋引擎構建倒排索引的分詞,粒度比較細
待分詞的字串可以是 unicode 或 UTF-8 字串、GBK 字串。注意:不建議直接輸入 GBK 字串,可能無法預料地錯誤解碼成 UTF-8
jieba.cut 以及 jieba.cut_for_search 返回的結構都是一個可迭代的 generator,可以使用 for 迴圈來獲得分詞後得到的每一個詞語(unicode),或者用
jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
jieba.Tokenizer(dictionary=DEFAULT_DICT) 新建自定義分詞器,可用於同時使用不同詞典。jieba.dt 為預設分詞器,所有全域性分詞相關函式都是該分詞器的對映。import jieba
seg_list = jieba.cut("我來到北京清華大學", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我來到北京清華大學", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精確模式
seg_list = jieba.cut("他來到了網易杭研大廈") # 預設是精確模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明碩士畢業於中國科學院計算所,後在日本京都大學深造") # 搜尋引擎模式
print(", ".join(seg_list))輸出:
【全模式】: 我/ 來到/ 北京/ 清華/ 清華大學/ 華大/ 大學
【精確模式】: 我/ 來到/ 北京/ 清華大學
【新詞識別】:他, 來到, 了, 網易, 杭研, 大廈 (此處,“杭研”並沒有在詞典中,但是也被Viterbi演算法識別出來了)
【搜尋引擎模式】: 小明, 碩士, 畢業, 於, 中國, 科學, 學院, 科學院, 中國科學院, 計算, 計算所, 後, 在, 日本, 京都, 大學, 日本京都大接下來,我們將要通過python程式設計,來將1.1節中的 ./train_corpus/原始訓練語料庫和1.2節中的./test_corpus/原始測試語料庫進行分詞,分詞後儲存的路徑可以設定為
./train_corpus_seg/和./test_corpus_seg/
程式碼如下,思路很簡單,就是遍歷所有的txt文字,然後將每個文字依次進行分詞。你唯一需要注意的就是寫好自己的路徑,不要出錯。下面的程式碼已經給出了非常詳盡的解釋,初學者也可以看懂。如果你還沒有明白,或者在執行中出現問題(其實根本不可能出現問題,我寫的程式碼,質量很高的。。。),都可以發郵件給我,郵件地址在程式碼中,或者在博文下方評論中給出。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
@version: python2.7.8
@author: XiangguoSun
@contact: [email protected]
@file: corpus_segment.py
@time: 2017/2/5 15:28
@software: PyCharm
"""
import sys
import os
import jieba
# 配置utf-8輸出環境
reload(sys)
sys.setdefaultencoding('utf-8')
# 儲存至檔案
def savefile(savepath, content):
with open(savepath, "wb") as fp:
fp.write(content)
'''
上面兩行是python2.6以上版本增加的語法,省略了繁瑣的檔案close和try操作
2.5版本需要from __future__ import with_statement
新手可以參考這個連結來學習http://zhoutall.com/archives/325
'''
# 讀取檔案
def readfile(path):
with open(path, "rb") as fp:
content = fp.read()
return content
def corpus_segment(corpus_path, seg_path):
'''
corpus_path是未分詞語料庫路徑
seg_path是分詞後語料庫儲存路徑
'''
catelist = os.listdir(corpus_path) # 獲取corpus_path下的所有子目錄
'''
其中子目錄的名字就是類別名,例如:
train_corpus/art/21.txt中,'train_corpus/'是corpus_path,'art'是catelist中的一個成員
'''
# 獲取每個目錄(類別)下所有的檔案
for mydir in catelist:
'''
這裡mydir就是train_corpus/art/21.txt中的art(即catelist中的一個類別)
'''
class_path = corpus_path + mydir + "/" # 拼出分類子目錄的路徑如:train_corpus/art/
seg_dir = seg_path + mydir + "/" # 拼出分詞後存貯的對應目錄路徑如:train_corpus_seg/art/
if not os.path.exists(seg_dir): # 是否存在分詞目錄,如果沒有則建立該目錄
os.makedirs(seg_dir)
file_list = os.listdir(class_path) # 獲取未分詞語料庫中某一類別中的所有文字
'''
train_corpus/art/中的
21.txt,
22.txt,
23.txt
...
file_list=['21.txt','22.txt',...]
'''
for file_path in file_list: # 遍歷類別目錄下的所有檔案
fullname = class_path + file_path # 拼出檔名全路徑如:train_corpus/art/21.txt
content = readfile(fullname) # 讀取檔案內容
'''此時,content裡面存貯的是原文字的所有字元,例如多餘的空格、空行、回車等等,
接下來,我們需要把這些無關痛癢的字元統統去掉,變成只有標點符號做間隔的緊湊的文字內容
'''
content = content.replace("\r\n", "") # 刪除換行
content = content.replace(" ", "")#刪除空行、多餘的空格
content_seg = jieba.cut(content) # 為檔案內容分詞
savefile(seg_dir + file_path, " ".join(content_seg)) # 將處理後的檔案儲存到分詞後語料目錄
print "中文語料分詞結束!!!"
'''
如果你對if __name__=="__main__":這句不懂,可以參考下面的文章
http://imoyao.lofter.com/post/3492bc_bd0c4ce
簡單來說如果其他python檔案呼叫這個檔案的函式,或者把這個檔案作為模組
匯入到你的工程中時,那麼下面的程式碼將不會被執行,而如果單獨在命令列中
執行這個檔案,或者在IDE(如pycharm)中執行這個檔案時候,下面的程式碼才會執行。
即,這部分程式碼相當於一個功能測試。
如果你還沒懂,建議你放棄IT這個行業。
'''
if __name__=="__main__":
#對訓練集進行分詞
corpus_path = "./train_corpus/" # 未分詞分類語料庫路徑
seg_path = "./train_corpus_seg/" # 分詞後分類語料庫路徑
corpus_segment(corpus_path,seg_path)
#對測試集進行分詞
corpus_path = "./test_corpus/" # 未分詞分類語料庫路徑
seg_path = "./test_corpus_seg/" # 分詞後分類語料庫路徑
corpus_segment(corpus_path,seg_path)截止目前,我們已經得到了分詞後的訓練集語料庫和測試集語料庫,下面我們要把這兩個資料集表示為變數,從而為下面程式呼叫提供服務。我們採用的是Scikit-Learn庫中的Bunch資料結構來表示這兩個資料集。你或許對於Scikit-Learn和Bunch並不是特別瞭解,而官方的技術文件有兩千多頁你可能也沒耐心去看,好在你們有相國大人。下面我們 以這兩個資料集為背景,對Bunch做一個非常通俗的講解,肯定會讓你一下子就明白。
首先來看看Bunch:
Bunch這玩意兒,其實就相當於python中的字典。你往裡面傳什麼,它就存什麼。
好了,解釋完了。
是不是很簡單?
接下來,讓我們看看的我們的資料集(訓練集)有哪些資訊:
1,類別,也就是所有分類類別的集合,即我們./train_corpus_seg/和./test_corpus_seg/下的所有子目錄的名字。我們在這裡不妨把它叫做target_name(這是一個列表)
2,文字檔名。例如./train_corpus_seg/art/21.txt,我們可以把所有檔名集合在一起做一個列表,叫做filenames
3,文字標籤(就是文字的類別),不妨叫做label(與2中的filenames一一對應)
例如2中的文字“21.txt”在./train_corpus_seg/art/目錄下,則它的標籤就是art。
文字標籤與1中的類別區別在於:文字標籤集合裡面的元素就是1中類別,而文字標籤集合的元素是可以重複的,因為./train_corpus_seg/art/目錄下有好多文字,不是嗎?相應的,1中的類別集合元素顯然都是獨一無二的類別。
4,文字內容(contens)。
上一步程式碼我們已經成功的把文字內容進行了分詞,並且去除掉了所有的換行,得到的其實就是一行詞袋。
那麼,用Bunch表示,就是:
from sklearn.datasets.base import Bunch
bunch = Bunch(target_name=[],label=[],filenames=[],contents=[])
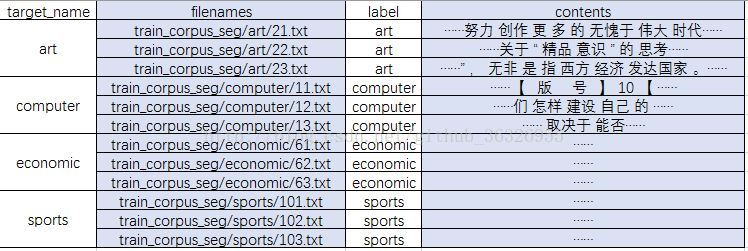
我們在Bunch物件裡面建立了有4個成員:
target_name:是一個list,存放的是整個資料集的類別集合。
label:是一個list,存放的是所有文字的標籤。
filenames:是一個list,存放的是所有文字檔案的名字。
contents:是一個list,分詞後文本檔案(一個文字檔案只有一行)
如果你還沒有明白,看一下下面這個圖,你總該明白了:
Bunch:
下面,我們將文字檔案轉為Bunch類形:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
@version: python2.7.8
@author: XiangguoSun
@contact: [email protected]
@file: corpus2Bunch.py
@time: 2017/2/7 7:41
@software: PyCharm
"""
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import os#python內建的包,用於進行檔案目錄操作,我們將會用到os.listdir函式
import cPickle as pickle#匯入cPickle包並且取一個別名pickle
'''
事實上python中還有一個也叫作pickle的包,與這裡的名字相同了,無所謂
關於cPickle與pickle,請參考博主另一篇博文:
python核心模組之pickle和cPickle講解
http://blog.csdn.net/github_36326955/article/details/54882506
本檔案程式碼下面會用到cPickle中的函式cPickle.dump
'''
from sklearn.datasets.base import Bunch
#這個您無需做過多瞭解,您只需要記住以後匯入Bunch資料結構就像這樣就可以了。
#今後的博文會對sklearn做更有針對性的講解
def _readfile(path):
'''讀取檔案'''
#函式名前面帶一個_,是標識私有函式
# 僅僅用於標明而已,不起什麼作用,
# 外面想呼叫還是可以呼叫,
# 只是增強了程式的可讀性
with open(path, "rb") as fp:#with as句法前面的程式碼已經多次介紹過,今後不再註釋
content = fp.read()
return content
def corpus2Bunch(wordbag_path,seg_path):
catelist = os.listdir(seg_path)# 獲取seg_path下的所有子目錄,也就是分類資訊
#建立一個Bunch例項
bunch = Bunch(target_name=[], label=[], filenames=[], contents=[])
bunch.target_name.extend(catelist)
'''
extend(addlist)是python list中的函式,意思是用新的list(addlist)去擴充
原來的list
'''
# 獲取每個目錄下所有的檔案
for mydir in catelist:
class_path = seg_path + mydir + "/" # 拼出分類子目錄的路徑
file_list = os.listdir(class_path) # 獲取class_path下的所有檔案
for file_path in file_list: # 遍歷類別目錄下檔案
fullname = class_path + file_path # 拼出檔名全路徑
bunch.label.append(mydir)
bunch.filenames.append(fullname)
bunch.contents.append(_readfile(fullname)) # 讀取檔案內容
'''append(element)是python list中的函式,意思是向原來的list中新增element,注意與extend()函式的區別'''
# 將bunch儲存到wordbag_path路徑中
with open(wordbag_path, "wb") as file_obj:
pickle.dump(bunch, file_obj)
print "構建文字物件結束!!!"
if __name__ == "__main__":#這個語句前面的程式碼已經介紹過,今後不再註釋
#對訓練集進行Bunch化操作:
wordbag_path = "train_word_bag/train_set.dat" # Bunch儲存路徑
seg_path = "train_corpus_seg/" # 分詞後分類語料庫路徑
corpus2Bunch(wordbag_path, seg_path)
# 對測試集進行Bunch化操作:
wordbag_path = "test_word_bag/test_set.dat" # Bunch儲存路徑
seg_path = "test_corpus_seg/" # 分詞後分類語料庫路徑
corpus2Bunch(wordbag_path, seg_path)3,結構化表示--向量空間模型
在第2節中,我們對原始資料集進行了分詞處理,並且通過繫結為Bunch資料型別,實現了資料集的變量表示。也許你對於什麼是詞向量並沒有清晰的概念,這裡有一篇非常棒的文章《Deep Learning in NLP (一)詞向量和語言模型》,簡單來講,詞向量就是詞向量空間裡面的一個向量。
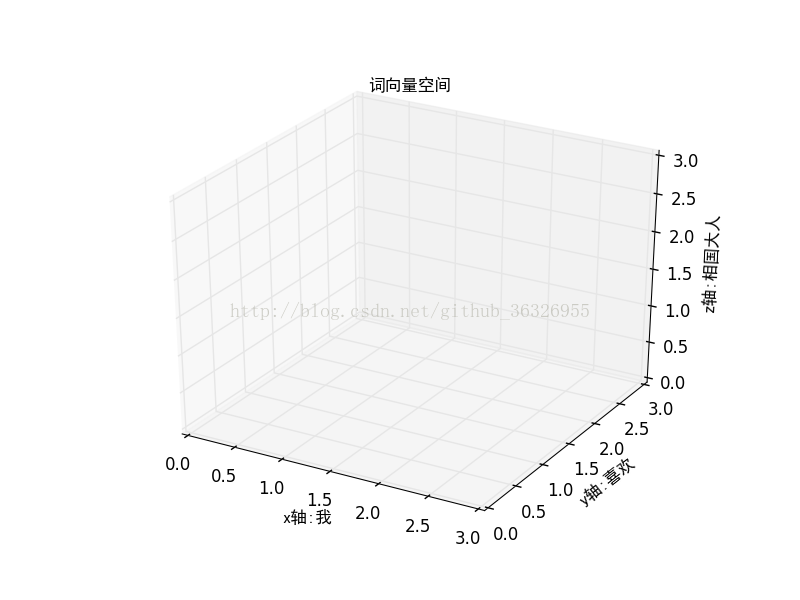
你可以類比為三維空間裡面的一個向量,例如:
如果我們規定詞向量空間為:(我,喜歡,相國大人),這相當於三維空間裡面的(x,y,z)只不過這裡的x,y,z的名字變成了“我”,“喜歡”,“相國大人”
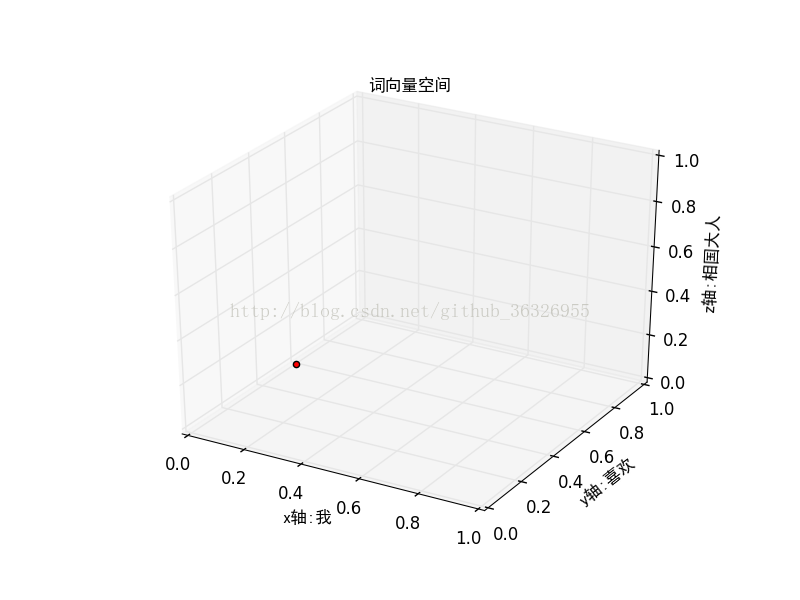
現在有一個詞向量是:我喜歡 喜歡相國大人
表示在詞向量空間中就變為:(1,2,1),歸一化後可以表示為:(0.166666666667 0.333333333333 0.166666666667)表示在剛才的詞向量空間中就是這樣:
接下來我們要做的,就是把所有這些詞統一到同一個詞向量空間中。
為了節省空間,我們首先將訓練集中每個文字中一些垃圾詞彙去掉。所謂的垃圾詞彙,就是指意義模糊的詞,或者一些語氣助詞,標點符號等等,通常他們對文字起不了分類特徵的意義。這些垃圾詞彙我們稱之為停用詞。把所有停用詞集合起來構成一張停用詞表格,這樣,以後我們處理文字時,就可以從這個根據表格,過濾掉文字中的一些垃圾詞彙了。
存放在這裡路徑中:train_word_bag/hlt_stop_words.txt
下面的程式,目的就是要將訓練集所有文字檔案統一到同一個詞向量空間中。
下面的一節主要目標是希望得到兩個東西:
1.詞典(單詞和單詞對應的序號)
2.權重矩陣tdm,其中,權重矩陣是一個二維矩陣,tdm[i][j]表示,第j個詞(即詞典中的序號)在第i個類別中的IF-IDF值(下文有講解)。
事實上,tdm的每一列都是一個單詞在各個類別中的全職。我們把這每一列當作詞向量。
4,權重策略--TF-IDF
什麼是TF-IDF?今後有精力我會在這裡更新補充,現在,先給你推薦一篇非常棒的文章《使用scikit-learn工具計算文字TF-IDF值》
下面,我們假定你已經對TF-IDF有了最基本的瞭解。請你動動你的小腦袋瓜想一想,我們把訓練集文字轉換成了一個TF-IDF詞向量空間,姑且叫它為A空間吧。那麼我們還有測試集資料,我們以後實際運用時,還會有新的資料,這些資料顯然也要轉到詞向量空間,那麼應該和A空間為同一個空間嗎?
是的。
即使測試集出現了新的詞彙(不是停用詞),即使新的文字資料有新的詞彙,只要它不是訓練集生成的TF-IDF詞向量空間中的詞,我們就都不予考慮。這就實現了所有文字詞向量空間“大一統”,也只有這樣,大家才在同一個世界裡。才能進行下一步的研究。
下面的程式就是要將訓練集所有文字檔案(詞向量)統一到同一個TF-IDF詞向量空間中(或者叫做用TF-IDF演算法計算權重的有權詞向量空間)。這個詞向量空間最終存放在train_word_bag/tfdifspace.dat中。
這段程式碼你可能有點看不懂,因為我估計你可能比較懶,還沒看過TF-IDF(儘管我剛才已經給你推薦那篇文章了)。你只需要明白,它把一大坨訓練集資料成功的構建了一個TF-IDF詞向量空間,空間的各個詞都是出自這個訓練集(去掉了停用詞)中,各個詞的權值也都一併儲存了下來,叫做權重矩陣。
需要注意的是,你要明白,權重矩陣是一個二維矩陣,a[i][j]表示,第j個詞在第i個類別中的IF-IDF值(看到這裡,我估計你壓根就沒去看那篇文章,所以你可能到現在也不知道 這是個啥玩意兒。。。)
請記住權重矩陣這個詞,程式碼解釋中我會用到。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
@version: python2.7.8
@author: XiangguoSun
@contact: [email protected]
@file: vector_space.py
@time: 2017/2/7 17:29
@software: PyCharm
"""
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
# 引入Bunch類
from sklearn.datasets.base import Bunch
import cPickle as pickle#之前已經說過,不再贅述
from sklearn.feature_extraction.text import TfidfVectorizer#這個東西下面會講
# 讀取檔案
def _readfile(path):
with open(path, "rb") as fp:
content = fp.read()
return content
# 讀取bunch物件
def _readbunchobj(path):
with open(path, "rb") as file_obj:
bunch = pickle.load(file_obj)
return bunch
# 寫入bunch物件
def _writebunchobj(path, bunchobj):
with open(path, "wb") as file_obj:
pickle.dump(bunchobj, file_obj)
#這個函式用於建立TF-IDF詞向量空間
def vector_space(stopword_path,bunch_path,space_path):
stpwrdlst = _readfile(stopword_path).splitlines()#讀取停用詞
bunch = _readbunchobj(bunch_path)#匯入分詞後的詞向量bunch物件
#構建tf-idf詞向量空間物件
tfidfspace = Bunch(target_name=bunch.target_name, label=bunch.label, filenames=bunch.filenames, tdm=[], vocabulary={})
'''
在前面幾節中,我們已經介紹了Bunch。
target_name,label和filenames這幾個成員都是我們自己定義的玩意兒,前面已經講過不再贅述。
下面我們講一下tdm和vocabulary(這倆玩意兒也都是我們自己建立的):
tdm存放的是計算後得到的TF-IDF權重矩陣。請記住,我們後面分類器需要的東西,其實就是訓練集的tdm和標籤label,因此這個成員是
很重要的。
vocabulary是詞典索引,例如
vocabulary={"我":0,"喜歡":1,"相國大人":2},這裡的數字對應的就是tdm矩陣的列
我們現在就是要構建一個詞向量空間,因此在初始時刻,這個tdm和vocabulary自然都是空的。如果你在這一步將vocabulary賦值了一個
自定義的內容,那麼,你是傻逼。
'''
'''
與下面這2行程式碼等價的程式碼是:
vectorizer=CountVectorizer()#構建一個計算詞頻(TF)的玩意兒,當然這裡面不只是可以做這些
transformer=TfidfTransformer()#構建一個計算TF-IDF的玩意兒
tfidf=transformer.fit_transform(vectorizer.fit_transform(corpus))
#vectorizer.fit_transform(corpus)將文字corpus輸入,得到詞頻矩陣
#將這個矩陣作為輸入,用transformer.fit_transform(詞頻矩陣)得到TF-IDF權重矩陣
看名字你也應該知道:
Tfidf-Transformer + Count-Vectorizer = Tfidf-Vectorizer
下面的程式碼一步到位,把上面的兩個步驟一次性全部完成
值得注意的是,CountVectorizer()和TfidfVectorizer()裡面都有一個成員叫做vocabulary_(後面帶一個下劃線)
這個成員的意義,與我們之前在構建Bunch物件時提到的自己定義的那個vocabulary的意思是一樣的,只不過一個是私有成員,一個是外部輸入,原則上應該保持一致。顯然,我們在第45行中建立tfidfspace中定義的vocabulary就應該被賦值為這個vocabulary_
'''
#構建一個快樂地一步到位的玩意兒,專業一點兒叫做:使用TfidfVectorizer初始化向量空間模型
#這裡面有TF-IDF權重矩陣還有我們要的詞向量空間座標軸資訊vocabulary_
vectorizer = TfidfVectorizer(stop_words=stpwrdlst, sublinear_tf=True, max_df=0.5)
'''
關於引數,你只需要瞭解這麼幾個就可以了:
stop_words:
傳入停用詞,以後我們獲得vocabulary_的時候,就會根據文字資訊去掉停用詞得到
vocabulary:
之前說過,不再解釋。
sublinear_tf:
計算tf值採用亞線性策略。比如,我們以前算tf是詞頻,現在用1+log(tf)來充當詞頻。
smooth_idf:
計算idf的時候log(分子/分母)分母有可能是0,smooth_idf會採用log(分子/(1+分母))的方式解決。預設已經開啟,無需關心。
norm:
歸一化,我們計算TF-IDF的時候,是用TF*IDF,TF可以是歸一化的,也可以是沒有歸一化的,一般都是採用歸一化的方法,預設開啟.
max_df:
有些詞,他們的文件頻率太高了(一個詞如果每篇文件都出現,那還有必要用它來區分文字類別嗎?當然不用了呀),所以,我們可以
設定一個閾值,比如float型別0.5(取值範圍[0.0,1.0]),表示這個詞如果在整個資料集中超過50%的文字都出現了,那麼我們也把它列
為臨時停用詞。當然你也可以設定為int型,例如max_df=10,表示這個詞如果在整個資料集中超過10的文字都出現了,那麼我們也把它列
為臨時停用詞。
min_df:
與max_df相反,雖然文件頻率越低,似乎越能區分文字,可是如果太低,例如10000篇文字中只有1篇文字出現過這個詞,僅僅因為這1篇
文字,就增加了詞向量空間的維度,太不划算。
當然,max_df和min_df在給定vocabulary引數時,就失效了。
'''
#此時tdm裡面儲存的就是if-idf權值矩陣
tfidfspace.tdm = vectorizer.fit_transform(bunch.contents)
tfidfspace.vocabulary = vectorizer.vocabulary_
_writebunchobj(space_path, tfidfspace)
print "if-idf詞向量空間例項建立成功!!!"
if __name__ == '__main__':
stopword_path = "train_word_bag/hlt_stop_words.txt"#停用詞表的路徑
bunch_path = "train_word_bag/train_set.dat" #匯入訓練集Bunch的路徑
space_path = "train_word_bag/tfdifspace.dat" # 詞向量空間儲存路徑
vector_space(stopword_path,bunch_path,space_path)上面的程式碼執行之後,會將訓練集資料轉換為TF-IDF詞向量空間中的例項,儲存在train_word_bag/tfdifspace.dat中,具體來說,這個檔案裡面有兩個我們感興趣的東西,一個是vocabulary,即詞向量空間座標,一個是tdm,即訓練集的TF-IDF權重矩陣。
接下來,我們要開始第5步的操作,設計分類器,用訓練集訓練,用測試集測試。在做這些工作之前,你一定要記住,首先要把測試資料也對映到上面這個TF-IDF詞向量空間中,也就是說,測試集和訓練集處在同一個詞向量空間(vocabulary相同),只不過測試集有自己的tdm,與訓練集(train_word_bag/tfdifspace.dat)中的tdm不同而已。
同一個世界,同一個夢想。
至於說怎麼弄,請看下節。
5,分類器
這裡我們採用的是樸素貝葉斯分類器,今後我們會詳細講解它。
現在,你即便不知道這是個啥玩意兒,也一點不會影響你,這個分類器我們有封裝好了的函式,MultinomialNB,這玩意兒獲取訓練集的權重矩陣和標籤,進行訓練,然後獲取測試集的權重矩陣,進行預測(給出預測標籤)。
下面我們開始動手實踐吧!
首先,我們要把測試資料也對映到第4節中的那個TF-IDF詞向量空間上:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
@version: python2.7.8
@author: XiangguoSun
@contact: [email protected]
@file: test.py
@time: 2017/2/8 11:39
@software: PyCharm
"""
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
# 引入Bunch類
from sklearn.datasets.base import Bunch
import cPickle as pickle
from sklearn.feature_extraction.text import TfidfVectorizer
def _readfile(path):
with open(path, "rb") as fp:
content = fp.read()
return content
def _readbunchobj(path):
with open(path, "rb") as file_obj:
bunch = pickle.load(file_obj)
return bunch
def _writebunchobj(path, bunchobj):
with open(path, "wb") as file_obj:
pickle.dump(bunchobj, file_obj)
def vector_space(stopword_path,bunch_path,space_path,train_tfidf_path):
stpwrdlst = _readfile(stopword_path).splitlines()
bunch = _readbunchobj(bunch_path)
tfidfspace = Bunch(target_name=bunch.target_name, label=bunch.label, filenames=bunch.filenames, tdm=[], vocabulary={})
#匯入訓練集的TF-IDF詞向量空間
trainbunch = _readbunchobj(train_tfidf_path)
tfidfspace.vocabulary = trainbunch.vocabulary
vectorizer = TfidfVectorizer(stop_words=stpwrdlst, sublinear_tf=True, max_df=0.5,vocabulary=trainbunch.vocabulary)
tfidfspace.tdm = vectorizer.fit_transform(bunch.contents)
_writebunchobj(space_path, tfidfspace)
print "if-idf詞向量空間例項建立成功!!!"
if __name__ == '__main__':
stopword_path = "train_word_bag/hlt_stop_words.txt"#停用詞表的路徑
bunch_path = "test_word_bag/test_set.dat" # 詞向量空間儲存路徑
space_path = "test_word_bag/testspace.dat" # TF-IDF詞向量空間儲存路徑
train_tfidf_path="train_word_bag/tfdifspace.dat"
vector_space(stopword_path,bunch_path,space_path,train_tfidf_path)你已經發現了,這段程式碼與第4節幾乎一模一樣,唯一不同的就是在第39~41行中,我們匯入了第4節中訓練集的IF-IDF詞向量空間,並且第41行將訓練集的vocabulary賦值給測試集的vocabulary,第43行增加了入口引數vocabulary,原因在上一節中都已經說明,不再贅述。
考慮到第4節和剛才的程式碼幾乎完全一樣,因此我們可以將這兩個程式碼檔案統一為一個:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
@version: python2.7.8
@author: XiangguoSun
@contact: [email protected]
@file: TFIDF_space.py
@time: 2017/2/8 11:39
@software: PyCharm
"""
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from sklearn.datasets.base import Bunch
import cPickle as pickle
from sklearn.feature_extraction.text import TfidfVectorizer
def _readfile(path):
with open(path, "rb") as fp:
content = fp.read()
return content
def _readbunchobj(path):
with open(path, "rb") as file_obj:
bunch = pickle.load(file_obj)
return bunch
def _writebunchobj(path, bunchobj):
with open(path, "wb") as file_obj:
pickle.dump(bunchobj, file_obj)
def vector_space(stopword_path,bunch_path,space_path,train_tfidf_path=None):
stpwrdlst = _readfile(stopword_path).splitlines()
bunch = _readbunchobj(bunch_path)
tfidfspace = Bunch(target_name=bunch.target_name, label=bunch.label, filenames=bunch.filenames, tdm=[], vocabulary={})
if train_tfidf_path is not None:
trainbunch = _readbunchobj(train_tfidf_path)
tfidfspace.vocabulary = trainbunch.vocabulary
vectorizer = TfidfVectorizer(stop_words=stpwrdlst, sublinear_tf=True, max_df=0.5,vocabulary=trainbunch.vocabulary)
tfidfspace.tdm = vectorizer.fit_transform(bunch.contents)
else:
vectorizer = TfidfVectorizer(stop_words=stpwrdlst, sublinear_tf=True, max_df=0.5)
tfidfspace.tdm = vectorizer.fit_transform(bunch.contents)
tfidfspace.vocabulary = vectorizer.vocabulary_
_writebunchobj(space_path, tfidfspace)
print "if-idf詞向量空間例項建立成功!!!"
if __name__ == '__main__':
stopword_path = "train_word_bag/hlt_stop_words.txt"
bunch_path = "train_word_bag/train_set.dat"
space_path = "train_word_bag/tfdifspace.dat"
vector_space(stopword_path,bunch_path,space_path)
bunch_path = "test_word_bag/test_set.dat"
space_path = "test_word_bag/testspace.dat"
train_tfidf_path="train_word_bag/tfdifspace.dat"
vector_space(stopword_path,bunch_path,space_path,train_tfidf_path)哇哦,你好棒!現在連註釋都不用,就可以看懂程式碼了。。。
對測試集進行了上述處理後,接下來的步驟,變得如此輕盈和優雅。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
@version: python2.7.8
@author: XiangguoSun
@contact: [email protected]
@file: NBayes_Predict.py
@time: 2017/2/8 12:21
@software: PyCharm
"""
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import cPickle as pickle
from sklearn.naive_bayes import MultinomialNB # 匯入多項式貝葉斯演算法
# 讀取bunch物件
def _readbunchobj(path):
with open(path, "rb") as file_obj:
bunch = pickle.load(file_obj)
return bunch
# 匯入訓練集
trainpath = "train_word_bag/tfdifspace.dat"
train_set = _readbunchobj(trainpath)
# 匯入測試集
testpath = "test_word_bag/testspace.dat"
test_set = _readbunchobj(testpath)
# 訓練分類器:輸入詞袋向量和分類標籤,alpha:0.001 alpha越小,迭代次數越多,精度越高
clf = MultinomialNB(alpha=0.001).fit(train_set.tdm, train_set.label)
# 預測分類結果
predicted = clf.predict(test_set.tdm)
for flabel,file_name,expct_cate in zip(test_set.label,test_set.filenames,predicted):
if flabel != expct_cate:
print file_name,": 實際類別:",flabel," -->預測類別:",expct_cate
print "預測完畢!!!"
# 計算分類精度:
from sklearn import metrics
def metrics_result(actual, predict):
print '精度:{0:.3f}'.format(metrics.precision_score(actual, predict,average='weighted'))
print '召回:{0:0.3f}'.format(metrics.recall_score(actual, predict,average='weighted'))
print 'f1-score:{0:.3f}'.format(metrics.f1_score(actual, predict,average='weighted'))
metrics_result(test_set.label, predicted)效果圖:
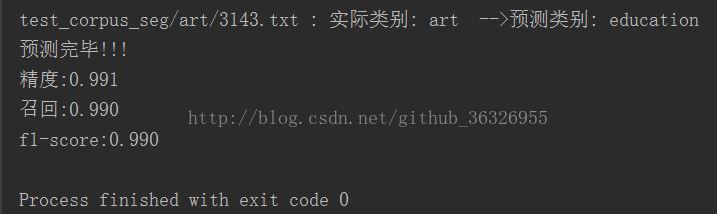
請注意,上面的截圖中的結果,未必會跟你的一樣。我之所以有這麼高的準確率,一方面是把每個資料集做了精簡的處理。另一方面是除錯了TF-IDF的閾值。
當然,你也可以採用其他分類器,比如KNN
6,評價與小結
評價部分的實際操作我們已經在上一節的程式碼中給出了。這裡主要是要解釋一下程式碼的含義,以及相關的一些概念。
截止目前,我們已經完成了全部的實踐工作。接下來,你或許希望做的是:
1,分詞工具和分詞演算法的研究
2,文字分類演算法的研究
這些內容,博主會在今後的時間裡,專門研究並寫出博文。
整個工程的完整原始碼到這裡下載:
需要說明的是,在工程程式碼和本篇博文中,細心的你已經發現了,我們所有的路徑前面都有一個點“. /”,這主要是因為我們不知道您會將工程建在哪個路徑內,因此這個表示的是你所在專案的目錄,本篇博文所有路徑都是相對路徑。github程式碼有兩個分支分別是master和python2.7分支。
三,進一步的討論
我們的這些工作究竟實不實用?這是很多人關心的問題。事實上,本博文的做法,是最經典的文字分類思想。也是你進一步深入研究文字分類的基礎。在實際工作中,用本文的方法,已經足夠勝任各種情況了。 那麼,我們也許想問,有沒有更好,更新的技術?答案是有的。未來,博主會集中介紹兩種技術: 1.利用LDA模型進行文字分類 2.利用深度學習進行文字分類 利用深度學習進行文字分類,要求你必須對深度學習的理論有足夠多的掌握。 為此,你可以參考博主的其他博文, 這是一些列的博文。與網上其他介紹CNN的博文不同的是:- 我們會全方位,足夠深入的為你講解CNN的知識。包括很多,你之前在網上找了很多資料也沒搞清楚的東西。
- 我們會利用CNN做文字分類的實踐。
- 我們會繪製大量精美的示意圖。保證博文的高質量和美觀。

Welcome to my blog column:

I devote myself to dive into typical algorithms on machine learning and deep learning, especially the application in the area of computational personality.
My research interests include computational personality, user portrait, online social network, computational society, and ML/DL. In fact you can find the internal connection between these concepts:
In this blog column, I will introduce some typical algorithms about machine learning and deep learning used in OSNs(Online Social Networks), which means we will include NLP, networks community, information diffusion,and individual recommendation system. Apparently, our ultimate target is to dive into user portrait , especially the issues on your personality analysis.
All essays are created by myself, and copyright will be reserved by me. You can use them for non-commercical intention and if you are so kind to donate me, you can scan the QR code below. All donation will be used to the library of charity for children in Lhasa.
手機掃一掃,即可: