
Elasticsearch ansj的停用詞設定
1. 配置方法
1.1 修改elasticsearch.yml配置檔案:
- 開啟啟用停用詞開關
enabled_stop_filter: true ##是否基於詞典過濾
- 配置停用詞檔案路徑: 注意這裡必須是相對於 elasticsearch.yml配置檔案 位置的 相對路徑。
stop_path: "../dic_stop/stop.dic" ##停止過濾詞典
1.2 放置停用詞檔案。我們這裡新增兩個停用詞。每行寫一個停用詞。
2. 重啟ES,測試
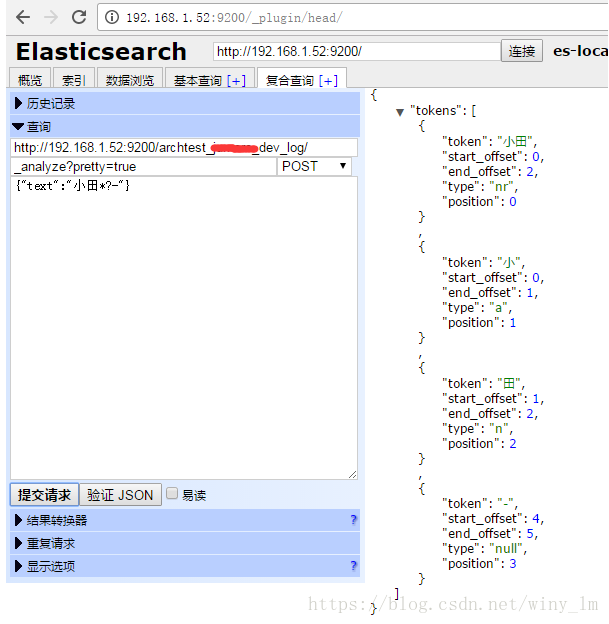
重啟ES後,在ES上測試停用詞效果。
POST提交:
http://192.168.1.52:9200/archtest_test_dev_log/
_analyze?pretty=true
{"text":"小田*?-"}
可以看到 * 和 ? 都被過濾掉了。
相關推薦
Elasticsearch ansj的停用詞設定
1. 配置方法 1.1 修改elasticsearch.yml配置檔案: - 開啟啟用停用詞開關 enabled_stop_filter: true ##是否基於詞典過濾 - 配置停用詞檔案路徑: 注意這裡必須是相對於 elasticsearch.yml配置檔案 位置
Elasticsearch的停用詞(stopwords)
query tle IT cut 情況下 要求 true 可能 利用 1、問題 在使用搜索引擎(Elasticsearch或Solr)作為應用的後臺搜索平臺的時候,會遇到停用詞(stopwords)的問題。 在信息檢索中,停用詞是為節省存儲空間和提高搜索效率,處理文本時自動
es中的停用詞
其他 搜索 last 高頻 包含 代碼 標簽 score 大小 停用詞主要是為了提升性能與精度。從早期的信息檢索到如今,我們已習慣於磁盤空間和內存被限制為很小一部分,所以 必須使你的索引盡可能小。 每個字節都意味著巨大的性能提升。 詞幹提取的重要性不僅是因為它讓搜索的內容更
python使用jieba實現中文文檔分詞和去停用詞
分享圖片 lac lena idt center cut inpu span code 分詞工具的選擇: 現在對於中文分詞,分詞工具有很多種,比如說:jieba分詞、thulac、SnowNLP等。在這篇文檔中,筆者使用的jieba分詞,並且基於python3環境,選擇
利用java實現對文字的去除停用詞以及分詞處理
功能: 對txt文件進行分詞處理,並去除停用詞。 工具: IDEA,java,hankcs.hanlp.seg.common.Term等庫。 程式: import java.util.*; import java.io.*; import java.lang.String; imp
停用詞+自定義詞
import jieba.posseg#方式一:#載入停用詞表stop = [line.strip() for line in open('stop.txt','r',encoding='utf-8').readlines() ]#匯入自定義詞典:詞語、詞頻(可省略)、詞性(可省略)jieba.load_us
Python自然語言處理—停用詞詞典
一 過濾文字 去除停用詞典和錯詞檢錯都可以用詞典的形式完成,以停用詞為例,我使用的應該是知網提供的中文停用詞典。測試的資料集是小學生數學題。 print(text) # 列印未去除停用詞前版本 with open(r"C:\Users\BF\Desktop\NLTK\stopwords.
改進的中科院分詞系統NLPIR程式碼(加入使用者詞典,去停用詞,檔案讀寫)+情感分析字典包+工具包+論文包
NLPIR分詞,加入使用者詞典,去停用詞,檔案讀寫等 原始碼下載地址 優化的分詞系統程式碼 原始碼下載地址 NLPIR分詞系統 優化的分詞系統程式碼 以下是核心程式碼 完整程式碼可以直接執行分詞,點我跳轉 public cl
pyhanlp 停用詞與使用者自定義詞典功能詳解
hanlp的詞典模式 之前我們看了hanlp的詞性標註,現在我們就要使用自定義詞典與停用詞功能了,首先關於HanLP的詞性標註方式具體請看HanLP詞性標註集。 其核心詞典形式如下: 自定義詞典 自定義詞典有多種新增模式,首先是展示的一個小例子,展示了詞彙的動態增加與強行插入,
郵件分詞去掉停用詞
!pip install nltk #讀取檔案 text = 'Be assured that individual statistics are not disclosed and this is for internal use only..I am pleased to infor
php 去除常見中文停用詞(過濾敏感詞)
在用sphinx通過文章標題匹配相關文章時,去除停用詞後調出的文章相關性更好。 <?php header("Content-type:text/html;charset=utf-8"); $str = file_get_contents('stop.txt');//將常見中文停用詞表內容讀入
中英文停用詞(stop word)列表
停用詞即我們在處理文字時出現頻率比較高,但是沒有統計意義的詞。一般在處理統計性文字資訊時,我們會選擇過濾掉這些詞,比如用TF-IDF抽取關鍵詞或者摘要,或者計算文件相識度的時候。當然進行文件語音及語法分析的時候,這些詞是不能隨便過濾掉的。蒐集了一下網上大家列的中英文停用詞以備之後使用。 英文停用
使用jieba分詞並去除停用詞流程程式
準備工作 ① 構建未分詞檔案、已分詞檔案兩個資料夾,將未分詞資料夾按類目定義檔名,各個類目的資料夾下可放置多個需要分詞的檔案。 ② 準備一份停用詞(jieba自身應該是沒有停用詞的) ③ 根據業務需要自定義詞典(此處使用jieba自帶字典) 分詞去停詞.py
英文過濾停用詞
""" Created on Sun Nov 13 09:14:13 2016 @author: daxiong """ from nltk.corpus import stopwords fr
【Python】中文分詞並過濾停用詞
中文分詞並過濾停用詞,python程式碼如下。 #coding=utf-8 import jieba input_path='../data/train_pos_100.txt' output_path='../data/train_pos_100_seg.txt' st
【java HanNLP】HanNLP 利用java實現對文字的去除停用詞以及分詞處理
HanNLP 功能很強大,利用它去停用詞,加入使用者自定義詞庫,中文分詞等,計算分詞後去重的個數、 maven pom.xml 匯入 <dependency> <groupId>com.hankcs</g
python 分詞、自定義詞表、停用詞、詞頻統計與權值(tfidf)、詞性標註與部分詞性刪除
# -*- coding: utf-8 -*- """ Created on Tue Apr 17 15:11:44 2018 @author: NAU """ ##############分詞、自定義詞表、停用詞################ import jieba
第二章:基於IK的智慧分詞、細粒度分詞、同義詞、停用詞
2. 將檔案放入solr.war的WEB-INF/lib下 3. 將IKAnalyzer.cfg.xml、ext.dic、stopword.dic放到WEB-INF/classes目錄下,注意:classes目錄沒有,需要手動建立 4. 配置同義詞與停用詞 <
停用詞stopWord
先看維基百科的解釋: In computing, stop words are words which are filtered out prior to, or after, processing of natural language data (text).Th
使用IKAnalyzer實現中文分詞&去除中文停用詞
1、簡介:IKAnalyzer是一個開源的,基於java語言開發的輕量級的中文分詞工具包。這裡使用的是IKAnalyzer2012。 2、IK Analyzer 2012特性: (1)採用了特有的“正向迭代最細粒度切分演算法“,支援細粒度和智慧分詞兩種切分模式; (2)在