
詳解CNN五大經典模型:Lenet,Alexnet,Googlenet,VGG,DRL
關於卷積神經網路CNN,網路和文獻中有非常多的資料,我在工作/研究中也用了好一段時間各種常見的model了,就想著簡單整理一下,以備查閱之需。
Lenet,1986年
Alexnet,2012年
GoogleNet,2014年
VGG,2014年
Deep Residual Learning,2015年
Lenet
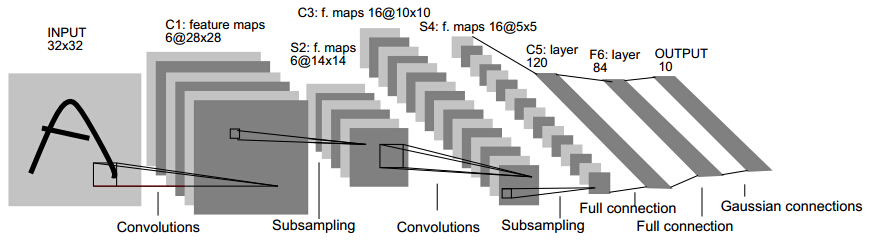
就從Lenet說起,可以看下caffe中lenet的配置檔案(1),可以試著理解每一層的大小,和各種引數。由兩個卷積層,兩個池化層,以及兩個全連線層組成。 卷積都是5*5的模板,stride=1,池化都是MAX。下圖是一個類似的結構,可以幫助理解層次結構(和caffe不完全一致,不過基本上差不多)
(1)網址:https://github.com/BVLC/caffe/blob/master/examples/mnist/lenet_train_test.prototxt
Alexnet
2012年,Imagenet比賽冠軍的model——Alexnet [2](以第一作者alex命名)。caffe的model檔案在(2)。說實話,這個model的意義比後面那些model都大很多,首先它證明了CNN在複雜模型下的有效性,然後GPU實現使得訓練在可接受的時間範圍內得到結果,確實讓CNN和GPU都大火了一把,順便推動了有監督DL的發展。
(2)https://github.com/BVLC/caffe/blob/master/models/bvlc_alexnet/deploy.prototxt
模型結構見下圖,別看只有寥寥八層(不算input層),但是它有60M以上的引數總量,事實上在引數量上比後面的網路都大。
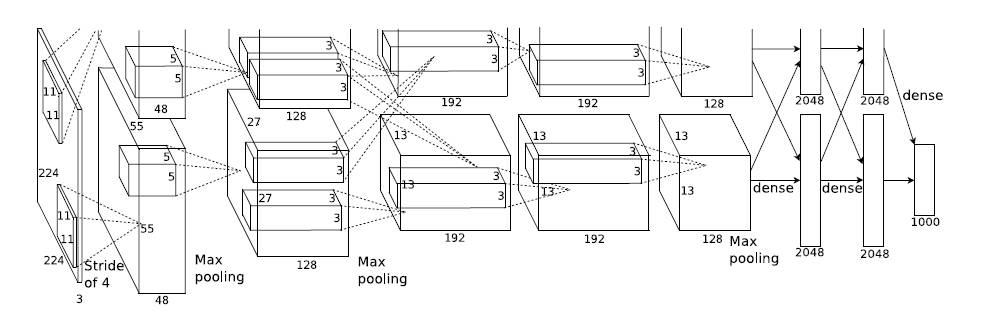
這個圖有點點特殊的地方是卷積部分都是畫成上下兩塊,意思是說吧這一層計算出來的feature map分開,但是前一層用到的資料要看連線的虛線,如圖中input層之後的第一層第二層之間的虛線是分開的,是說二層上面的128map是由一層上面的48map計算的,下面同理;而第三層前面的虛線是完全交叉的,就是說每一個192map都是由前面的128+128=256map同時計算得到的。
Alexnet有一個特殊的計算層,LRN層,做的事是對當前層的輸出結果做平滑處理。下面是我畫的示意圖:
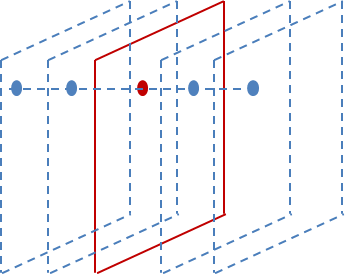
前後幾層(對應位置的點)對中間這一層做一下平滑約束,計算方法是:

具體開啟Alexnet的每一階段(含一次卷積主要計算)來看[2][3]:
(1)con - relu - pooling - LRN
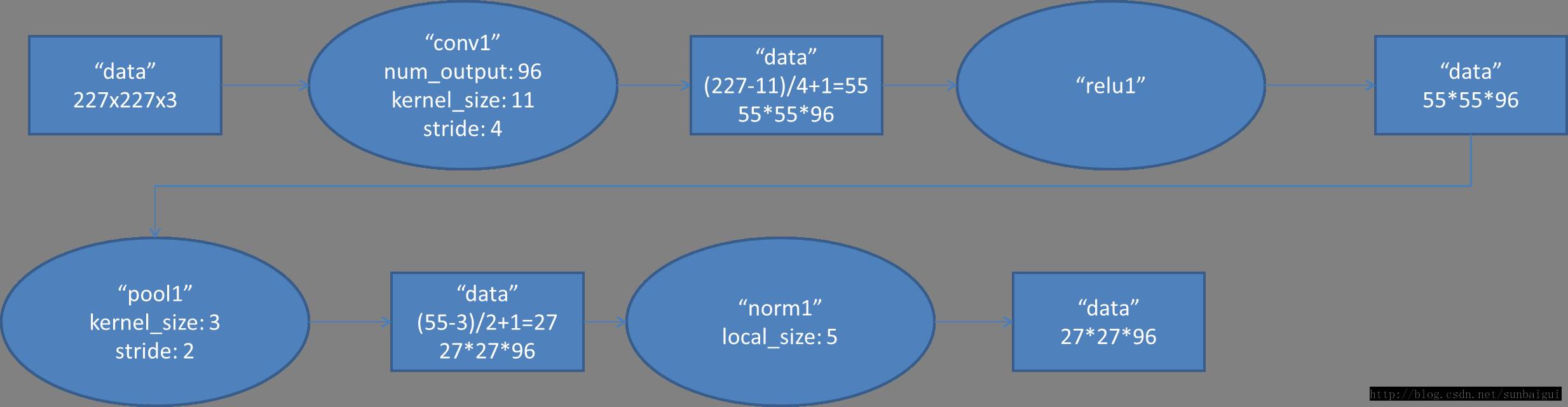
具體計算都在圖裡面寫了,要注意的是input層是227*227,而不是paper裡面的224*224,這裡可以算一下,主要是227可以整除後面的conv1計算,224不整除。如果一定要用224可以通過自動補邊實現,不過在input就補邊感覺沒有意義,補得也是0。
(2)conv - relu - pool - LRN
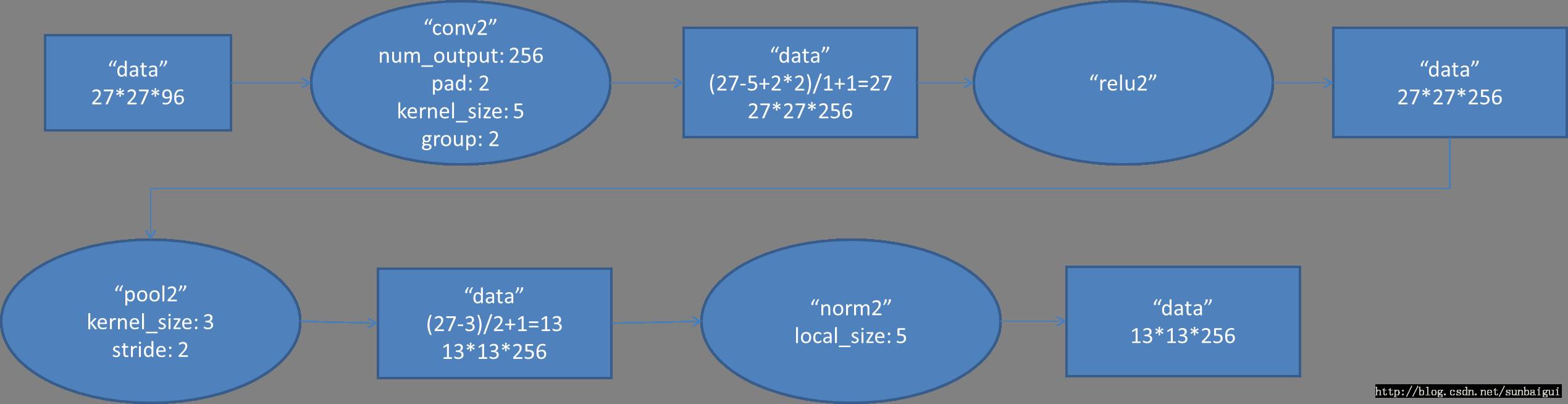
和上面基本一樣,唯獨需要注意的是group=2,這個屬性強行把前面結果的feature map分開,卷積部分分成兩部分做。
(3)conv - relu

(4)conv-relu

(5)conv - relu - pool

(6)fc - relu - dropout
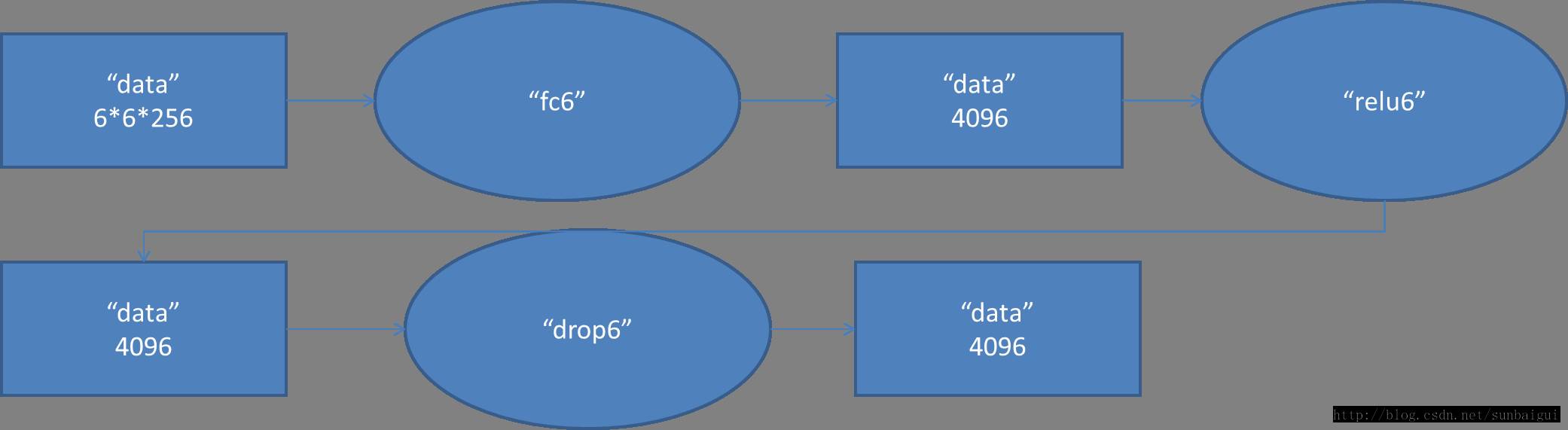
這裡有一層特殊的dropout層,在alexnet中是說在訓練的以1/2概率使得隱藏層的某些neuron的輸出為0,這樣就丟到了一半節點的輸出,BP的時候也不更新這些節點。
(7) fc - relu - dropout
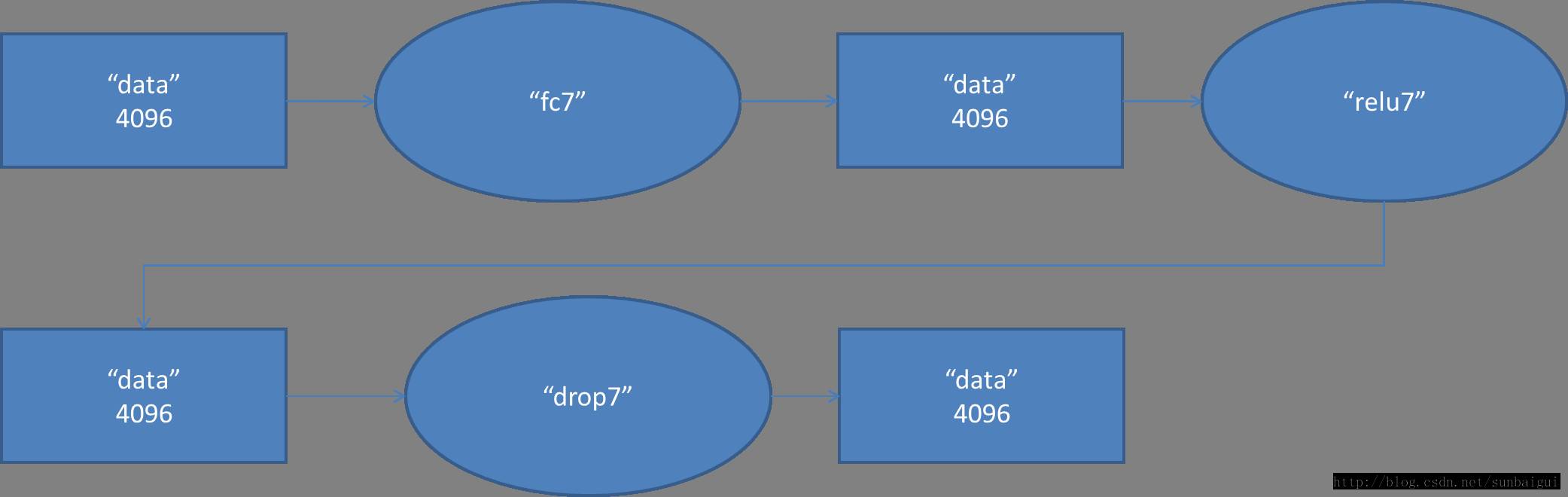
(8)fc - softmax

以上圖借用[3],感謝。
GoogleNet
googlenet[4][5],14年比賽冠軍的model,這個model證明了一件事:用更多的卷積,更深的層次可以得到更好的結構。(當然,它並沒有證明淺的層次不能達到這樣的效果)
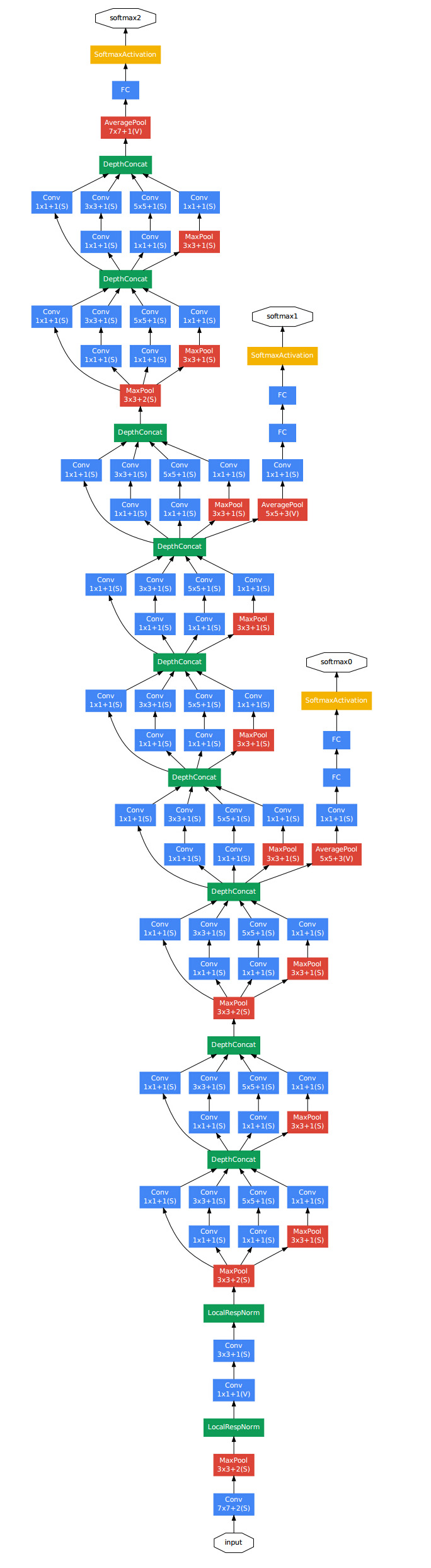
這個model基本上構成部件和alexnet差不多,不過中間有好幾個inception的結構:

是說一分四,然後做一些不同大小的卷積,之後再堆疊feature map。
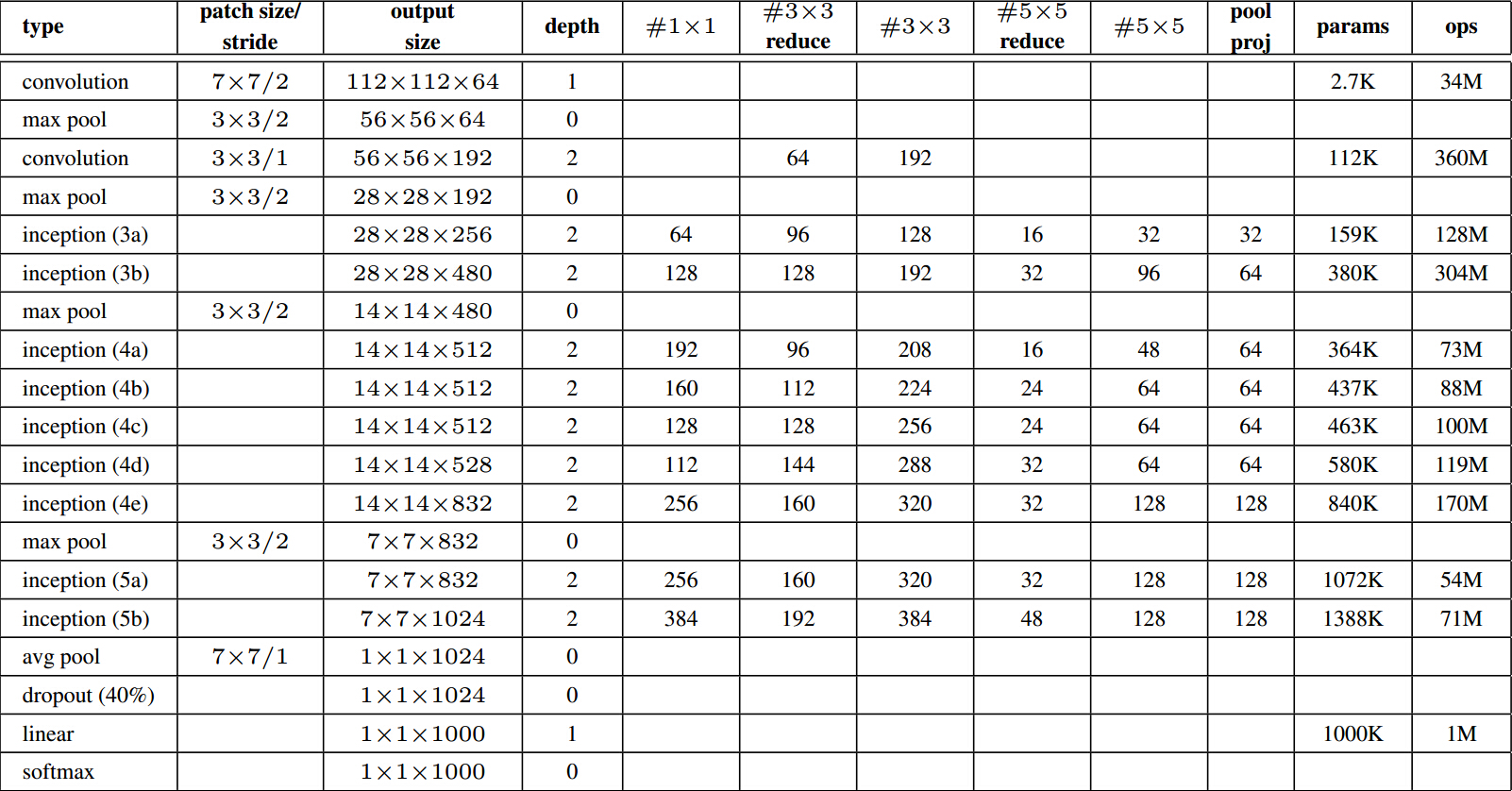
計算量如下圖,可以看到引數總量並不大,但是計算次數是非常大的。
VGG
VGG有很多個版本,也算是比較穩定和經典的model。它的特點也是連續conv多,計算量巨大(比前面幾個都大很多)。具體的model結構可以參考[6],這裡給一個簡圖。基本上組成構建就是前面alexnet用到的。
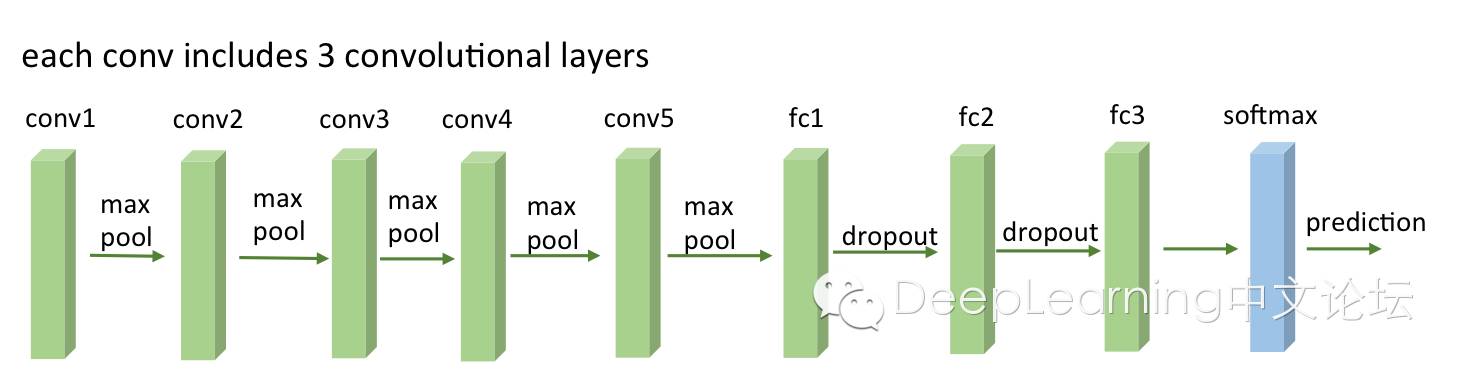
下面是幾個model的具體結構,可以查閱,很容易看懂。

Deep Residual Learning
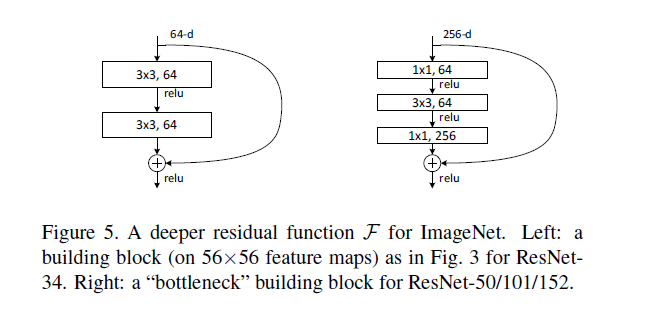
這個model是2015年底最新給出的,也是15年的imagenet比賽冠軍。可以說是進一步將conv進行到底,其特殊之處在於設計了“bottleneck”形式的block(有跨越幾層的直連)。最深的model採用的152層!!下面是一個34層的例子,更深的model見表格。

其實這個model構成上更加簡單,連LRN這樣的layer都沒有了。

block的構成見下圖:
總結
OK,到這裡把常見的最新的幾個model都介紹完了,可以看到,目前cnn model的設計思路基本上朝著深度的網路以及更多的卷積計算方向發展。雖然有點暴力,但是效果上確實是提升了。當然,我認為以後會出現更優秀的model,方向應該不是更深,而是簡化。是時候動一動卷積計算的形式了。