Flume的多層代理和防止資料丟失
當我們用Flume採集日誌時,由於資料來源的多樣性,則往往需要配置多個Flume進行採集,如果只是使用單層Flume的話,那麼往往會產生很多個資料夾,單個資料夾也只是來自同一個節點的資料組成的。而實際開發中,為了減少HDFS的壓力,同時提高後續MR的處理效率。往往會將同一組多個節點的資料匯聚到同一個檔案中,這樣同時也較少了資料從生產到分析的時間。
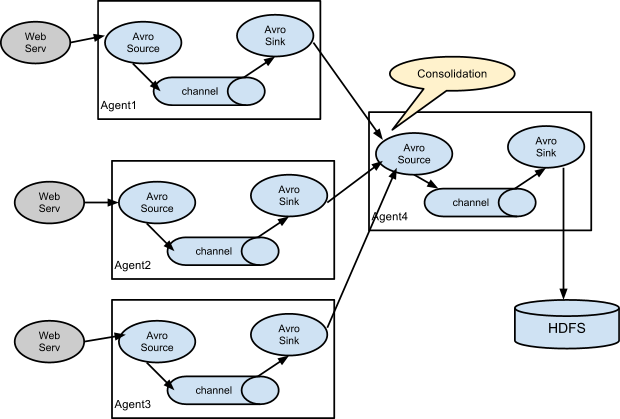
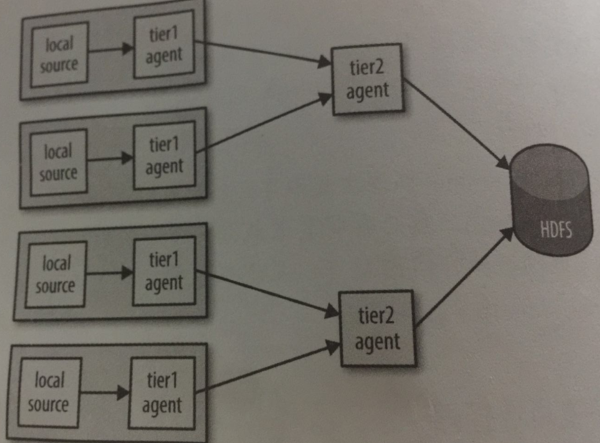
如下圖,第一次agent負責採集原始資料,第二層agent負責對第一層資料進行匯聚。這種多層代理的方式尤其適合source源資料量龐大的時候,效率會高很多。
注意:1.如果要構建分層的代理結構,必然牽扯到資料的網路傳輸和分發問題。所以第一層代理需要某種特殊的sink來進行網路傳送事件,再加上相應的source來接受這些事件。Avro sink 通過Avro RPC將事件傳送給執行在另一個Flume代理上的其他Avro
2.如果第二層的agent停止執行,那麼事件將被儲存到第一層agent的channel中,等到第二層agent的重新啟動。但是channel的儲存是由限制的,如果第一層agent的channel已經填滿資料時,第二層agent還沒啟動恢復執行,那麼任何新採集的事件都會丟失。預設情況下,file channel能夠恢復的事件數量不超過100萬條(可以通過capacity屬性來設定,實際要設定的大一些),此外,當檢查點checkpointdir的可用磁碟空間小於500M時(minimumRequiredSpace屬性設定
3.不管第一層某個代理還是第二層某個代理一旦有停止執行或者失敗的情況出現,都會出現Flume丟失資料的情況發生。這也是常見開發中,或者面試中常問的Flume資料丟失問題,如果防止丟失?對於這個問題如果是第一層某個代理失敗,那麼可以考慮由第一層的其他節點來接管故障節點。如果是第二層代理停止執行,則為了防止資料丟失,只能讓每一個第一層代理具有多個冗餘的Avro sink,然後把這些sink安排到同一個sink組中,如果第二層代理中的某個代理出現問題,則該事件會被傳遞給該層sink組的其他代理來完成,以此來實現故障轉移和負載均衡。下面部落格繼續sink組的實現。
案例演示多層代理的實現: