
特徵選擇 python實踐
阿新 • • 發佈:2019-01-03
下面介紹兩種之前競賽使用到的特徵選擇方案
方案一
- 流程圖
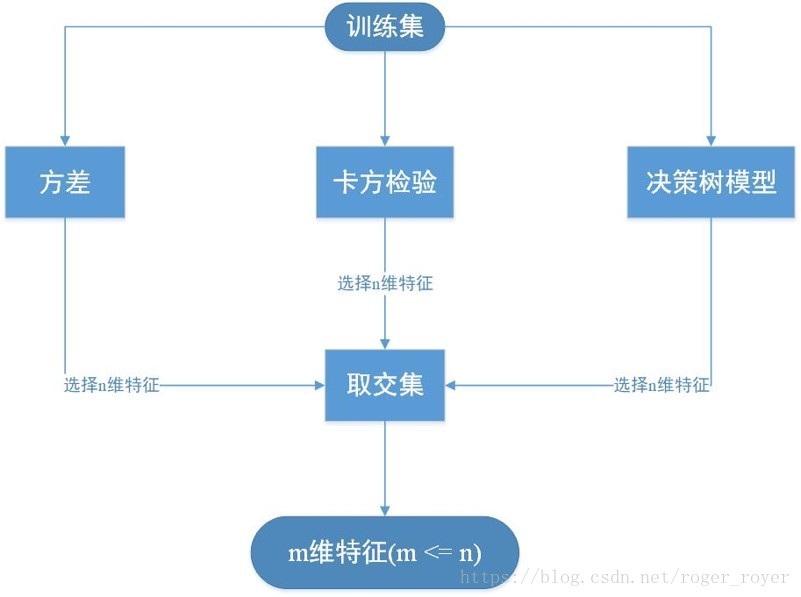
以上方法使用方差、卡方檢驗、決策樹模型輸出特徵重要性方法綜合起來進行特徵選擇,該方案在馬上AI全球挑戰賽中發揮了比較大的作用。該連結是我們的解決方案,開源是一種精神,僅供大家共同學習交流。
- python程式碼實現
#coding=utf-8
import numpy as np
import pandas as pd
'''單變數特徵選取'''
from sklearn.feature_selection import SelectKBest, chi2
'''去除方差小的特徵'''
from sklearn.feature_selection import 由於使用SVC方法速度太慢,我就沒有使用它
方案二
方案二是使用遺傳演算法做特徵選擇,演算法原理我就不多闡述了,可以見我另一篇博文,雖然是用遺傳演算法解決Tsp問題,但除了編碼方式不一樣外其它幾乎差不多。
End:如有不當之處,還望不吝賜教