
[Python人工智慧] 六.神經網路的評價指標、特徵標準化和特徵選擇
從本系列文章開始,作者正式開始研究Python深度學習、神經網路及人工智慧相關知識。前五篇文章講解了神經網路基礎概念、Theano庫的安裝過程及基礎用法、theano實現迴歸神經網路、theano實現分類神經網路、theano正規化處理,這篇文章講解神經網路的評價指標、特徵標準化和特徵選擇,均是基礎性知識。主要是學習"莫煩大神" 網易雲視訊的線上筆記,後面隨著深入會講解具體的專案及應用。基礎性文章和線上筆記,希望對您有所幫助,本系列作者採用一篇基礎一篇程式碼的形式講解,也建議大家一步步跟著學習,同時文章中存在錯誤或不足之處,還請海涵~
"莫煩大神" 網易雲視訊地址:http://study.163.com/provider/1111519/course.html
從2014年開始,作者主要寫了三個Python系列文章,分別是基礎知識、網路爬蟲和資料分析。


一. 神經網路評價指標
由於各種問題影響,會導致神經網路的學習效率不高,或者干擾因素太多導致分析結果不理想。這些因素可能是資料問題,學習引數問題等。這就涉及到了神經網路評價指標。
如何評價(Evaluate)神經網路呢?我們可以通過一些指標對神經網路進行評價,通過評價來改進我們的神經網路。評價神經網路的方法和評價機器學習的方法大同小異,常見的包括誤差、準確率、R2 score等。

資料分析通常會將資料集劃分為訓練資料和預測資料,常見的如70%訓練集和30%測試集,或者80%訓練集和20%測試集。例如,我們讀書時包括作業題和考試題,雖然期末考試時間很少,但其得分比例要高於平時作業。
1.誤差(Error)
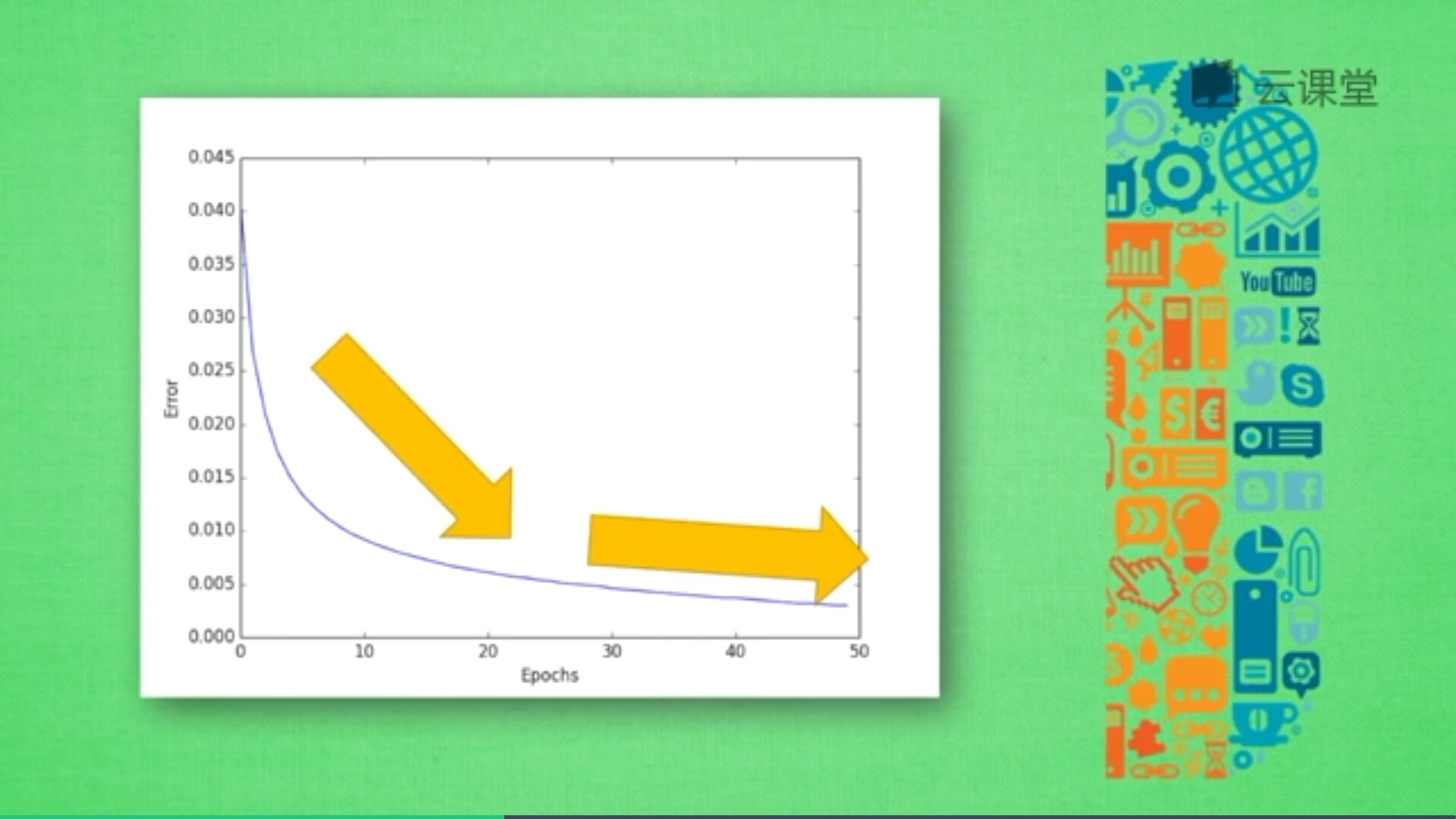
先用誤差評價神經網路,如下圖所示,隨著訓練時間增長,預測誤差會不斷減小,得到更為準確的答案,最後誤差會趨近於水平。
2.精準度(Accuracy)
精準度是指預測結果與真實結果的準確率,接近100%是最好的結果。例如,神經網路中分類問題,100個樣本中有90個分類正確,則其預測精準度為90%。通過可以使用精準度預測分類問題,那麼,如果是迴歸問題呢?如何評價連續值的精準度呢?我們使用R2 Score值來進行。

3.R2 Score
在評價迴歸模型時,sklearn中提供了四種評價尺度,分別為mean_squared_error、mean_absolute_error、explained_variance_score 和 r2_score。
參考:https://blog.csdn.net/Softdiamonds/article/details/80061191
(1) 均方差(mean_squared_error)
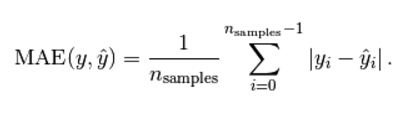
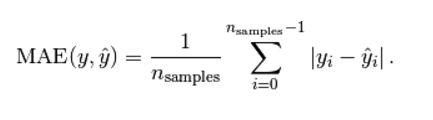
(2) 平均絕對值誤差(mean_absolute_error)
(3) 可釋方差得分(explained_variance_score)
Explained variation measures the proportion to which a mathematical model accounts for the variation (dispersion) of a given data set.
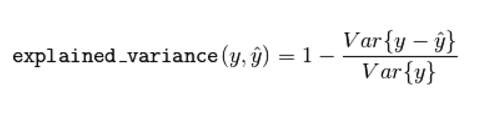
(4) 中值絕對誤差(Median absolute error)
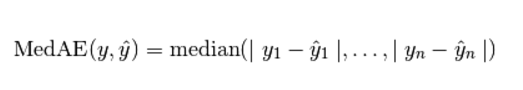
(5) R2 決定係數(擬合優度)
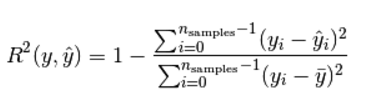
模型越好:r2→1,模型越差:r2→0。Sklearn程式碼呼叫如下:
from sklearn.metrics import r2_score
y_true = [1,2,4]
y_pred = [1.3,2.5,3.7]
r2_score(y_true,y_pred)
4.其他標準。
如F1 Score值,用於測量不均衡資料的精度。
過擬合問題:
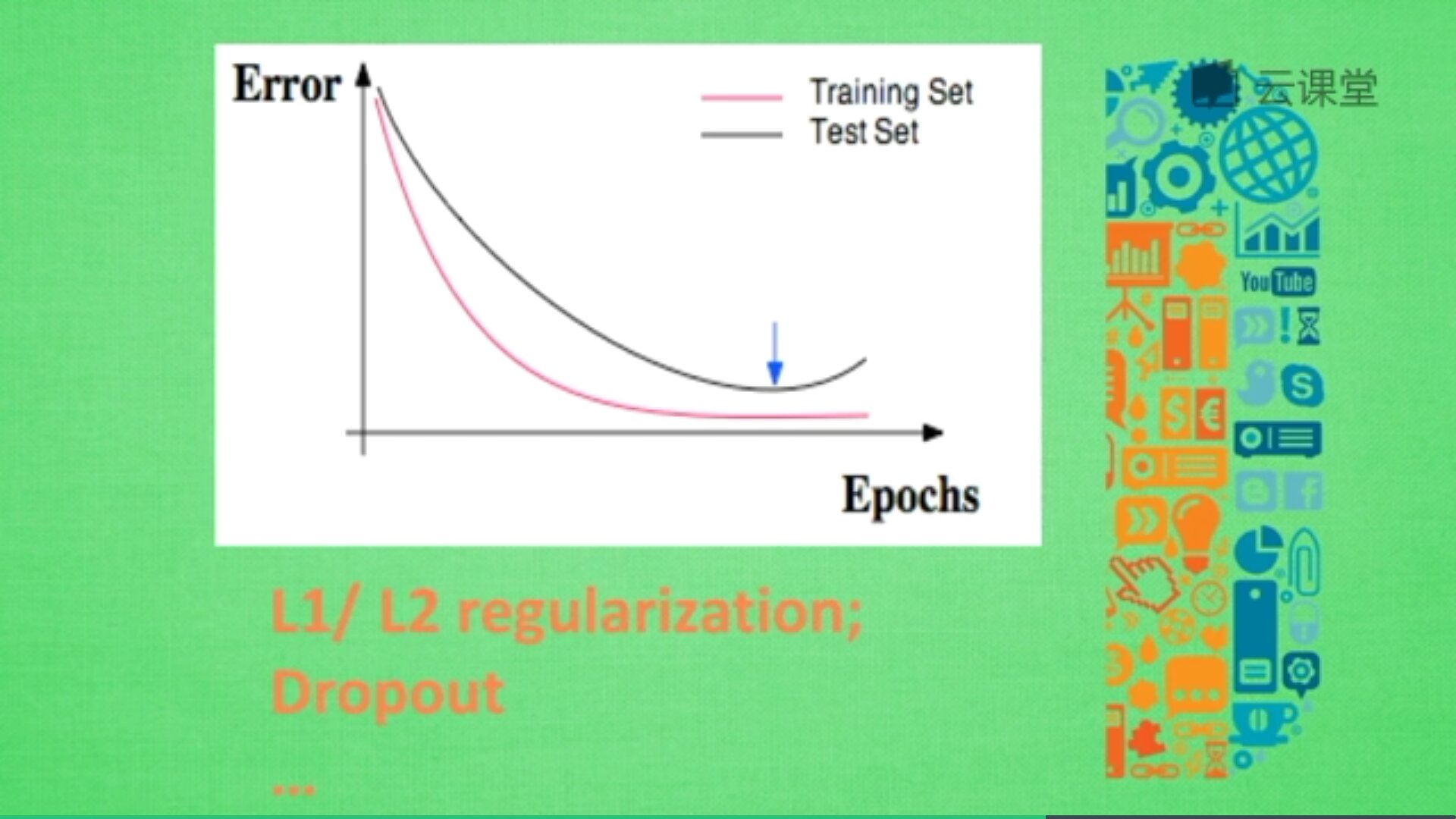
有時候意外猝不及防,作業題明明會做,但是考試卻不理想,因為我們只複習了作業題,而沒有深入拓展作業反映的知識。這樣的問題也會發生在機器學習中,我們稱為過擬合。簡言之,過擬合就是訓練樣本得到的輸出和期望輸出基本一致,但是測試樣本的輸出和測試樣本的期望輸出相差卻很大 。當某個模型過度的學習訓練資料中的細節和噪音,以至於模型在新的資料上表現很差,我們稱過擬合發生了。這意味著訓練資料中的噪音或者隨機波動也被當做概念被模型學習了。而問題就在於這些概念不適用於新的資料,從而導致模型泛化效能的變差。
下圖是經典的誤差曲線,紅色曲線為訓練誤差,黑色曲線為測試誤差,訓練誤差校友測試誤差,但由於過於依賴平時作業,考試成績不理想,沒把知識拓展開來。
交叉驗證:
神經網路中有很多引數,我們怎麼確定哪些引數更有效解決現有問題呢?這時候交叉驗證是最好的途徑。交叉驗證不僅可以用於神經網路調參,還可以用於其他機器學習的調參。例如:X軸為學習率(Learning rate)、神經網路層數(N-layers),Y軸為Error或精確度,不同神經層數對應的誤差值或精準度也不同。

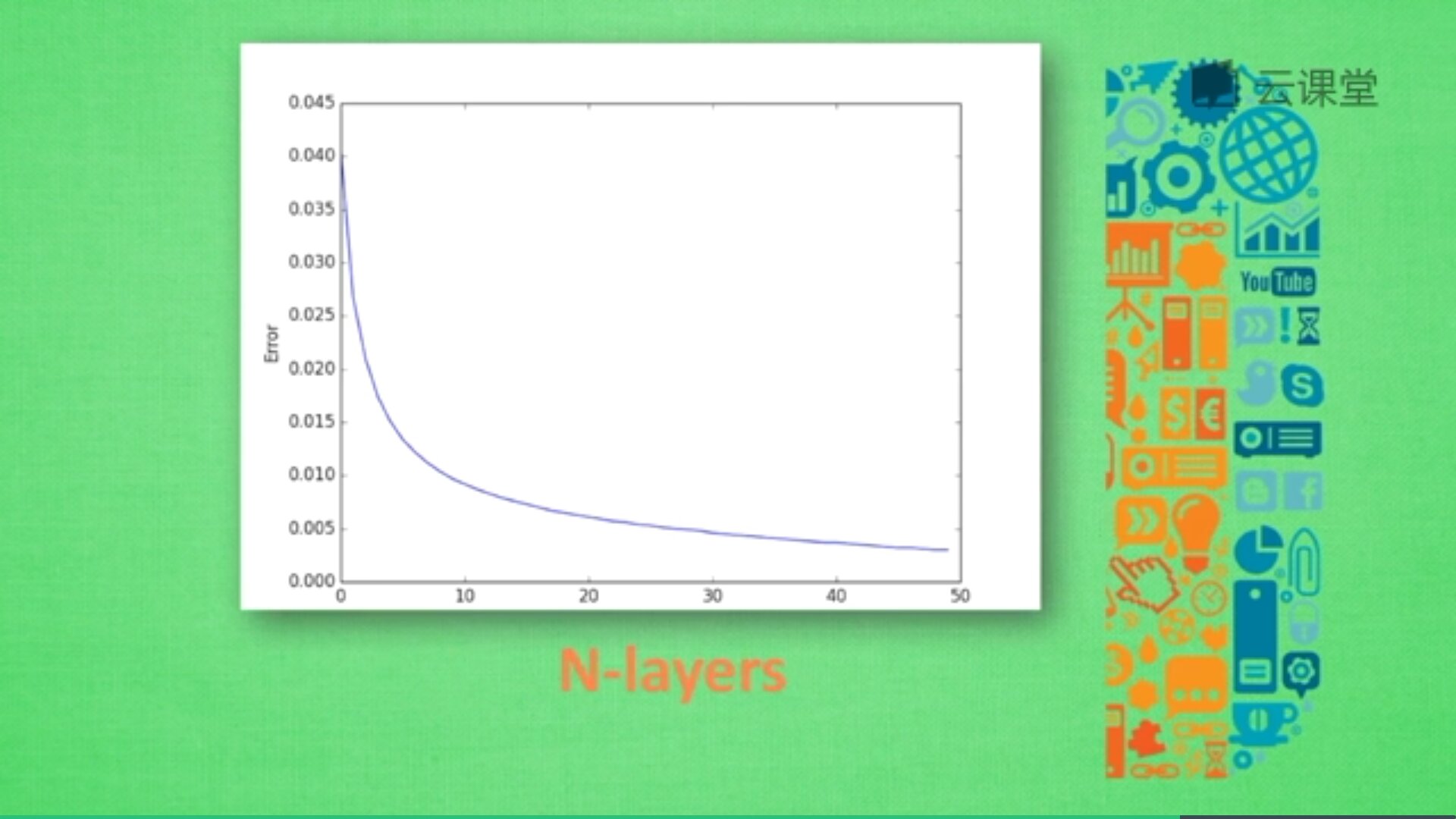
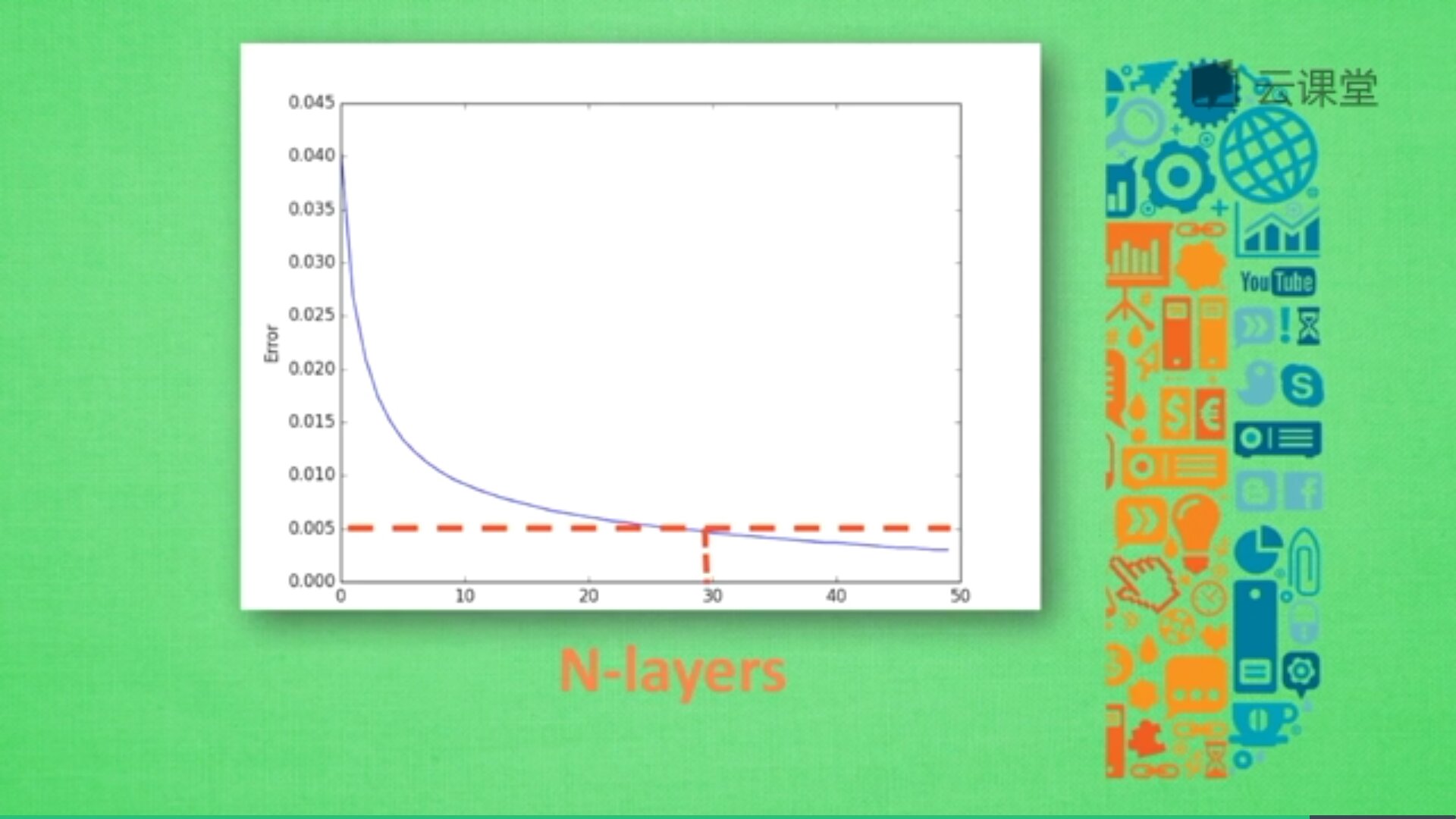
由於神經層數目越多,計算機消耗的時間也會增加,所以只需要找到滿足誤差要求又能節約時間的層結構即可。例如,當誤差在0.005以下時都能接收,則採用30層(N-layers=30)的結構即可。
二. 特徵標準化
特徵標準化(Feature Normalization)又稱為正常化或歸一化。為什麼需要進行特徵標準化呢?
為了讓機器學習更好地消化,我們需要對資料動些手腳,這就包括特徵標準化。現實中,資料來自不同的地方,有不同的規格,被不同人採集。比如房價預測資料,房屋特徵可能包括:離市中心距離、樓層數目、房屋面積、所在城市等。

假設用線性迴歸來做預測,方程可能為:價格 = a*離市中心 + b*樓層 + c*面積
機器學習要求出a、b、c,然後預測價格,其誤差定義為:誤差 = 預測值 - 實際價格

接著需要對誤差進行資料處理,使之變成進步的階梯,然後反向傳遞a、b、c,提升下一次的精確度。
那麼,這些概念和標準化又有什麼關係呢?
我們可以把 a、b、c 想象成三個人,他們共同努力解決一個問題。在該問題中,a工作時總是不知道發生了什麼,b的能力適中,c的能力最強。老闆看了以後,說你們的結果和我期望的還有些差距,你們快去縮小差距。老闆給出的要求是縮小差距,可是a、b、c不知道如何縮小差距,不知道差距在哪?他們只好平分任務,c很快就完成了,b要慢點,a最慢,但總時間很長,c、b需要等a把工作完成才給老闆看結果。

這樣的效率並不高,把這個問題放到機器學習中,怎麼解決呢?
為了方便理解,我們先把b去除掉,留下兩個特徵屬性,如下:價格 = a*離市中心 + c*面積
其中離市中心距離一般0-10取值,而面積一般100-300取值,在公式中,c只要稍微變化一點,它對價格的影響很大,而a變化對價格的影響不會像c那麼大,這樣的差別會影響最終的效率,所以我們需要進行特徵標準化處理,從而提升效率。

我們在機器學習之前,先對資料預先處理一下,對取值跨度大的資料濃縮一下,跨度小的資料擴充套件一下,使得他們的跨度儘量統一,通常有兩種方法:
1.minmax normalization
它們會將所有資料按照比例縮放到0到1之間,有的也可以是-1到1區間。
2.std normalization
它會將所有資料濃縮成平均值為0,方差為1的資料。
通過這些標準化手段,我們不僅能加快機器學習的學習速度,還可以避免機器學習學得特別扭曲。

minmax normalization標準化方法程式碼如下(參考前文):
#正常化處理 資料降為0-1之間
def minmax_normalization(data):
xs_max = np.max(data, axis=0)
xs_min = np.min(data, axis=0)
xs = (1-0) * (data - xs_min) / (xs_max - xs_min) + 0
return xs 三. 特徵選擇
這裡使用機器學習的分類器作為貫穿特徵選擇的例子,分類器只有你在提供好特徵時,才能發揮出最好效果,這也意味著找到好的特徵,才是機器學習能學好的重要前提。那麼,如何區分哪些是好的特徵(good feature)?你怎麼知道特徵是好還是壞呢?
我們在用特徵描述一個物體,比如A和B兩種物體中,包括兩個屬性長度和顏色。然後用這些屬性描述類別,好的特徵能夠讓我們更輕鬆的辨別出相應特徵所代表的類別,而不好的特徵會混亂我們的感官,帶來一些沒用的資訊,浪費計算資源。
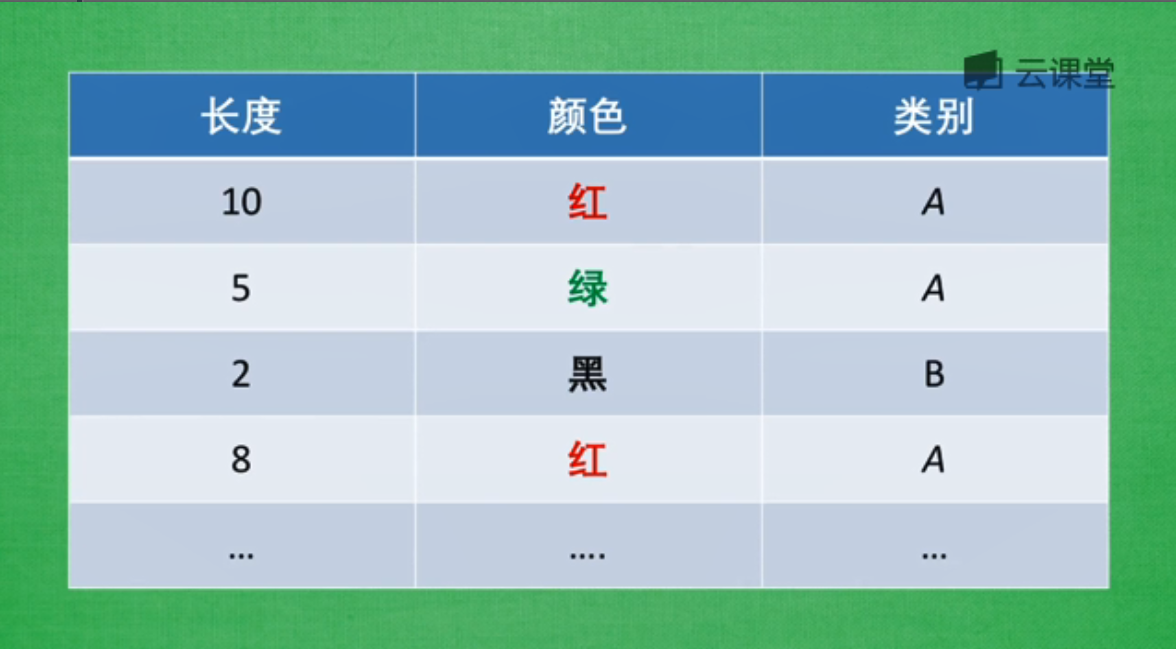
避免無意義的資訊:
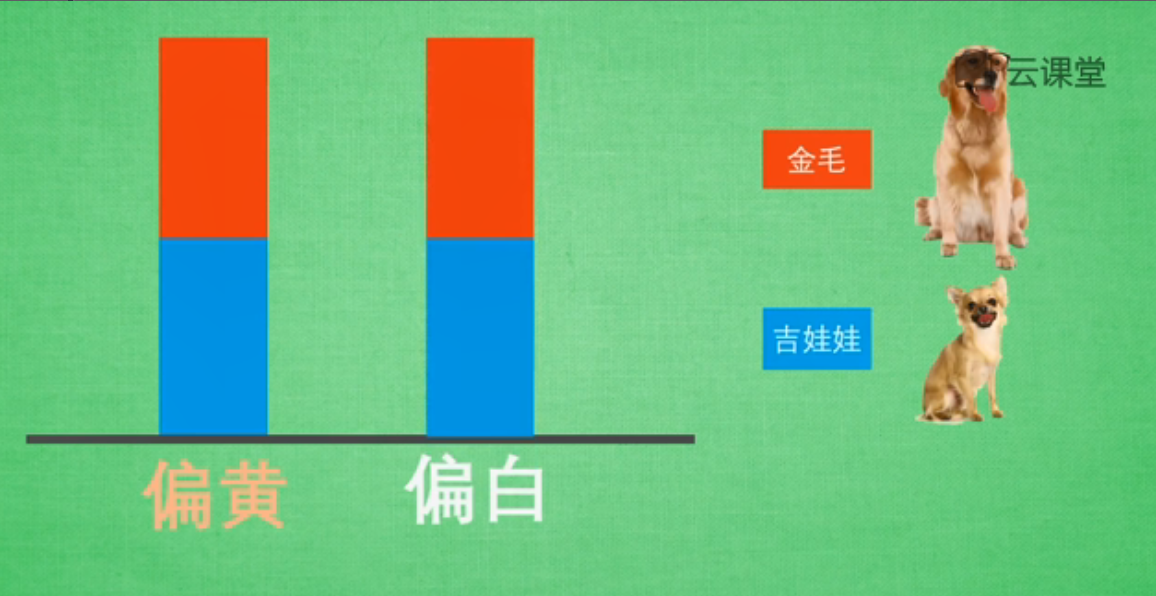
比如對比金毛和吉娃娃,它們有很多特徵可以對比,比如眼睛的顏色、毛色、體重、身高等,為了簡化我們的問題,我們主要觀察毛色和身高這兩個特徵,而且我們假設這兩種狗毛色僅為偏黃色或偏白色。接著我們來對比毛色,結果發現金毛和吉娃娃兩種顏色的比例各佔一半。


然後我們將它們用資料形式展現出來,假設只有兩種顏色(偏黃、偏白),用紅色表示金毛,藍色表示吉娃娃,兩種狗所佔比例各為一半。該資料說明:給你一隻毛色偏黃的特徵,你是無法判斷這隻狗是金毛還是吉娃娃的,這就意味著通過毛色判斷兩種狗的品種是不恰當的,這個特徵在區分品種上沒有起到作用,我們要避免這種無意義的特徵資訊。
接下來我們嘗試用身高來進行分類,使用Python視覺化來進行實驗。
----------------------------------------------------------------------------------
import matplotlib.pyplot as plt
import numpy as np
#定義400個樣本
gold, chihh = 400, 400
#平均身高假設為40釐米加上一個隨機數,金毛隨機幅度稍微大些,吉娃娃小些
gold_height = 40 + 10 * np.random.randn(gold)
chihh_height = 25 + 6 * np.random.randn(gold)
#柱狀圖視覺化顯示這些高度資料,紅色金毛高度個數,藍色代表吉娃娃
plt.hist([gold_height, chihh_height], stacked=True, color=['r', 'b'])
plt.show()
----------------------------------------------------------------------------------
如下圖所示,高度為50的紅色這組資料中,基本上判斷這隻狗就是金毛,同樣高度大於50的也是金毛;而當資料為20時,我們能夠說它很可能就是吉娃娃;而高度為30的範圍,我們很難判斷它是金毛還是吉娃娃,因為兩種狗都存在而且數量差別不大。
所以,雖然高度是一個非常有用的特徵,但並不完美,這就需要我們引入更多的特徵來判斷機器學習中的問題。

如果要收集更多的資訊,我們就要剔除那些沒有意義或不能區分資訊的特徵,比如毛色,而高度比較有用,保留該特徵;同時需要尋找更多的特徵來彌補高度的不足,比如體重、跑步速度、耳朵形狀等,用這些加起來的資訊我們就能彌補單一特徵所缺失的資訊量。
 避免重複性特徵:
避免重複性特徵:有時候,我們會有很多特徵資訊資料,而有些特徵雖然名字不同,但描述的意義卻相似,比如描述距離的公里和裡兩種單位,雖然它們在數值上並不重複,但都表示同一個意思。在機器學習中,特徵越多越好,但是把這兩種資訊都放入機器學習中,它並沒有更多的幫助。

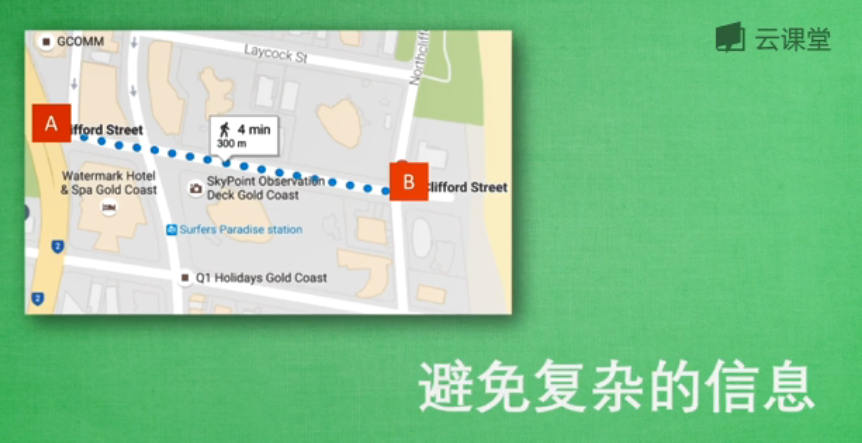
避免複雜性特徵:
同樣在這張圖片中,如果從A到B,有兩種方式可供選擇,一種是經緯度,另一種是AB之間的距離。雖然都屬於地理為止資訊,但是處理經緯度會比計算距離麻煩很多,所以我們在挑選特徵時,會增加一條:避免複雜的特徵。因為特徵與結果之間的關係越簡單,機器學習就能夠更快地學習到東西,所以選擇特徵時,需要注意這三點:避免無意義的資訊、避免重複性的資訊、避免複雜的資訊。
一個人如果總是自己說自己厲害,那麼他就已經再走下坡路了,最近很浮躁,少發點朋友圈和說說吧,更需要不忘初心,砥礪前行。珍惜每一段學習時光,也享受公交車的視訊學習之路,加油,最近興起的傲嬌和看重基金之心快離去吧,平常心才是更美,當然娜最美,早安。
(By:Eastmount 2018-06-12 深夜1點http://blog.csdn.net/eastmount/)