李鬼989的專欄
阿新 • • 發佈:2019-01-03
這是原始的sql
select COUNT(1)
from veh_passrec ve
where ve.hphm = '湘E4TT52'
and ve.gcsj > to_date('2016-06-12 17:16', 'yyyy-mm-dd hh24:mi:ss')
and ve.GCSJ < to_date('2016-06-13 17:16', 'yyyy-mm-dd hh24:mi:ss')
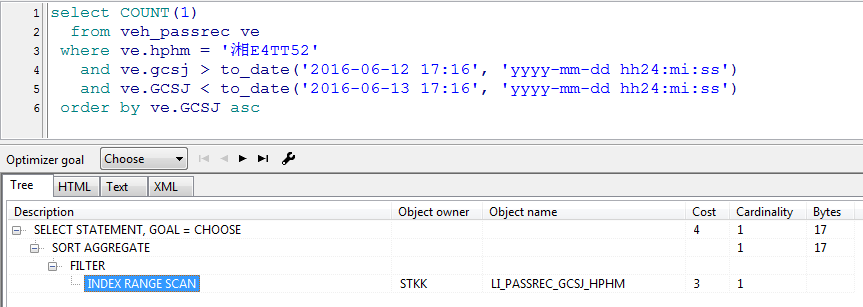
order by ve.GCSJ asc;查詢時快時慢,我們藉助pl/sql來看看它的執行計劃:可以看到,當優化目標為rule時,它是進行的全表掃描

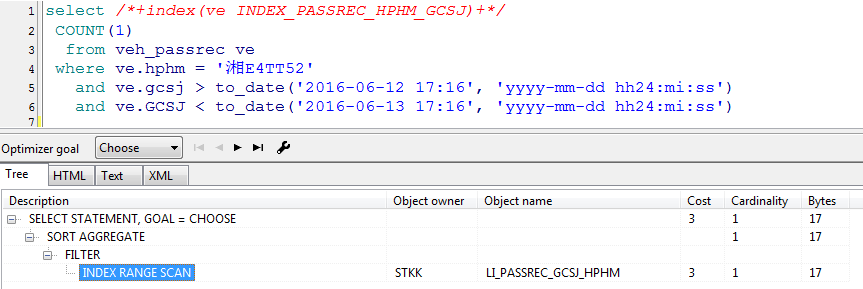
當優化目標為choose時,它是走的索引
實際是,當我們沒有指定索引時,資料庫會按照自己認為的最優化的方式去執行.
接下來,我們將這條sql優化一下,給它指定索引,在統計個數時,是可以把排序去掉的,而且統計個數時最好不要多表關聯查詢.優化之後就是這樣子的了
select /*+index(ve INDEX_PASSREC_HPHM_GCSJ)+*/ COUNT(1) from veh_passrec ve where ve.hphm = '湘E4TT52' and ve.gcsj > to_date('2016-06-12 17:16', 'yyyy-mm-dd hh24:mi:ss') and ve.GCSJ < to_date('2016-06-13 17:16', 'yyyy-mm-dd hh24:mi:ss')
我們再來看看它的執行計劃,當選擇rule時
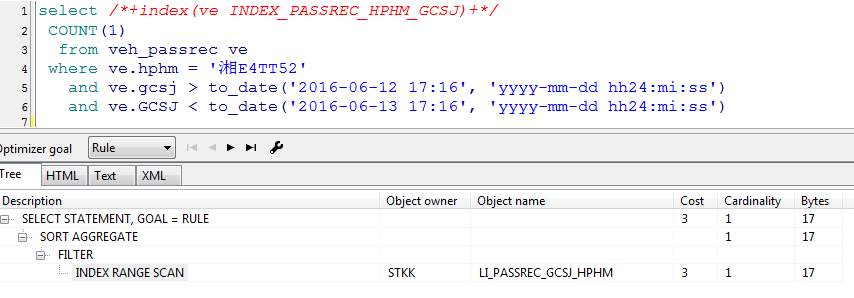
當選擇choose時